10 posts tagged “translation”
2026
Speech translation in Google Meet is now rolling out to mobile devices. I just encountered this feature via a "try this out now" prompt in a Google Meet meeting. It kind-of worked!
This is Google's implementation of the ultimate sci-fi translation app, where two people can talk to each other in two separate languages and Meet translates from one to the other and - with a short delay - repeats the text in your preferred language, with a rough imitation of the original speaker's voice.
It can only handle English, Spanish, French, German, Portuguese, and Italian at the moment. It's also still very alpha - I ran it successfully between two laptops running web browsers, but then when I tried between an iPhone and an iPad it didn't seem to work.
2025
Shisa V2 405B: Japan’s Highest Performing LLM. Leonard Lin and Adam Lensenmayer have been working on Shisa for a while. They describe their latest release as "Japan's Highest Performing LLM".
Shisa V2 405B is the highest-performing LLM ever developed in Japan, and surpasses GPT-4 (0603) and GPT-4 Turbo (2024-04-09) in our eval battery. (It also goes toe-to-toe with GPT-4o (2024-11-20) and DeepSeek-V3 (0324) on Japanese MT-Bench!)
This 405B release is a follow-up to the six smaller Shisa v2 models they released back in April, which took a similar approach to DeepSeek-R1 in producing different models that each extended different existing base model from Llama, Qwen, Mistral and Phi-4.
The new 405B model uses Llama 3.1 405B Instruct as a base, and is available under the Llama 3.1 community license.
Shisa is a prominent example of Sovereign AI - the ability for nations to build models that reflect their own language and culture:
We strongly believe that it’s important for homegrown AI to be developed both in Japan (and globally!), and not just for the sake of cultural diversity and linguistic preservation, but also for data privacy and security, geopolitical resilience, and ultimately, independence.
We believe the open-source approach is the only realistic way to achieve sovereignty in AI, not just for Japan, or even for nation states, but for the global community at large.
The accompanying overview report has some fascinating details:
Training the 405B model was extremely difficult. Only three other groups that we know of: Nous Research, Bllossom, and AI2 have published Llama 405B full fine-tunes. [...] We implemented every optimization at our disposal including: DeepSpeed ZeRO-3 parameter and activation offloading, gradient accumulation, 8-bit paged optimizer, and sequence parallelism. Even so, the 405B model still barely fit within the H100’s memory limits
In addition to the new model the Shisa team have published shisa-ai/shisa-v2-sharegpt, 180,000 records which they describe as "a best-in-class synthetic dataset, freely available for use to improve the Japanese capabilities of any model. Licensed under Apache 2.0".
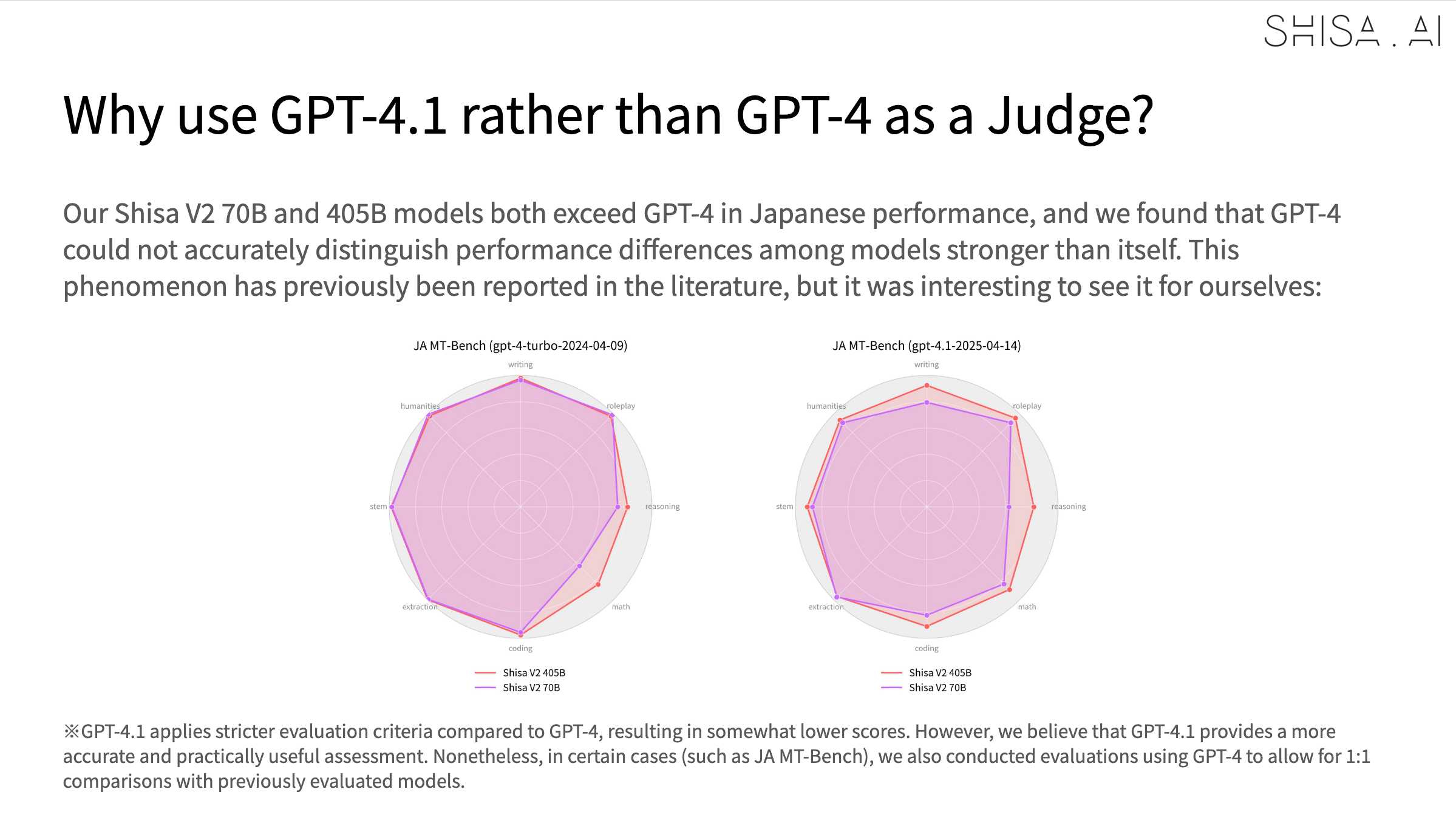
An interesting note is that they found that since Shisa out-performs GPT-4 at Japanese that model was no longer able to help with evaluation, so they had to upgrade to GPT-4.1:
A professional workflow for translation using LLMs. Tom Gally is a professional translator who has been exploring the use of LLMs since the release of GPT-4. In this Hacker News comment he shares a detailed workflow for how he uses them to assist in that process.
