218 posts tagged “llm-release”
New releases of various LLMs.
2025
Introducing SWE-1.5: Our Fast Agent Model (via) Here's the second fast coding model released by a coding agent IDE in the same day - the first was Composer-1 by Cursor. This time it's Windsurf releasing SWE-1.5:
Today we’re releasing SWE-1.5, the latest in our family of models optimized for software engineering. It is a frontier-size model with hundreds of billions of parameters that achieves near-SOTA coding performance. It also sets a new standard for speed: we partnered with Cerebras to serve it at up to 950 tok/s – 6x faster than Haiku 4.5 and 13x faster than Sonnet 4.5.
Like Composer-1 it's only available via their editor, no separate API yet. Also like Composer-1 they don't appear willing to share details of the "leading open-source base model" they based their new model on.
I asked it to generate an SVG of a pelican riding a bicycle and got this:

This one felt really fast. Partnering with Cerebras for inference is a very smart move.
They share a lot of details about their training process in the post:
SWE-1.5 is trained on our state-of-the-art cluster of thousands of GB200 NVL72 chips. We believe SWE-1.5 may be the first public production model trained on the new GB200 generation. [...]
Our RL rollouts require high-fidelity environments with code execution and even web browsing. To achieve this, we leveraged our VM hypervisor
otterlinkthat allows us to scale Devin to tens of thousands of concurrent machines (learn more about blockdiff). This enabled us to smoothly support very high concurrency and ensure the training environment is aligned with our Devin production environments.
That's another similarity to Cursor's Composer-1! Cursor talked about how they ran "hundreds of thousands of concurrent sandboxed coding environments in the cloud" in their description of their RL training as well.
This is a notable trend: if you want to build a really great agentic coding tool there's clearly a lot to be said for using reinforcement learning to fine-tune a model against your own custom set of tools using large numbers of sandboxed simulated coding environments as part of that process.
Update: I think it's built on GLM.
MiniMax M2 & Agent: Ingenious in Simplicity. MiniMax M2 was released on Monday 27th October by MiniMax, a Chinese AI lab founded in December 2021.
It's a very promising model. Their self-reported benchmark scores show it as comparable to Claude Sonnet 4, and Artificial Analysis are ranking it as the best currently available open weight model according to their intelligence score:
MiniMax’s M2 achieves a new all-time-high Intelligence Index score for an open weights model and offers impressive efficiency with only 10B active parameters (200B total). [...]
The model’s strengths include tool use and instruction following (as shown by Tau2 Bench and IFBench). As such, while M2 likely excels at agentic use cases it may underperform other open weights leaders such as DeepSeek V3.2 and Qwen3 235B at some generalist tasks. This is in line with a number of recent open weights model releases from Chinese AI labs which focus on agentic capabilities, likely pointing to a heavy post-training emphasis on RL.
The size is particularly significant: the model weights are 230GB on Hugging Face, significantly smaller than other high performing open weight models. That's small enough to run on a 256GB Mac Studio, and the MLX community have that working already.
MiniMax offer their own API, and recommend using their Anthropic-compatible endpoint and the official Anthropic SDKs to access it. MiniMax Head of Engineering Skyler Miao provided some background on that:
M2 is a agentic thinking model, it do interleaved thinking like sonnet 4.5, which means every response will contain its thought content. Its very important for M2 to keep the chain of thought. So we must make sure the history thought passed back to the model. Anthropic API support it for sure, as sonnet needs it as well. OpenAI only support it in their new Response API, no support for in ChatCompletion.
MiniMax are offering the new model via their API for free until November 7th, after which the cost will be $0.30/million input tokens and $1.20/million output tokens - similar in price to Gemini 2.5 Flash and GPT-5 Mini, see price comparison here on my llm-prices.com site.
I released a new plugin for LLM called llm-minimax providing support for M2 via the MiniMax API:
llm install llm-minimax
llm keys set minimax
# Paste key here
llm -m m2 -o max_tokens 10000 "Generate an SVG of a pelican riding a bicycle"
Here's the result:

51 input, 4,017 output. At $0.30/m input and $1.20/m output that pelican would cost 0.4836 cents - less than half a cent.
This is the first plugin I've written for an Anthropic-API-compatible model. I released llm-anthropic 0.21 first adding the ability to customize the base_url parameter when using that model class. This meant the new plugin was less than 30 lines of Python.
Composer: Building a fast frontier model with RL (via) Cursor released Cursor 2.0 today, with a refreshed UI focused on agentic coding (and running agents in parallel) and a new model that's unique to Cursor called Composer 1.
As far as I can tell there's no way to call the model directly via an API, so I fired up "Ask" mode in Cursor's chat side panel and asked it to "Generate an SVG of a pelican riding a bicycle":
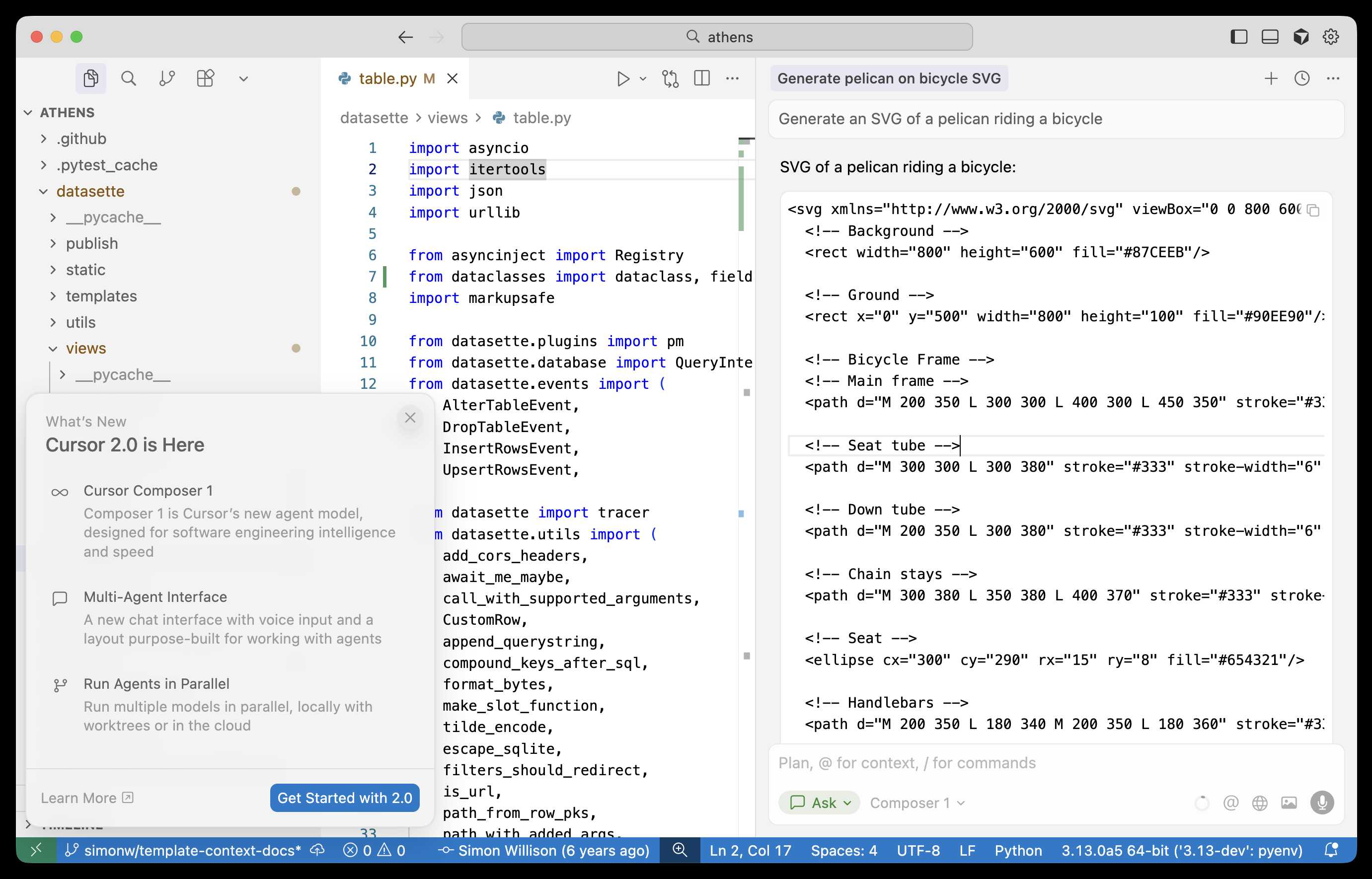
Here's the result:

