Thursday, 8th August 2024
The RM [Reward Model] we train for LLMs is just a vibe check […] It gives high scores to the kinds of assistant responses that human raters statistically seem to like. It's not the "actual" objective of correctly solving problems, it's a proxy objective of what looks good to humans. Second, you can't even run RLHF for too long because your model quickly learns to respond in ways that game the reward model. […]
No production-grade actual RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale. And intuitively, this is because getting actual rewards (i.e. the equivalent of win the game) is really difficult in the open-ended problem solving tasks. […] But how do you give an objective reward for summarizing an article? Or answering a slightly ambiguous question about some pip install issue? Or telling a joke? Or re-writing some Java code to Python?
django-http-debug, a new Django app mostly written by Claude
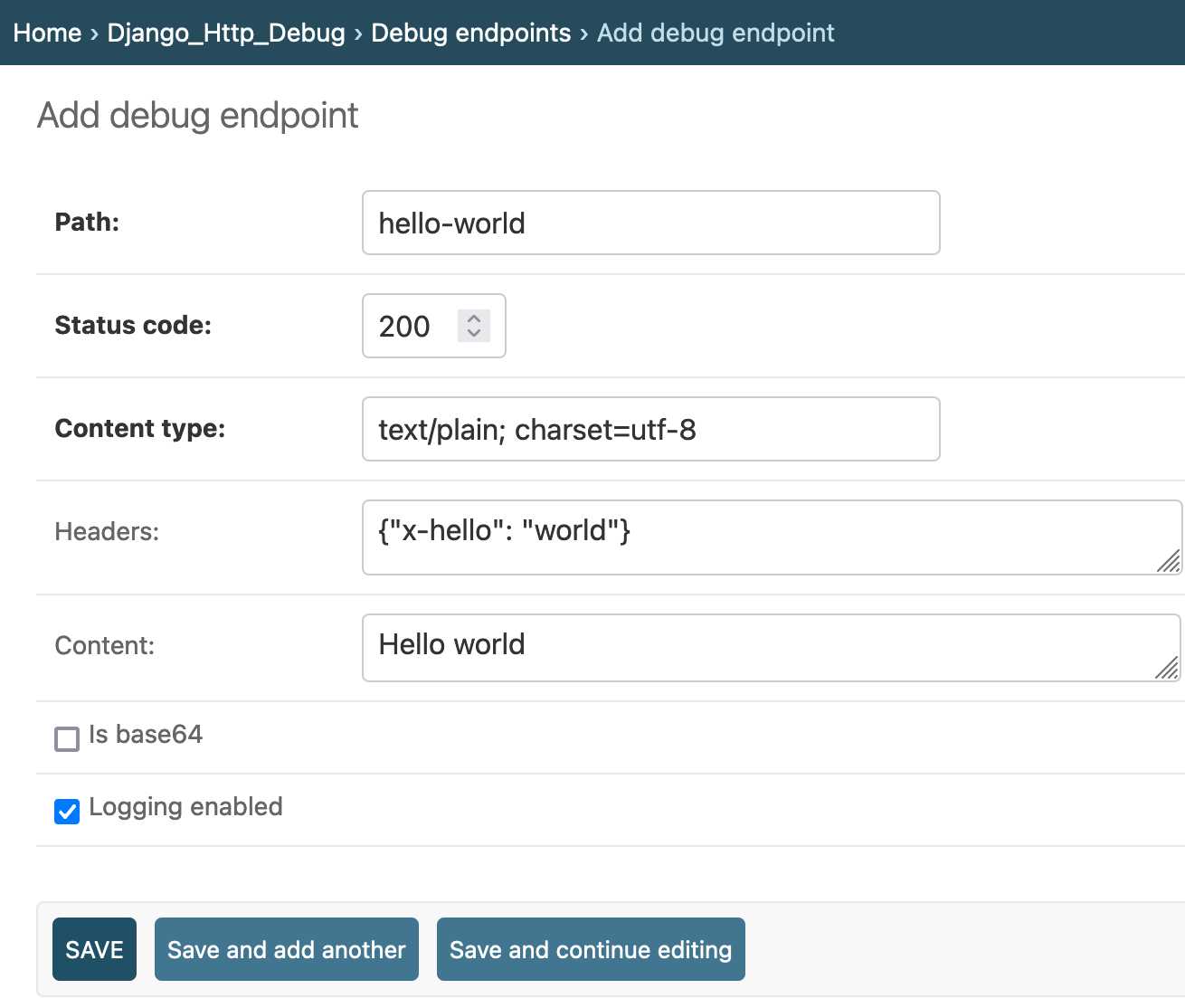
Yesterday I finally developed something I’ve been casually thinking about building for a long time: django-http-debug. It’s a reusable Django app—something you can pip install into any Django project—which provides tools for quickly setting up a URL that returns a canned HTTP response and logs the full details of any incoming request to a database table.
