Notes
Filters: Sorted by date
Quitting programming as a career right now because of LLMs would be like quitting carpentry as a career thanks to the invention of the table saw.
Sometimes a service with a free plan will decide to stop supporting it. I understand why this happens, but I'm often disappointed at the treatment of existing user's data. It's easy to imagine users forgetting about their old accounts, missing the relevant emails and then discovering too late that their data is gone.
Inspired by today's news about PlanetScale PostgreSQL I signed into PlanetScale and found I had a long-forgotten trial account there with a three-year-old database on their free tier. That free tier was retired in March 2024.
Here's the screen that greeted me in their control panel:
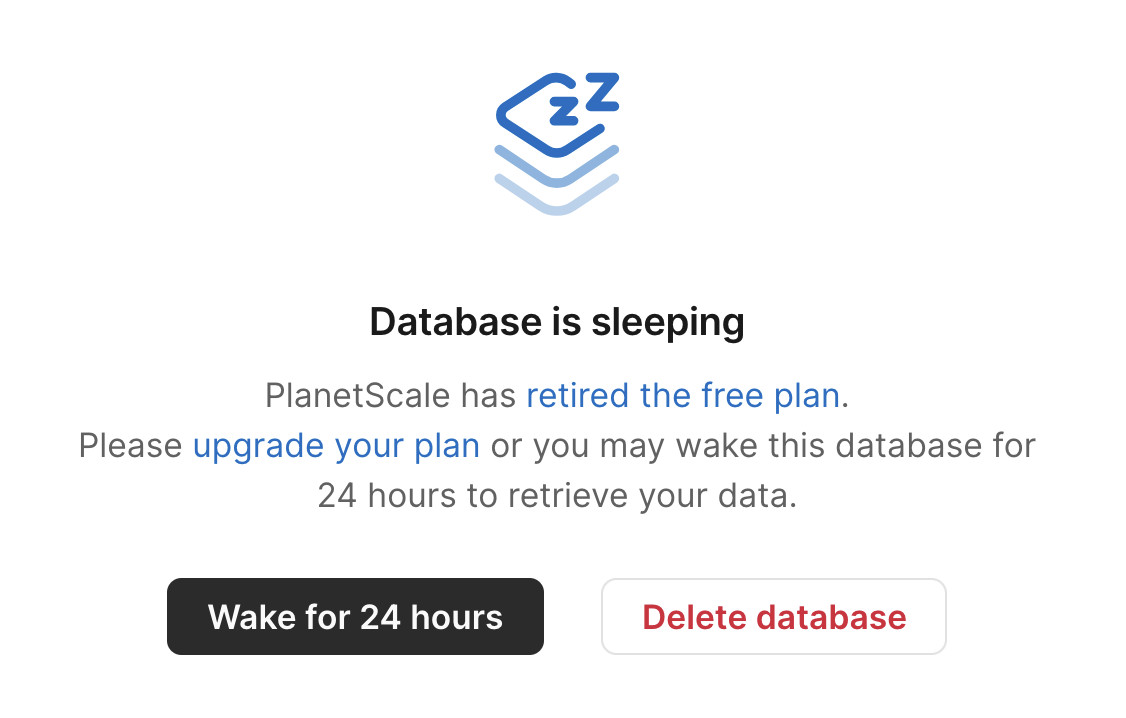
What a great way to handle retiring a free plan! My data is still there, and I have the option to spin up a database for 24 hours to help get it back out again.
Using LLMs for code archaeology is pretty fun.
I stumbled across this blog entry from 2003 today, in which I had gotten briefly excited about ColdFusion and implemented an experimental PHP template engine that used XML tags to achieve a similar effect:
<h1>%title%</h1> <sql id="recent"> select title from entries order by added desc limit 0, %limit% </sql> <ul> <output sql="recent"> <li>%title%</li> </output> </ul>
I'd completely forgotten about this, and in scanning through the PHP it looked like it had extra features that I hadn't described in the post.
So... I fed my 22 year old TemplateParser.class.php file into Claude and prompted:
Write detailed markdown documentation for this template language
Here's the resulting documentation. It's pretty good, but the highlight was the Claude transcript which concluded:
This appears to be a custom template system from the mid-2000s era, designed to separate presentation logic from PHP code while maintaining database connectivity for dynamic content generation.
Mid-2000s era indeed!