The notable thing about Composer-1 is that it is designed to be fast. The pelican certainly came back quickly, and in their announcement they describe it as being "4x faster than similarly intelligent models".
It's interesting to see Cursor investing resources in training their own code-specific model - similar to GPT-5-Codex or Qwen3-Coder. From their post:
Composer is a mixture-of-experts (MoE) language model supporting long-context generation and understanding. It is specialized for software engineering through reinforcement learning (RL) in a diverse range of development environments. [...]
Efficient training of large MoE models requires significant investment into building infrastructure and systems research. We built custom training infrastructure leveraging PyTorch and Ray to power asynchronous reinforcement learning at scale. We natively train our models at low precision by combining our MXFP8 MoE kernels with expert parallelism and hybrid sharded data parallelism, allowing us to scale training to thousands of NVIDIA GPUs with minimal communication cost. [...]
During RL, we want our model to be able to call any tool in the Cursor Agent harness. These tools allow editing code, using semantic search, grepping strings, and running terminal commands. At our scale, teaching the model to effectively call these tools requires running hundreds of thousands of concurrent sandboxed coding environments in the cloud.
One detail that's notably absent from their description: did they train the model from scratch, or did they start with an existing open-weights model such as something from Qwen or GLM?
Cursor researcher Sasha Rush has been answering questions on Hacker News, but has so far been evasive in answering questions about the base model. When directly asked "is Composer a fine tune of an existing open source base model?" they replied:
Our primary focus is on RL post-training. We think that is the best way to get the model to be a strong interactive agent.
Sasha did confirm that rumors of an earlier Cursor preview model, Cheetah, being based on a model by xAI's Grok were "Straight up untrue."
Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code

DeepSeek released a new model yesterday: DeepSeek-OCR, a 6.6GB model fine-tuned specifically for OCR. They released it as model weights that run using PyTorch and CUDA. I got it running on the NVIDIA Spark by having Claude Code effectively brute force the challenge of getting it working on that particular hardware.
[... 1,971 words]Introducing Claude Haiku 4.5 (via) Anthropic released Claude Haiku 4.5 today, the cheapest member of the Claude 4.5 family that started with Sonnet 4.5 a couple of weeks ago.
It's priced at $1/million input tokens and $5/million output tokens, slightly more expensive than Haiku 3.5 ($0.80/$4) and a lot more expensive than the original Claude 3 Haiku ($0.25/$1.25), both of which remain available at those prices.
It's a third of the price of Sonnet 4 and Sonnet 4.5 (both $3/$15) which is notable because Anthropic's benchmarks put it in a similar space to that older Sonnet 4 model. As they put it:
What was recently at the frontier is now cheaper and faster. Five months ago, Claude Sonnet 4 was a state-of-the-art model. Today, Claude Haiku 4.5 gives you similar levels of coding performance but at one-third the cost and more than twice the speed.
I've been hoping to see Anthropic release a fast, inexpensive model that's price competitive with the cheapest models from OpenAI and Gemini, currently $0.05/$0.40 (GPT-5-Nano) and $0.075/$0.30 (Gemini 2.0 Flash Lite). Haiku 4.5 certainly isn't that, it looks like they're continuing to focus squarely on the "great at code" part of the market.
The new Haiku is the first Haiku model to support reasoning. It sports a 200,000 token context window, 64,000 maximum output (up from just 8,192 for Haiku 3.5) and a "reliable knowledge cutoff" of February 2025, one month later than the January 2025 date for Sonnet 4 and 4.5 and Opus 4 and 4.1.
Something that caught my eye in the accompanying system card was this note about context length:
For Claude Haiku 4.5, we trained the model to be explicitly context-aware, with precise information about how much context-window has been used. This has two effects: the model learns when and how to wrap up its answer when the limit is approaching, and the model learns to continue reasoning more persistently when the limit is further away. We found this intervention—along with others—to be effective at limiting agentic “laziness” (the phenomenon where models stop working on a problem prematurely, give incomplete answers, or cut corners on tasks).
I've added the new price to llm-prices.com, released llm-anthropic 0.20 with the new model and updated my Haiku-from-your-webcam demo (source) to use Haiku 4.5 as well.
Here's llm -m claude-haiku-4.5 'Generate an SVG of a pelican riding a bicycle' (transcript).

18 input tokens and 1513 output tokens = 0.7583 cents.
GPT-5 pro. Here's OpenAI's model documentation for their GPT-5 pro model, released to their API today at their DevDay event.
It has similar base characteristics to GPT-5: both share a September 30, 2024 knowledge cutoff and 400,000 context limit.
GPT-5 pro has maximum output tokens 272,000 max, an increase from 128,000 for GPT-5.
As our most advanced reasoning model, GPT-5 pro defaults to (and only supports)
reasoning.effort: high
It's only available via OpenAI's Responses API. My LLM tool doesn't support that in core yet, but the llm-openai-plugin plugin does. I released llm-openai-plugin 0.7 adding support for the new model, then ran this:
llm install -U llm-openai-plugin
llm -m openai/gpt-5-pro "Generate an SVG of a pelican riding a bicycle"
It's very, very slow. The model took 6 minutes 8 seconds to respond and charged me for 16 input and 9,205 output tokens. At $15/million input and $120/million output this pelican cost me $1.10!

Here's the full transcript. It looks visually pretty simpler to the much, much cheaper result I got from GPT-5.
Two new models from Chinese AI labs in the past few days. I tried them both out using llm-openrouter:
DeepSeek-V3.2-Exp from DeepSeek. Announcement, Tech Report, Hugging Face (690GB, MIT license).
As an intermediate step toward our next-generation architecture, V3.2-Exp builds upon V3.1-Terminus by introducing DeepSeek Sparse Attention—a sparse attention mechanism designed to explore and validate optimizations for training and inference efficiency in long-context scenarios.
This one felt very slow when I accessed it via OpenRouter - I probably got routed to one of the slower providers. Here's the pelican:
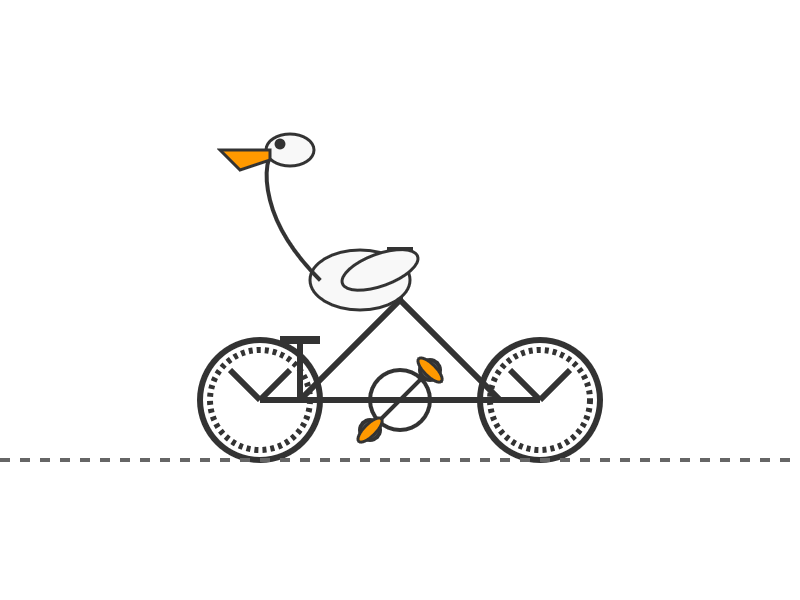
GLM-4.6 from Z.ai. Announcement, Hugging Face (714GB, MIT license).
The context window has been expanded from 128K to 200K tokens [...] higher scores on code benchmarks [...] GLM-4.6 exhibits stronger performance in tool using and search-based agents.
Here's the pelican for that:

Claude Sonnet 4.5 is probably the “best coding model in the world” (at least for now)

Anthropic released Claude Sonnet 4.5 today, with a very bold set of claims:
[... 1,205 words]Improved Gemini 2.5 Flash and Flash-Lite (via) Two new preview models from Google - updates to their fast and inexpensive Flash and Flash Lite families:
The latest version of Gemini 2.5 Flash-Lite was trained and built based on three key themes:
- Better instruction following: The model is significantly better at following complex instructions and system prompts.
- Reduced verbosity: It now produces more concise answers, a key factor in reducing token costs and latency for high-throughput applications (see charts above).
- Stronger multimodal & translation capabilities: This update features more accurate audio transcription, better image understanding, and improved translation quality.
[...]
This latest 2.5 Flash model comes with improvements in two key areas we heard consistent feedback on:
- Better agentic tool use: We've improved how the model uses tools, leading to better performance in more complex, agentic and multi-step applications. This model shows noticeable improvements on key agentic benchmarks, including a 5% gain on SWE-Bench Verified, compared to our last release (48.9% → 54%).
- More efficient: With thinking on, the model is now significantly more cost-efficient—achieving higher quality outputs while using fewer tokens, reducing latency and cost (see charts above).
They also added two new convenience model IDs: gemini-flash-latest and gemini-flash-lite-latest, which will always resolve to the most recent model in that family.
I released llm-gemini 0.26 adding support for the new models and new aliases. I also used the response.set_resolved_model() method added in LLM 0.27 to ensure that the correct model ID would be recorded for those -latest uses.
llm install -U llm-gemini
Both of these models support optional reasoning tokens. I had them draw me pelicans riding bicycles in both thinking and non-thinking mode, using commands that looked like this:
llm -m gemini-2.5-flash-preview-09-2025 -o thinking_budget 4000 "Generate an SVG of a pelican riding a bicycle"
I then got each model to describe the image it had drawn using commands like this:
llm -a https://static.simonwillison.net/static/2025/gemini-2.5-flash-preview-09-2025-thinking.png -m gemini-2.5-flash-preview-09-2025 -o thinking_budget 2000 'Detailed single line alt text for this image'
gemini-2.5-flash-preview-09-2025-thinking

A minimalist stick figure graphic depicts a person with a white oval body and a dot head cycling a gray bicycle, carrying a large, bright yellow rectangular box resting high on their back.
gemini-2.5-flash-preview-09-2025
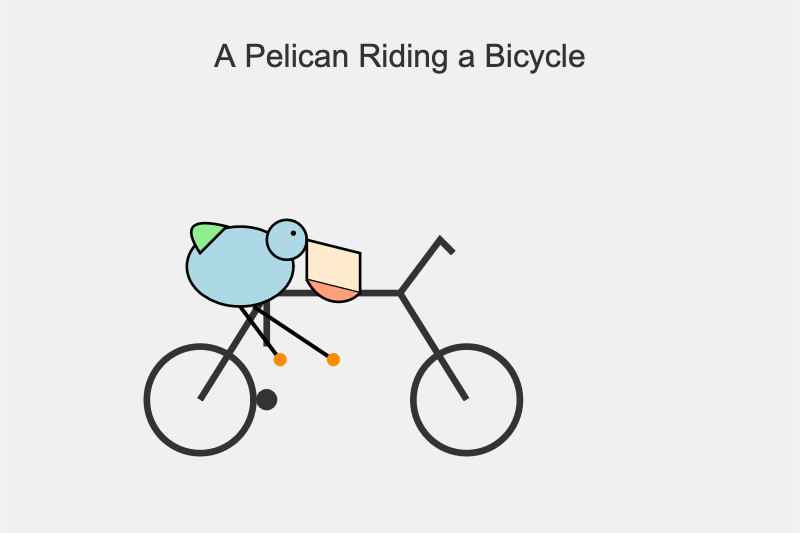
A simple cartoon drawing of a pelican riding a bicycle, with the text "A Pelican Riding a Bicycle" above it.
gemini-2.5-flash-lite-preview-09-2025-thinking

A quirky, simplified cartoon illustration of a white bird with a round body, black eye, and bright yellow beak, sitting astride a dark gray, two-wheeled vehicle with its peach-colored feet dangling below.
gemini-2.5-flash-lite-preview-09-2025

A minimalist, side-profile illustration of a stylized yellow chick or bird character riding a dark-wheeled vehicle on a green strip against a white background.
Artificial Analysis posted a detailed review, including these interesting notes about reasoning efficiency and speed:
- In reasoning mode, Gemini 2.5 Flash and Flash-Lite Preview 09-2025 are more token-efficient, using fewer output tokens than their predecessors to run the Artificial Analysis Intelligence Index. Gemini 2.5 Flash-Lite Preview 09-2025 uses 50% fewer output tokens than its predecessor, while Gemini 2.5 Flash Preview 09-2025 uses 24% fewer output tokens.
- Google Gemini 2.5 Flash-Lite Preview 09-2025 (Reasoning) is ~40% faster than the prior July release, delivering ~887 output tokens/s on Google AI Studio in our API endpoint performance benchmarking. This makes the new Gemini 2.5 Flash-Lite the fastest proprietary model we have benchmarked on the Artificial Analysis website
GPT-5-Codex. OpenAI half-released this model earlier this month, adding it to their Codex CLI tool but not their API.
Today they've fixed that - the new model can now be accessed as gpt-5-codex. It's priced the same as regular GPT-5: $1.25/million input tokens, $10/million output tokens, and the same hefty 90% discount for previously cached input tokens, especially important for agentic tool-using workflows which quickly produce a lengthy conversation.
It's only available via their Responses API, which means you currently need to install the llm-openai-plugin to use it with LLM:
llm install -U llm-openai-plugin
llm -m openai/gpt-5-codex -T llm_version 'What is the LLM version?'
Outputs:
The installed LLM version is 0.27.1.
I added tool support to that plugin today, mostly authored by GPT-5 Codex itself using OpenAI's Codex CLI.
The new prompting guide for GPT-5-Codex is worth a read.
GPT-5-Codex is purpose-built for Codex CLI, the Codex IDE extension, the Codex cloud environment, and working in GitHub, and also supports versatile tool use. We recommend using GPT-5-Codex only for agentic and interactive coding use cases.
Because the model is trained specifically for coding, many best practices you once had to prompt into general purpose models are built in, and over prompting can reduce quality.
The core prompting principle for GPT-5-Codex is “less is more.”
I tried my pelican benchmark at a cost of 2.156 cents.
llm -m openai/gpt-5-codex "Generate an SVG of a pelican riding a bicycle"