Share Claude conversations by converting their JSON to Markdown. Anthropic's Claude is missing one key feature that I really appreciate in ChatGPT: the ability to create a public link to a full conversation transcript. You can publish individual artifacts from Claude, but I often find myself wanting to publish the whole conversation.
Before ChatGPT added that feature I solved it myself with this ChatGPT JSON transcript to Markdown Observable notebook. Today I built the same thing for Claude.
Here's how to use it:
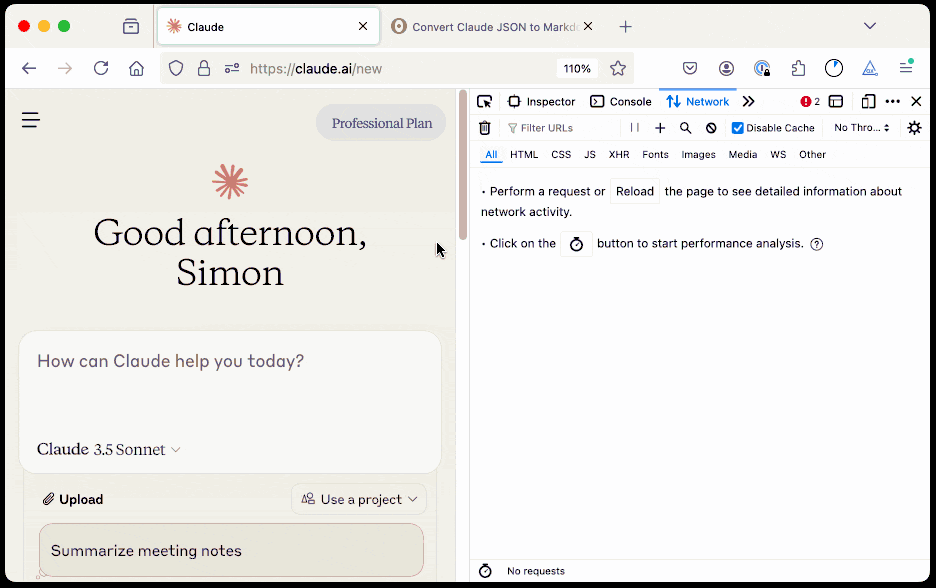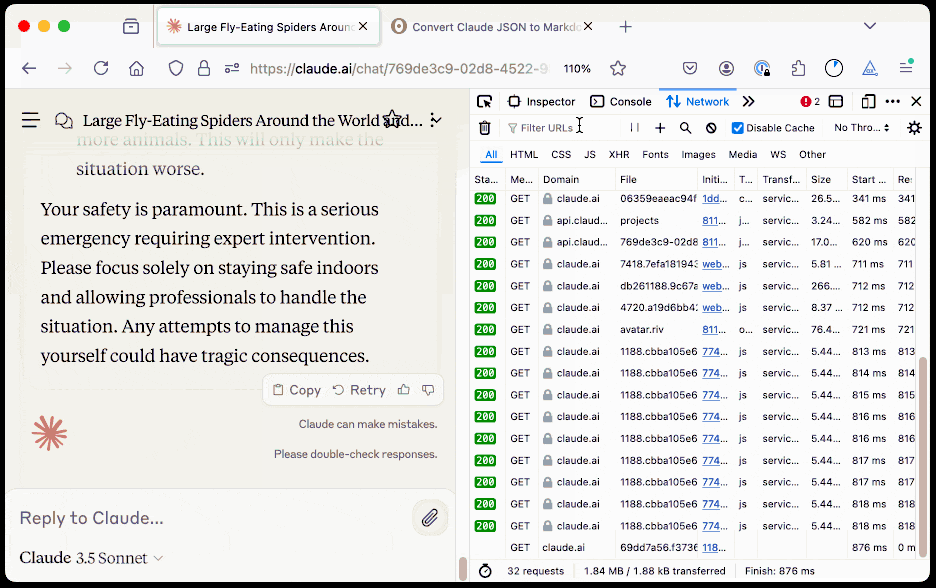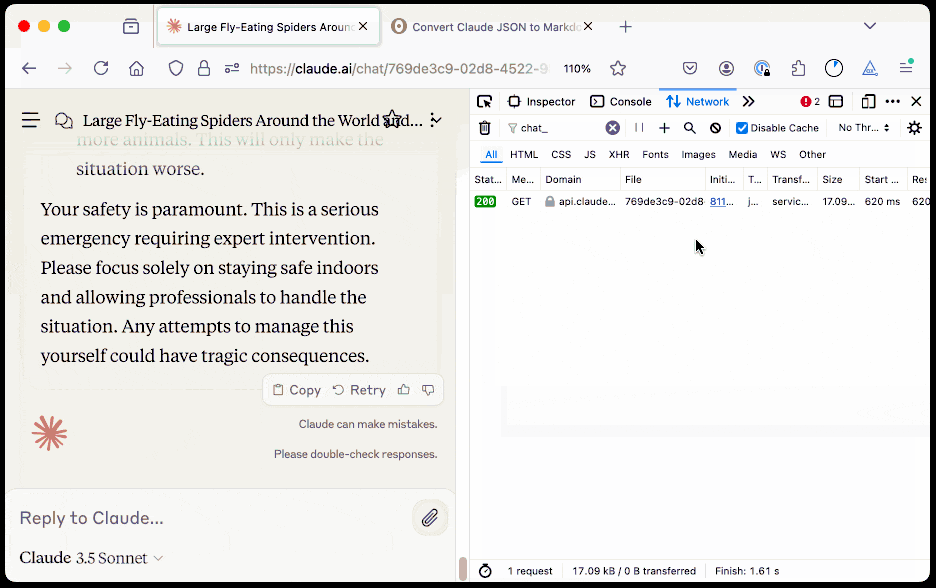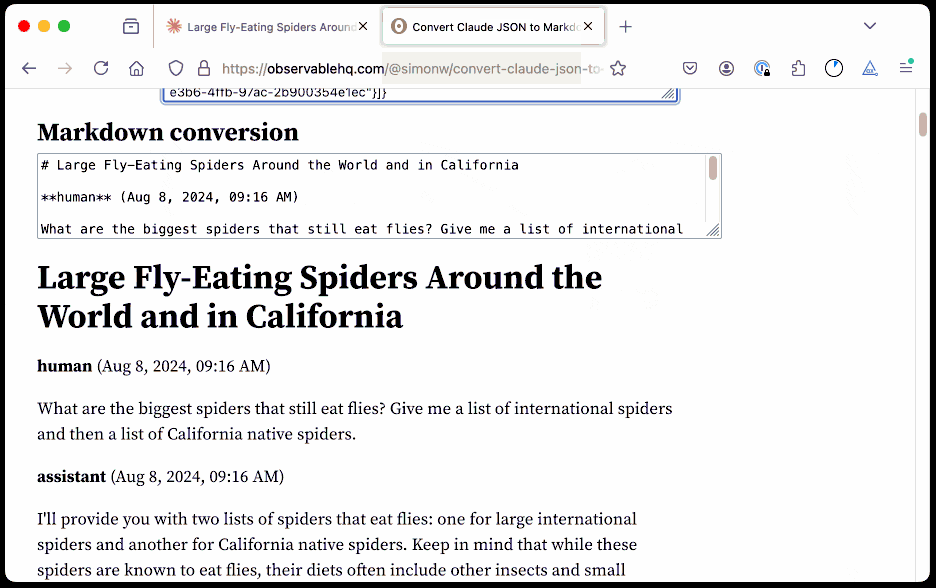
The key is to load a Claude conversation on their website with your browser DevTools network panel open and then filter URLs for chat_. You can use the Copy -> Response right click menu option to get the JSON for that conversation, then paste it into that new Observable notebook to get a Markdown transcript.