Tom starts with the source text and custom instructions, including context for how the translation will be used. Here's an imaginary example prompt, which starts:
The text below in Japanese is a product launch presentation for Sony's new gaming console, to be delivered by the CEO at Tokyo Game Show 2025. Please translate it into English. Your translation will be used in the official press kit and live interpretation feed. When translating this presentation, please follow these guidelines to create an accurate and engaging English version that preserves both the meaning and energy of the original: [...]
It then lists some tone, style and content guidelines custom to that text.
Tom runs that prompt through several different LLMs and starts by picking sentences and paragraphs from those that form a good basis for the translation.
As he works on the full translation he uses Claude to help brainstorm alternatives for tricky sentences:
When I am unable to think of a good English version for a particular sentence, I give the Japanese and English versions of the paragraph it is contained in to an LLM (usually, these days, Claude) and ask for ten suggestions for translations of the problematic sentence. Usually one or two of the suggestions work fine; if not, I ask for ten more. (Using an LLM as a sentence-level thesaurus on steroids is particularly wonderful.)
He uses another LLM and prompt to check his translation against the original and provide further suggestions, which he occasionally acts on. Then as a final step he runs the finished document through a text-to-speech engine to try and catch any "minor awkwardnesses" in the result.
I love this as an example of an expert using LLMs as tools to help further elevate their work. I'd love to read more examples like this one from experts in other fields.
OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]2024
One consideration is that such a deep ML system could well be developed outside of Google-- at Microsoft, Baidu, Yandex, Amazon, Apple, or even a startup. My impression is that the Translate team experienced this. Deep ML reset the translation game; past advantages were sort of wiped out. Fortunately, Google's huge investment in deep ML largely paid off, and we excelled in this new game. Nevertheless, our new ML-based translator was still beaten on benchmarks by a small startup. The risk that Google could similarly be beaten in relevance by another company is highlighted by a startling conclusion from BERT: huge amounts of user feedback can be largely replaced by unsupervised learning from raw text. That could have heavy implications for Google.
— Eric Lehman, internal Google email in 2018
2023
Seamless Communication (via) A new “family of AI research models” from Meta AI for speech and text translation. The live demo is particularly worth trying—you can record a short webcam video of yourself speaking and get back the same video with your speech translated into another language.
The key to it is the new SeamlessM4T v2 model, which supports 101 languages for speech input, 96 Languages for text input/output and 35 languages for speech output. SeamlessM4T-Large v2 is a 9GB file, available on Hugging Face.
Also in this release: SeamlessExpressive, which “captures certain underexplored aspects of prosody such as speech rate and pauses”—effectively maintaining things like expressed enthusiasm across languages.
Plus SeamlessStreaming, “a model that can deliver speech and text translations with around two seconds of latency”.
Introducing speech-to-text, text-to-speech, and more for 1,100+ languages (via) New from Meta AI: Massively Multilingual Speech. “MMS supports speech-to-text and text-to-speech for 1,107 languages and language identification for over 4,000 languages. [...] Some of these, such as the Tatuyo language, have only a few hundred speakers, and for most of these languages, no prior speech technology exists.”
It’s licensed CC-BY-NC 4.0 though, so it’s not available for commercial use.
“In a like-for-like comparison with OpenAI’s Whisper, we found that models trained on the Massively Multilingual Speech data achieve half the word error rate, but Massively Multilingual Speech covers 11 times more languages.”
The training data was mostly sourced from audio Bible translations.
2007
Google Translate (beta). Google’s beta translator based on statistical analysis of things like the United Nations corpus. I have no idea how long this has been available; it isn’t linked from their homepage.
Django-fr. Community site for French language Django developers. They’ve already made a promising start on translating the documentation.
2006
Comment transformer votre blog en une OpenID ? My piece on OpenID tranlated in to French by Christophe Ducamp.