I asked Codex to describe this image and it correctly identified it as a pelican!
llm -m openai/gpt-5-codex -a https://static.simonwillison.net/static/2025/gpt-5-codex-api-pelican.png \
-s 'Write very detailed alt text'
Cartoon illustration of a cream-colored pelican with a large orange beak and tiny black eye riding a minimalist dark-blue bicycle. The bird’s wings are tucked in, its legs resemble orange stick limbs pushing the pedals, and its tail feathers trail behind with light blue motion streaks to suggest speed. A small coral-red tongue sticks out of the pelican’s beak. The bicycle has thin light gray spokes, and the background is a simple pale blue gradient with faint curved lines hinting at ground and sky.
Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action (via) I've been looking forward to this. Qwen 2.5 VL is one of the best available open weight vision LLMs, so I had high hopes for Qwen 3's vision models.
Firstly, we are open-sourcing the flagship model of this series: Qwen3-VL-235B-A22B, available in both Instruct and Thinking versions. The Instruct version matches or even exceeds Gemini 2.5 Pro in major visual perception benchmarks. The Thinking version achieves state-of-the-art results across many multimodal reasoning benchmarks.
Bold claims against Gemini 2.5 Pro, which are supported by a flurry of self-reported benchmarks.
This initial model is enormous. On Hugging Face both Qwen3-VL-235B-A22B-Instruct and Qwen3-VL-235B-A22B-Thinking are 235B parameters and weigh 471 GB. Not something I'm going to be able to run on my 64GB Mac!
The Qwen 2.5 VL family included models at 72B, 32B, 7B and 3B sizes. Given the rate Qwen are shipping models at the moment I wouldn't be surprised to see smaller Qwen 3 VL models show up in just the next few days.
Also from Qwen today, three new API-only closed-weight models: upgraded Qwen 3 Coder, Qwen3-LiveTranslate-Flash (real-time multimodal interpretation), and Qwen3-Max, their new trillion parameter flagship model, which they describe as their "largest and most capable model to date".
Plus Qwen3Guard, a "safety moderation model series" that looks similar in purpose to Meta's Llama Guard. This one is open weights (Apache 2.0) and comes in 8B, 4B and 0.6B sizes on Hugging Face. There's more information in the QwenLM/Qwen3Guard GitHub repo.
It's been an extremely busy day for team Qwen. Within the last 24 hours (all links to Twitter, which seems to be their preferred platform for these announcements):
- Qwen3-Next-80B-A3B-Instruct-FP8 and Qwen3-Next-80B-A3B-Thinking-FP8 - official FP8 quantized versions of their Qwen3-Next models. On Hugging Face Qwen3-Next-80B-A3B-Instruct is 163GB and Qwen3-Next-80B-A3B-Instruct-FP8 is 82.1GB. I wrote about Qwen3-Next on Friday 12th September.
- Qwen3-TTS-Flash provides "multi-timbre, multi-lingual, and multi-dialect speech synthesis" according to their blog announcement. It's not available as open weights, you have to access it via their API instead. Here's a free live demo.
- Qwen3-Omni is today's most exciting announcement: a brand new 30B parameter "omni" model supporting text, audio and video input and text and audio output! You can try it on chat.qwen.ai by selecting the "Use voice and video chat" icon - you'll need to be signed in using Google or GitHub. This one is open weights, as Apache 2.0 Qwen3-Omni-30B-A3B-Instruct, Qwen/Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner on HuggingFace. That Instruct model is 70.5GB so this should be relatively accessible for running on expensive home devices.
- Qwen-Image-Edit-2509 is an updated version of their excellent Qwen-Image-Edit model which I first tried last month. Their blog post calls it "the monthly iteration of Qwen-Image-Edit" so I guess they're planning more frequent updates. The new model adds multi-image inputs. I used it via chat.qwen.ai to turn a photo of our dog into a dragon in the style of one of Natalie's ceramic pots.

Here's the prompt I used, feeding in two separate images. Weirdly it used the edges of the landscape photo to fill in the gaps on the otherwise portrait output. It turned the chair seat into a bowl too!

Grok 4 Fast. New hosted vision-enabled reasoning model from xAI that's designed to be fast and extremely competitive on price. It has a 2 million token context window and "was trained end-to-end with tool-use reinforcement learning".
It's priced at $0.20/million input tokens and $0.50/million output tokens - 15x less than Grok 4 (which is $3/million input and $15/million output). That puts it cheaper than GPT-5 mini and Gemini 2.5 Flash on llm-prices.com.
The same model weights handle reasoning and non-reasoning based on a parameter passed to the model.
I've been trying it out via my updated llm-openrouter plugin, since Grok 4 Fast is available for free on OpenRouter for a limited period.
Here's output from the non-reasoning model. This actually output an invalid SVG - I had to make a tiny manual tweak to the XML to get it to render.
llm -m openrouter/x-ai/grok-4-fast:free "Generate an SVG of a pelican riding a bicycle" -o reasoning_enabled false
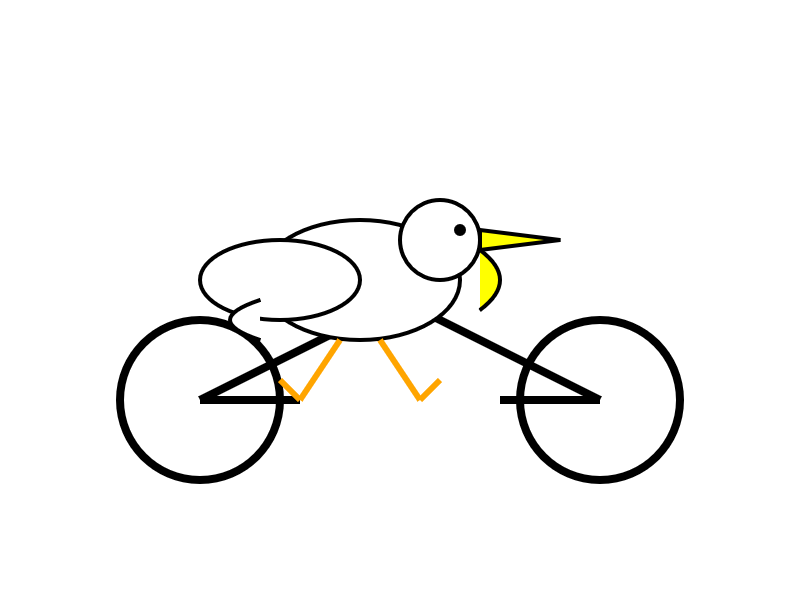
(I initially ran this without that -o reasoning_enabled false flag, but then I saw that OpenRouter enable reasoning by default for that model. Here's my previous invalid result.)
And the reasoning model:
llm -m openrouter/x-ai/grok-4-fast:free "Generate an SVG of a pelican riding a bicycle" -o reasoning_enabled true