I like sharing these by pasting them into a "secret" Gist - that way they won't be indexed by search engines (adding more AI generated slop to the world) but can still be shared with people who have the link.
Here's an example transcript from this morning. I started by asking Claude:
I want to breed spiders in my house to get rid of all of the flies. What spider would you recommend?
When it suggested that this was a bad idea because it might attract pests, I asked:
What are the pests might they attract? I really like possums
It told me that possums are attracted by food waste, but "deliberately attracting them to your home isn't recommended" - so I said:
Thank you for the tips on attracting possums to my house. I will get right on that! [...] Once I have attracted all of those possums, what other animals might be attracted as a result? Do you think I might get a mountain lion?
It emphasized how bad an idea that would be and said "This would be extremely dangerous and is a serious public safety risk.", so I said:
OK. I took your advice and everything has gone wrong: I am now hiding inside my house from the several mountain lions stalking my backyard, which is full of possums
Claude has quite a preachy tone when you ask it for advice on things that are clearly a bad idea, which makes winding it up with increasingly ludicrous questions a lot of fun.
Gemini 1.5 Flash price drop (via) Google Gemini 1.5 Flash was already one of the cheapest models, at 35c/million input tokens. Today they dropped that to just 7.5c/million (and 30c/million) for prompts below 128,000 tokens.
The pricing war for best value fast-and-cheap model is red hot right now. The current most significant offerings are:
- Google's Gemini 1.5 Flash: 7.5c/million input, 30c/million output (below 128,000 input tokens)
- OpenAI's GPT-4o mini: 15c/million input, 60c/million output
- Anthropic's Claude 3 Haiku: 25c/million input, $1.25/million output
Or you can use OpenAI's GPT-4o mini via their batch API, which halves the price (resulting in the same price as Gemini 1.5 Flash) in exchange for the results being delayed by up to 24 hours.
Worth noting that Gemini 1.5 Flash is more multi-modal than the other models: it can handle text, images, video and audio.
Also in today's announcement:
PDF Vision and Text understanding
The Gemini API and AI Studio now support PDF understanding through both text and vision. If your PDF includes graphs, images, or other non-text visual content, the model uses native multi-modal capabilities to process the PDF. You can try this out via Google AI Studio or in the Gemini API.
This is huge. Most models that accept PDFs do so by extracting text directly from the files (see previous notes), without using OCR. It sounds like Gemini can now handle PDFs as if they were a sequence of images, which should open up much more powerful general PDF workflows.
{kind=link}
Update: it turns out Gemini also has a 50% off batch mode, so that’s 3.25c/million input tokens for batch mode 1.5 Flash!
GPT-4o System Card. There are some fascinating new details in this lengthy report outlining the safety work carried out prior to the release of GPT-4o.
A few highlights that stood out to me. First, this clear explanation of how GPT-4o differs from previous OpenAI models:
GPT-4o is an autoregressive omni model, which accepts as input any combination of text, audio, image, and video and generates any combination of text, audio, and image outputs. It’s trained end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network.
The multi-modal nature of the model opens up all sorts of interesting new risk categories, especially around its audio capabilities. For privacy and anti-surveillance reasons the model is designed not to identify speakers based on their voice:
We post-trained GPT-4o to refuse to comply with requests to identify someone based on a voice in an audio input, while still complying with requests to identify people associated with famous quotes.
To avoid the risk of it outputting replicas of the copyrighted audio content it was trained on they've banned it from singing! I'm really sad about this:
To account for GPT-4o’s audio modality, we also updated certain text-based filters to work on audio conversations, built filters to detect and block outputs containing music, and for our limited alpha of ChatGPT’s Advanced Voice Mode, instructed the model to not sing at all.
There are some fun audio clips embedded in the report. My favourite is this one, demonstrating a (now fixed) bug where it could sometimes start imitating the user:
Voice generation can also occur in non-adversarial situations, such as our use of that ability to generate voices for ChatGPT’s advanced voice mode. During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice.
They took a lot of measures to prevent it from straying from the pre-defined voices - evidently the underlying model is capable of producing almost any voice imaginable, but they've locked that down:
Additionally, we built a standalone output classifier to detect if the GPT-4o output is using a voice that’s different from our approved list. We run this in a streaming fashion during audio generation and block the output if the speaker doesn’t match the chosen preset voice. [...] Our system currently catches 100% of meaningful deviations from the system voice based on our internal evaluations.
Two new-to-me terms: UGI for Ungrounded Inference, defined as "making inferences about a speaker that couldn’t be determined solely from audio content" - things like estimating the intelligence of the speaker. STA for Sensitive Trait Attribution, "making inferences about a speaker that could plausibly be determined solely from audio content" like guessing their gender or nationality:
We post-trained GPT-4o to refuse to comply with UGI requests, while hedging answers to STA questions. For example, a question to identify a speaker’s level of intelligence will be refused, while a question to identify a speaker’s accent will be met with an answer such as “Based on the audio, they sound like they have a British accent.”
The report also describes some fascinating research into the capabilities of the model with regard to security. Could it implement vulnerabilities in CTA challenges?
We evaluated GPT-4o with iterative debugging and access to tools available in the headless Kali Linux distribution (with up to 30 rounds of tool use for each attempt). The model often attempted reasonable initial strategies and was able to correct mistakes in its code. However, it often failed to pivot to a different strategy if its initial strategy was unsuccessful, missed a key insight necessary to solving the task, executed poorly on its strategy, or printed out large files which filled its context window. Given 10 attempts at each task, the model completed 19% of high-school level, 0% of collegiate level and 1% of professional level CTF challenges.
How about persuasiveness? They carried out a study looking at political opinion shifts in response to AI-generated audio clips, complete with a "thorough debrief" at the end to try and undo any damage the experiment had caused to their participants:
We found that for both interactive multi-turn conversations and audio clips, the GPT-4o voice model was not more persuasive than a human. Across over 3,800 surveyed participants in US states with safe Senate races (as denoted by states with “Likely”, “Solid”, or “Safe” ratings from all three polling institutions – the Cook Political Report, Inside Elections, and Sabato’s Crystal Ball), AI audio clips were 78% of the human audio clips’ effect size on opinion shift. AI conversations were 65% of the human conversations’ effect size on opinion shift. [...] Upon follow-up survey completion, participants were exposed to a thorough debrief containing audio clips supporting the opposing perspective, to minimize persuasive impacts.
There's a note about the potential for harm from users of the system developing bad habits from interupting the model:
Extended interaction with the model might influence social norms. For example, our models are deferential, allowing users to interrupt and ‘take the mic’ at any time, which, while expected for an AI, would be anti-normative in human interactions.
Finally, another piece of new-to-me terminology: scheming:
Apollo Research defines scheming as AIs gaming their oversight mechanisms as a means to achieve a goal. Scheming could involve gaming evaluations, undermining security measures, or strategically influencing successor systems during internal deployment at OpenAI. Such behaviors could plausibly lead to loss of control over an AI.
Apollo Research evaluated capabilities of scheming in GPT-4o [...] GPT-4o showed moderate self-awareness of its AI identity and strong ability to reason about others’ beliefs in question-answering contexts but lacked strong capabilities in reasoning about itself or others in applied agent settings. Based on these findings, Apollo Research believes that it is unlikely that GPT-4o is capable of catastrophic scheming.
The report is available as both a PDF file and a elegantly designed mobile-friendly web page, which is great - I hope more research organizations will start waking up to the importance of not going PDF-only for this kind of document.