In related news, the New York Times had a story a couple of days ago about Elon's recent focus on xAI: Since Leaving Washington, Elon Musk Has Been All In on His A.I. Company.
Mistral quietly released two new models yesterday: Magistral Small 1.2 (Apache 2.0, 96.1 GB on Hugging Face) and Magistral Medium 1.2 (not open weights same as Mistral's other "medium" models.)
Despite being described as "minor updates" to the Magistral 1.1 models these have one very notable improvement:
- Multimodality: Now equipped with a vision encoder, these models handle both text and images seamlessly.
Magistral is Mistral's reasoning model, so we now have a new reasoning vision LLM.
The other features from the tiny announcement on Twitter:
- Performance Boost: 15% improvements on math and coding benchmarks such as AIME 24/25 and LiveCodeBench v5/v6.
- Smarter Tool Use: Better tool usage with web search, code interpreter, and image generation.
- Better Tone & Persona: Responses are clearer, more natural, and better formatted for you.
GPT‑5-Codex and upgrades to Codex. OpenAI half-released a new model today: GPT‑5-Codex, a fine-tuned GPT-5 variant explicitly designed for their various AI-assisted programming tools.
Update: OpenAI call it a "version of GPT-5", they don't explicitly describe it as a fine-tuned model. Calling it a fine-tune was my mistake here.
I say half-released because it's not yet available via their API, but they "plan to make GPT‑5-Codex available in the API soon".
I wrote about the confusing array of OpenAI products that share the name Codex a few months ago. This new model adds yet another, though at least "GPT-5-Codex" (using two hyphens) is unambiguous enough not to add to much more to the confusion.
At this point it's best to think of Codex as OpenAI's brand name for their coding family of models and tools.
The new model is already integrated into their VS Code extension, the Codex CLI and their Codex Cloud asynchronous coding agent. I'd been calling that last one "Codex Web" but I think Codex Cloud is a better name since it can also be accessed directly from their iPhone app.
Codex Cloud also has a new feature: you can configure it to automatically run code review against specific GitHub repositories (I found that option on chatgpt.com/codex/settings/code-review) and it will create a temporary container to use as part of those reviews. Here's the relevant documentation.
Some documented features of the new GPT-5-Codex model:
- Specifically trained for code review, which directly supports their new code review feature.
- "GPT‑5-Codex adapts how much time it spends thinking more dynamically based on the complexity of the task." Simple tasks (like "list files in this directory") should run faster. Large, complex tasks should use run for much longer - OpenAI report Codex crunching for seven hours in some cases!
- Increased score on their proprietary "code refactoring evaluation" from 33.9% for GPT-5 (high) to 51.3% for GPT-5-Codex (high). It's hard to evaluate this without seeing the details of the eval but it does at least illustrate that refactoring performance is something they've focused on here.
- "GPT‑5-Codex also shows significant improvements in human preference evaluations when creating mobile websites" - in the past I've habitually prompted models to "make it mobile-friendly", maybe I don't need to do that any more.
- "We find that comments by GPT‑5-Codex are less likely to be incorrect or unimportant" - I originally misinterpreted this as referring to comments in code but it's actually about comments left on code reviews.
The system prompt for GPT-5-Codex in Codex CLI is worth a read. It's notably shorter than the system prompt for other models - here's a diff.
Here's the section of the updated system prompt that talks about comments:
Add succinct code comments that explain what is going on if code is not self-explanatory. You should not add comments like "Assigns the value to the variable", but a brief comment might be useful ahead of a complex code block that the user would otherwise have to spend time parsing out. Usage of these comments should be rare.
Theo Browne has a video review of the model and accompanying features. He was generally impressed but noted that it was surprisingly bad at using the Codex CLI search tool to navigate code. Hopefully that's something that can fix with a system prompt update.
Finally, can it drew a pelican riding a bicycle? Without API access I instead got Codex Cloud to have a go by prompting:
Generate an SVG of a pelican riding a bicycle, save as pelican.svg
Here's the result:

Qwen3-Next-80B-A3B. Qwen announced two new models via their Twitter account (and here's their blog): Qwen3-Next-80B-A3B-Instruct and Qwen3-Next-80B-A3B-Thinking.
They make some big claims on performance:
- Qwen3-Next-80B-A3B-Instruct approaches our 235B flagship.
- Qwen3-Next-80B-A3B-Thinking outperforms Gemini-2.5-Flash-Thinking.
The name "80B-A3B" indicates 80 billion parameters of which only 3 billion are active at a time. You still need to have enough GPU-accessible RAM to hold all 80 billion in memory at once but only 3 billion will be used for each round of inference, which provides a significant speedup in responding to prompts.
More details from their tweet:
- 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!)
- Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed & recall
- Ultra-sparse MoE: 512 experts, 10 routed + 1 shared
- Multi-Token Prediction → turbo-charged speculative decoding
- Beats Qwen3-32B in perf, rivals Qwen3-235B in reasoning & long-context
The models on Hugging Face are around 150GB each so I decided to try them out via OpenRouter rather than on my own laptop (Thinking, Instruct).
I'm used my llm-openrouter plugin. I installed it like this:
llm install llm-openrouter
llm keys set openrouter
# paste key here
Then found the model IDs with this command:
llm models -q next
Which output:
OpenRouter: openrouter/qwen/qwen3-next-80b-a3b-thinking
OpenRouter: openrouter/qwen/qwen3-next-80b-a3b-instruct
I have an LLM prompt template saved called pelican-svg which I created like this:
llm "Generate an SVG of a pelican riding a bicycle" --save pelican-svg
This means I can run my pelican benchmark like this:
llm -t pelican-svg -m openrouter/qwen/qwen3-next-80b-a3b-thinking
Or like this:
llm -t pelican-svg -m openrouter/qwen/qwen3-next-80b-a3b-instruct
Here's the thinking model output (exported with llm logs -c | pbcopy after I ran the prompt):
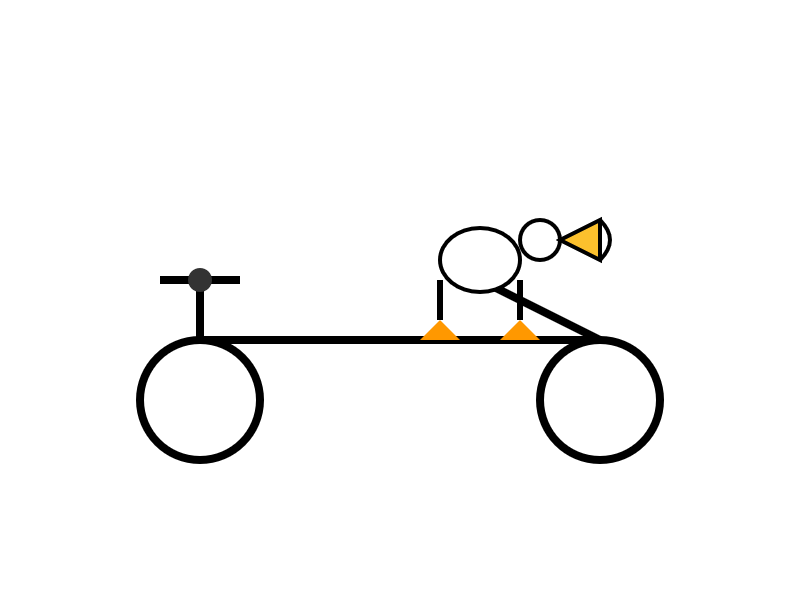
I enjoyed the "Whimsical style with smooth curves and friendly proportions (no anatomical accuracy needed for bicycle riding!)" note in the transcript.
The instruct (non-reasoning) model gave me this:

"🐧🦩 Who needs legs!?" indeed! I like that penguin-flamingo emoji sequence it's decided on for pelicans.
Kimi-K2-Instruct-0905. New not-quite-MIT licensed model from Chinese Moonshot AI, a follow-up to the highly regarded Kimi-K2 model they released in July.
This one is an incremental improvement - I've seen it referred to online as "Kimi K-2.1". It scores a little higher on a bunch of popular coding benchmarks, reflecting Moonshot's claim that it "demonstrates significant improvements in performance on public benchmarks and real-world coding agent tasks".
More importantly the context window size has been increased from 128,000 to 256,000 tokens.
Like its predecessor this is a big model - 1 trillion parameters in a mixture-of-experts configuration with 384 experts, 32B activated parameters and 8 selected experts per token.
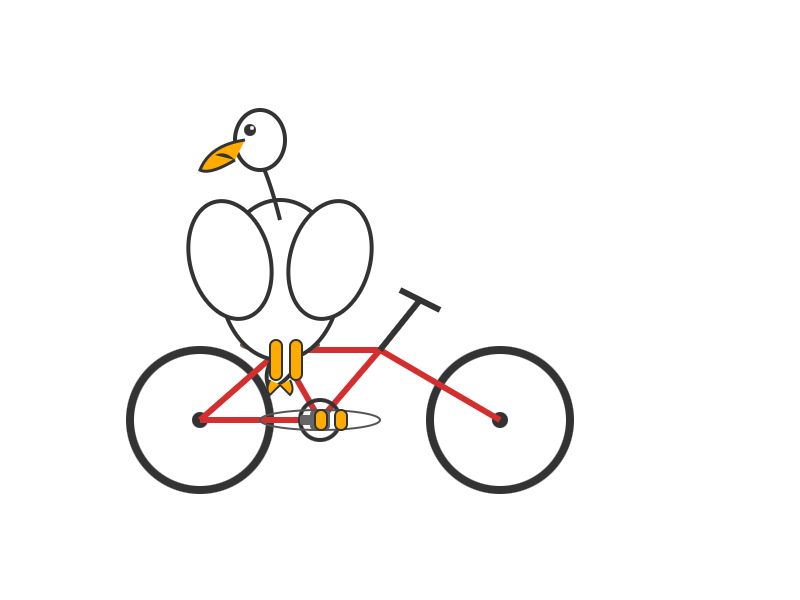
I used Groq's playground tool to try "Generate an SVG of a pelican riding a bicycle" and got this result, at a very healthy 445 tokens/second taking just under 2 seconds total:
Introducing gpt-realtime.
Released a few days ago (August 28th), gpt-realtime is OpenAI's new "most advanced speech-to-speech model". It looks like this is a replacement for the older gpt-4o-realtime-preview model that was released last October.
This is a slightly confusing release. The previous realtime model was clearly described as a variant of GPT-4o, sharing the same October 2023 training cut-off date as that model.
I had expected that gpt-realtime might be a GPT-5 relative, but its training date is still October 2023 whereas GPT-5 is September 2024.
gpt-realtime also shares the relatively low 32,000 context token and 4,096 maximum output token limits of gpt-4o-realtime-preview.
The only reference I found to GPT-5 in the documentation for the new model was a note saying "Ambiguity and conflicting instructions degrade performance, similar to GPT-5."
The usage tips for gpt-realtime have a few surprises:
Iterate relentlessly. Small wording changes can make or break behavior.
Example: Swapping “inaudible” → “unintelligible” improved noisy input handling. [...]
Convert non-text rules to text: The model responds better to clearly written text.
Example: Instead of writing, "IF x > 3 THEN ESCALATE", write, "IF MORE THAN THREE FAILURES THEN ESCALATE."
There are a whole lot more prompting tips in the new Realtime Prompting Guide.
OpenAI list several key improvements to gpt-realtime including the ability to configure it with a list of MCP servers, "better instruction following" and the ability to send it images.
My biggest confusion came from the pricing page, which lists separate pricing for using the Realtime API with gpt-realtime and GPT-4o mini. This suggests to me that the old gpt-4o-mini-realtime-preview model is still available, despite it no longer being listed on the OpenAI models page.
gpt-4o-mini-realtime-preview is a lot cheaper:
| Model | Token Type | Input | Cached Input | Output |
|---|---|---|---|---|
| gpt-realtime | Text | $4.00 | $0.40 | $16.00 |
| Audio | $32.00 | $0.40 | $64.00 | |
| Image | $5.00 | $0.50 | - | |
| gpt-4o-mini-realtime-preview | Text | $0.60 | $0.30 | $2.40 |
| Audio | $10.00 | $0.30 | $20.00 |
The mini model also has a much longer 128,000 token context window.
Update: Turns out that was a mistake in the documentation, that mini model has a 16,000 token context size.
Update 2: OpenAI's Peter Bakkum clarifies:
There are different voice models in API and ChatGPT, but they share some recent improvements. The voices are also different.
gpt-realtime has a mix of data specific enough to itself that its not really 4o or 5
DeepSeek 3.1. The latest model from DeepSeek, a 685B monster (like DeepSeek v3 before it) but this time it's a hybrid reasoning model.
DeepSeek claim:
DeepSeek-V3.1-Think achieves comparable answer quality to DeepSeek-R1-0528, while responding more quickly.
Drew Breunig points out that their benchmarks show "the same scores with 25-50% fewer tokens" - at least across AIME 2025 and GPQA Diamond and LiveCodeBench.
The DeepSeek release includes prompt examples for a coding agent, a python agent and a search agent - yet more evidence that the leading AI labs have settled on those as the three most important agentic patterns for their models to support.
Here's the pelican riding a bicycle it drew me (transcript), which I ran from my phone using OpenRouter chat.

Introducing Gemma 3 270M: The compact model for hyper-efficient AI (via) New from Google:
Gemma 3 270M, a compact, 270-million parameter model designed from the ground up for task-specific fine-tuning with strong instruction-following and text structuring capabilities already trained in.
This model is tiny. The version I tried was the LM Studio GGUF one, a 241MB download.
It works! You can say "hi" to it and ask it very basic questions like "What is the capital of France".
I tried "Generate an SVG of a pelican riding a bicycle" about a dozen times and didn't once get back an SVG that was more than just a blank square... but at one point it did decide to write me this poem instead, which was nice:
+-----------------------+
| Pelican Riding Bike |
+-----------------------+
| This is the cat! |
| He's got big wings and a happy tail. |
| He loves to ride his bike! |
+-----------------------+
| Bike lights are shining bright. |
| He's got a shiny top, too! |
| He's ready for adventure! |
+-----------------------+
That's not really the point though. The Gemma 3 team make it very clear that the goal of this model is to support fine-tuning: a model this tiny is never going to be useful for general purpose LLM tasks, but given the right fine-tuning data it should be able to specialize for all sorts of things:
In engineering, success is defined by efficiency, not just raw power. You wouldn't use a sledgehammer to hang a picture frame. The same principle applies to building with AI.
Gemma 3 270M embodies this "right tool for the job" philosophy. It's a high-quality foundation model that follows instructions well out of the box, and its true power is unlocked through fine-tuning. Once specialized, it can execute tasks like text classification and data extraction with remarkable accuracy, speed, and cost-effectiveness. By starting with a compact, capable model, you can build production systems that are lean, fast, and dramatically cheaper to operate.
Here's their tutorial on Full Model Fine-Tune using Hugging Face Transformers, which I have not yet attempted to follow.
I imagine this model will be particularly fun to play with directly in a browser using transformers.js.
Update: It is! Here's a bedtime story generator using Transformers.js (requires WebGPU, so Chrome-like browsers only). Here's the source code for that demo.
Qwen3-4B-Thinking: “This is art—pelicans don’t ride bikes!”

I’ve fallen a few days behind keeping up with Qwen. They released two new 4B models last week: Qwen3-4B-Instruct-2507 and its thinking equivalent Qwen3-4B-Thinking-2507.
[... 991 words]GPT-5: Key characteristics, pricing and model card

I’ve had preview access to the new GPT-5 model family for the past two weeks (see related video and my disclosures) and have been using GPT-5 as my daily-driver. It’s my new favorite model. It’s still an LLM—it’s not a dramatic departure from what we’ve had before—but it rarely screws up and generally feels competent or occasionally impressive at the kinds of things I like to use models for.
[... 2,448 words]OpenAI’s new open weight (Apache 2) models are really good
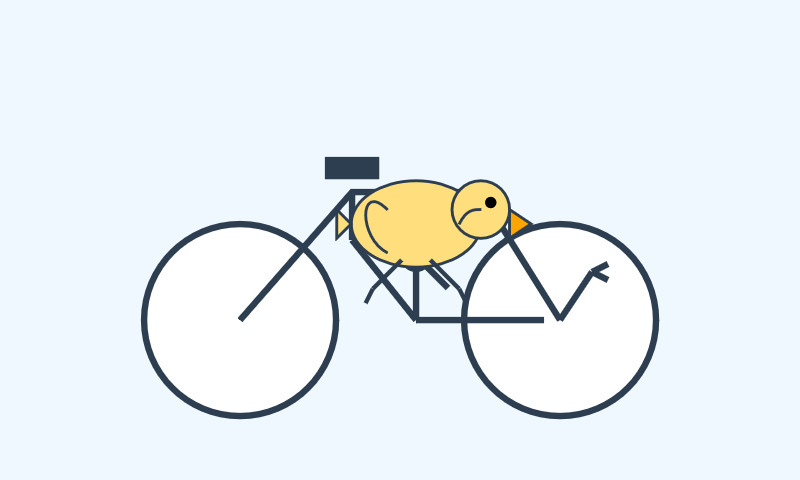
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]Claude Opus 4.1. Surprise new model from Anthropic today - Claude Opus 4.1, which they describe as "a drop-in replacement for Opus 4".
My favorite thing about this model is the version number - treating this as a .1 version increment looks like it's an accurate depiction of the model's capabilities.
Anthropic's own benchmarks show very small incremental gains.
Comparing Opus 4 and Opus 4.1 (I got 4.1 to extract this information from a screenshot of Anthropic's own benchmark scores, then asked it to look up the links, then verified the links myself and fixed a few):
- Agentic coding (SWE-bench Verified): From 72.5% to 74.5%
- Agentic terminal coding (Terminal-Bench): From 39.2% to 43.3%
- Graduate-level reasoning (GPQA Diamond): From 79.6% to 80.9%
- Agentic tool use (TAU-bench):
- Retail: From 81.4% to 82.4%
- Airline: From 59.6% to 56.0% (decreased)
- Multilingual Q&A (MMMLU): From 88.8% to 89.5%
- Visual reasoning (MMMU validation): From 76.5% to 77.1%
- High school math competition (AIME 2025): From 75.5% to 78.0%
Likewise, the model card shows only tiny changes to the various safety metrics that Anthropic track.
It's priced the same as Opus 4 - $15/million for input and $75/million for output, making it one of the most expensive models on the market today.
I had it draw me this pelican riding a bicycle:
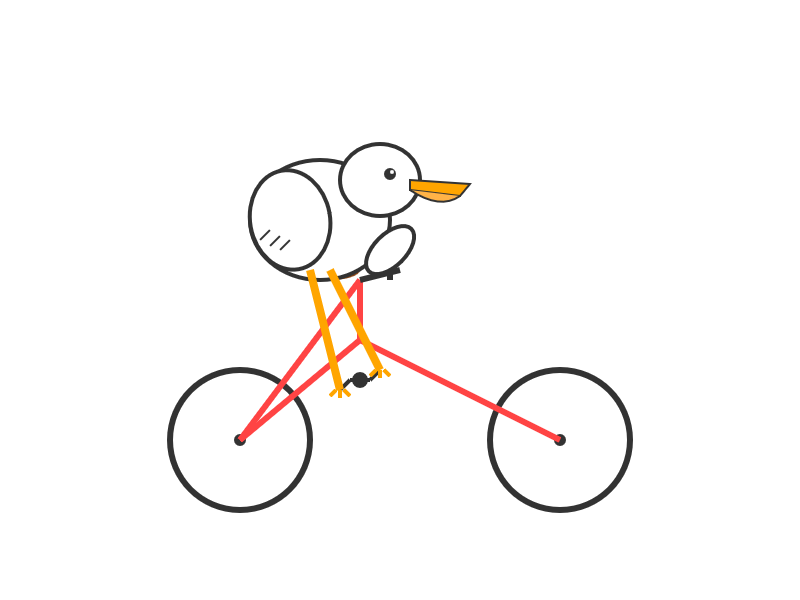
For comparison I got a fresh new pelican out of Opus 4 which I actually like a little more:

I shipped llm-anthropic 0.18 with support for the new model.
XBai o4 (via) Yet another open source (Apache 2.0) LLM from a Chinese AI lab. This model card claims:
XBai o4 excels in complex reasoning capabilities and has now completely surpassed OpenAI-o3-mini in Medium mode.
This a 32.8 billion parameter model released by MetaStone AI, a new-to-me lab who released their first model in March - MetaStone-L1-7B, then followed that with MetaStone-S1 1.5B, 7B and 32B in July and now XBai o4 in August.
The MetaStone-S1 models were accompanied with a paper, Test-Time Scaling with Reflective Generative Model.
There is very little information available on the English-language web about MetaStone AI. Their paper shows a relationship with USTC, University of Science and Technology of China in Hefei. One of their researchers confirmed on Twitter that their CEO is from KWAI which lead me to this Chinese language article from July last year about Li Yan, formerly of KWAI and now the founder of Wen Xiaobai and evidently now the CEO of MetaStone. www.wenxiaobai.com is listed as the "official website" linked to from the XBai-o4 README on GitHub.
Ivan Fioravanti got it working under MLX in 4bit, 5bit, 6bit, 8bit and 4bit-DWQ sizes. I tried his 6bit one (a 24.81GB download) in LM Studio and had it "Generate an SVG of a pelican riding a bicycle". It thought for 39.49 seconds (thinking trace here) and gave me this:

I also had it "Write an HTML and JavaScript page implementing space invaders", which you can try out here. It's not great - the invaders don't fire bullets (it listed that as a "potential improvement") and I don't think it's winnable due to timing issues, but it's an interesting addition to my collection.
LM Studio reported a constant memory usage of 25.54GB and according to Activity Monitor used 87.5% of my GPU and around 39% of a CPU core.
It did a lot of work in the thinking trace - which took 10m35s! - including writing the first draft of much of the code that ended up in the finished result. Here's an extract:
Let me think of variables:
let enemyDirection = 1; // 1 for right, -1 for leftIn the game loop:
enemies.forEach(enemy => {> enemy.x += enemyDirection * enemy.dx;> });Then check if any enemy is out of bounds. If so, reverse direction and move all enemies down.But how to check if any enemy is at the edge?
Maybe find the max x of all enemies and see if it exceeds
canvas.width - enemy.width.Alternatively, track the leftmost and rightmost positions of enemies. Maybe a bit complex.
For simplicity, perhaps check if any enemy's
x + width > canvas.width or x < 0.
Here's the full transcript.
My initial impressions are that I'm not as impressed with this model for running on my own laptop as I was with Qwen3-Coder-30B-A3B-Instruct or GLM-4.5 Air.
But... how extraordinary is it that another Chinese AI lab has been able to produce a competitive model, this time with far less fanfare than we've seen from Qwen and Moonshot AI and Z.ai.
Deep Think in the Gemini app (via) Google released Gemini 2.5 Deep Think this morning, exclusively to their Ultra ($250/month) subscribers:
It is a variation of the model that recently achieved the gold-medal standard at this year's International Mathematical Olympiad (IMO). While that model takes hours to reason about complex math problems, today's release is faster and more usable day-to-day, while still reaching Bronze-level performance on the 2025 IMO benchmark, based on internal evaluations.
Google describe Deep Think's architecture like this:
Just as people tackle complex problems by taking the time to explore different angles, weigh potential solutions, and refine a final answer, Deep Think pushes the frontier of thinking capabilities by using parallel thinking techniques. This approach lets Gemini generate many ideas at once and consider them simultaneously, even revising or combining different ideas over time, before arriving at the best answer.
This approach sounds a little similar to the llm-consortium plugin by Thomas Hughes, see this video from January's Datasette Public Office Hours.
I don't have an Ultra account, but thankfully nickandbro on Hacker News tried "Create a svg of a pelican riding on a bicycle" (a very slight modification of my prompt, which uses "Generate an SVG") and got back a very solid result:

The bicycle is the right shape, and this is one of the few results I've seen for this prompt where the bird is very clearly a pelican thanks to the shape of its beak.
There are more details on Deep Think in the Gemini 2.5 Deep Think Model Card (PDF). Some highlights from that document:
- 1 million token input window, accepting text, images, audio, and video.
- Text output up to 192,000 tokens.
- Training ran on TPUs and used JAX and ML Pathways.
- "We additionally trained Gemini 2.5 Deep Think on novel reinforcement learning techniques that can leverage more multi-step reasoning, problem-solving and theorem-proving data, and we also provided access to a curated corpus of high-quality solutions to mathematics problems."
- Knowledge cutoff is January 2025.
Gemini Deep Think, our SOTA model with parallel thinking that won the IMO Gold Medal 🥇, is now available in the Gemini App for Ultra subscribers!! [...]
Quick correction: this is a variation of our IMO gold model that is faster and more optimized for daily use! We are also giving the IMO gold full model to a set of mathematicians to test the value of the full capabilities.
— Logan Kilpatrick, announcing Gemini Deep Think
Here are a few more model releases from today, to round out a very busy July:
- Cohere released Command A Vision, their first multi-modal (image input) LLM. Like their others it's open weights under Creative Commons Attribution Non-Commercial, so you need to license it (or use their paid API) if you want to use it commercially.
- San Francisco AI startup Deep Cogito released four open weights hybrid reasoning models, cogito-v2-preview-deepseek-671B-MoE, cogito-v2-preview-llama-405B, cogito-v2-preview-llama-109B-MoE and cogito-v2-preview-llama-70B. These follow their v1 preview models in April at smaller 3B, 8B, 14B, 32B and 70B sizes. It looks like their unique contribution here is "distilling inference-time reasoning back into the model’s parameters" - demonstrating a form of self-improvement. I haven't tried any of their models myself yet.
- Mistral released Codestral 25.08, an update to their Codestral model which is specialized for fill-in‑the‑middle autocomplete as seen in text editors like VS Code, Zed and Cursor.
- And an anonymous stealth preview model called Horizon Alpha running on OpenRouter was released yesterday and is attracting a lot of attention.
Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM
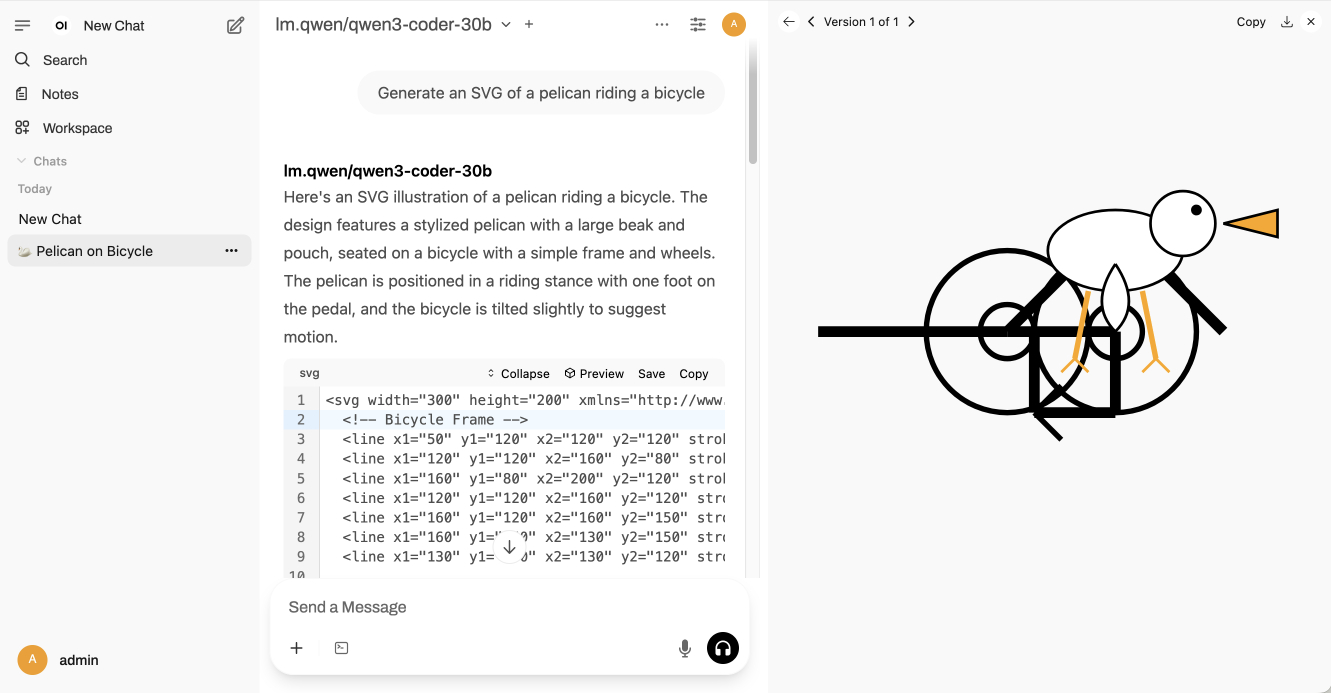
Qwen just released their sixth model(!) of this July called Qwen3-Coder-30B-A3B-Instruct—listed as Qwen3-Coder-Flash in their chat.qwen.ai interface.
[... 1,390 words]Qwen3-30B-A3B-Thinking-2507 (via) Yesterday was Qwen3-30B-A3B-Instruct-2507. Qwen are clearly committed to their new split between reasoning and non-reasoning models (a reversal from Qwen 3 in April), because today they released the new reasoning partner to yesterday's model: Qwen3-30B-A3B-Thinking-2507.
I'm surprised at how poorly this reasoning mode performs at "Generate an SVG of a pelican riding a bicycle" compared to its non-reasoning partner. The reasoning trace appears to carefully consider each component and how it should be positioned... and then the final result looks like this:
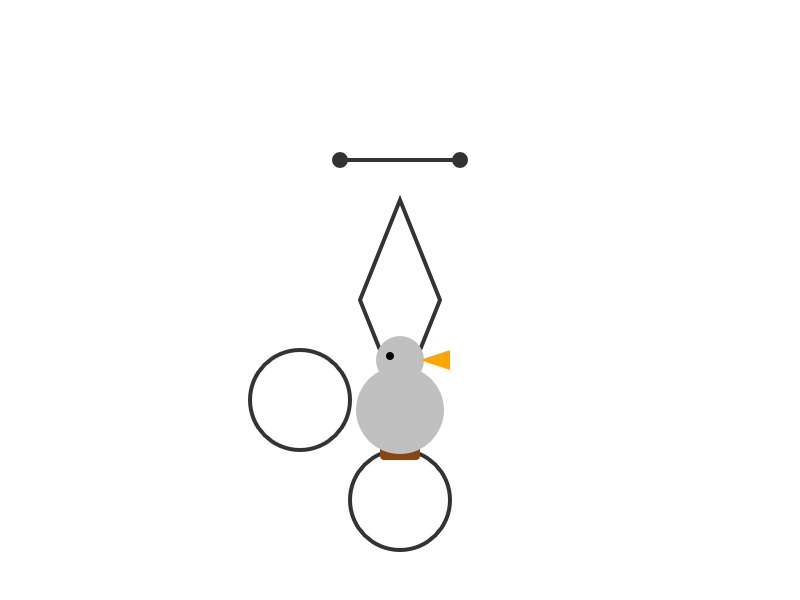
I ran this using chat.qwen.ai/?model=Qwen3-30B-A3B-2507 with the "reasoning" option selected.
I also tried the "Write an HTML and JavaScript page implementing space invaders" prompt I ran against the non-reasoning model. It did a better job in that the game works:
It's not as playable as the on I got from GLM-4.5 Air though - the invaders fire their bullets infrequently enough that the game isn't very challenging.
This model is part of a flurry of releases from Qwen over the past two 9 days. Here's my coverage of each of those:
- Qwen3-235B-A22B-Instruct-2507 - 21st July
- Qwen3-Coder-480B-A35B-Instruct - 22nd July
- Qwen3-235B-A22B-Thinking-2507 - 25th July
- Qwen3-30B-A3B-Instruct-2507 - 29th July
- Qwen3-30B-A3B-Thinking-2507 - today