I just sent out the second edition of my sponsors only monthly newsletter. Anyone who sponsors me for $10/month or more on GitHub gets this carefully hand-curated summary of the last month in AI/LLMs/my projects designed to be readable in ten minutes or less.
My regular newsletter remains free - the monthly one is the only paywalled content I produce, the idea being that you can pay me to send you less.
Here's the first edition for May 2025 as a preview of what you can expect. You'll get access to the June digest and the full archive automatically if you decide to start sponsoring.
The term context engineering has recently started to gain traction as a better alternative to prompt engineering. I like it. I think this one may have sticking power.
Here's an example tweet from Shopify CEO Tobi Lutke:
I really like the term “context engineering” over prompt engineering.
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
Recently amplified by Andrej Karpathy:
+1 for "context engineering" over "prompt engineering".
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting [...] Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits. [...]
I've spoken favorably of prompt engineering in the past - I hoped that term could capture the inherent complexity of constructing reliable prompts. Unfortunately, most people's inferred definition is that it's a laughably pretentious term for typing things into a chatbot!
It turns out that inferred definitions are the ones that stick. I think the inferred definition of "context engineering" is likely to be much closer to the intended meaning.
Yesterday Anthropic got a bunch of buzz out of their new window.claude.complete() API which allows Claude Artifacts to run their own API calls to execute prompts.
It turns out Gemini had beaten them to that feature by over a month, but the announcement was tucked away in a bullet point of their release notes for the 20th of May:
Vibe coding apps in Canvas just got better too! With just a few prompts, you can now build fully functional personalised apps in Canvas that can use Gemini-powered features, save data between sessions and share data between multiple users.
Ethan Mollick has been building some neat demos on top of Gemini Canvas, including this text adventure starship bridge simulator.
Similar to Claude Artifacts, Gemini Canvas detects if the application uses APIs that require authentication (to run prompts, for example) and requests the user sign in with their Google account:
![Futuristic sci-fi interface screenshot showing "Helm Control" at top with navigation buttons for Helm, Comms, Science, Tactical, Engineering, and Operations, displaying red error message "[SYSTEM_ERROR] Connection to AI core failed: API error: 403. This may be an authentication issue." with command input field showing "Enter command..." and Send button, plus Google Account sign-in notification at bottom stating "You need to sign in with your Google Account to see some features" with Sign in button and X close icon](https://static.simonwillison.net/static/2025/gemini-auth.jpg)
Two interesting new products for running code in a sandbox today.
Cloudflare launched their Containers product in open beta, and added a new Sandbox library for Cloudflare Workers that can run commands in a "secure, container-based environment":
import { getSandbox } from "@cloudflare/sandbox";
const sandbox = getSandbox(env.Sandbox, "my-sandbox");
const output = sandbox.exec("ls", ["-la"]);Vercel shipped a similar feature, introduced in Run untrusted code with Vercel Sandbox, which enables code that looks like this:
import { Sandbox } from "@vercel/sandbox";
const sandbox = await Sandbox.create();
await sandbox.writeFiles([
{ path: "script.js", stream: Buffer.from(result.text) },
]);
await sandbox.runCommand({
cmd: "node",
args: ["script.js"],
stdout: process.stdout,
stderr: process.stderr,
});In both cases a major intended use-case is safely executing code that has been created by an LLM.
I've added a Disclosures section to my about page, listing my various sources of income and the companies that directly sponsor my work or have supported it in the recent past.
I do not receive any compensation writing about specific topics on this blog - no sponsored content! I plan to continue this policy. If I ever change this I will disclose that both here and in the post itself. [...]
I see my credibility as one of my most valuable assets, so it's important to be transparent about how financial interests may influence my writing here.
I took inspiration from Molly White's disclosures page.
Here's a tip that works on YouTube and almost any other web page that shows you a video. You can increase the playback rate beyond the usually-exposed 2x by running this in your browser DevTools console:
document.querySelector('video').playbackRate = 2.5
I find this is the fastest I can reasonably watch most videos at, with subtitles on to help my comprehension - it turns a 40 minute video into just 16 minutes, short enough that I don't feel too guilty taking time off whatever else I'm doing to watch it!
I continue to have fun running fantasy cooking prompts through LLMs - this time I tried "Give me a wildly ambitious recipe for zucchini cooked three ways" followed by "Go more ambitious" and now I need to get myself a centrifuge to help spherify my clarified zucchini consommé.
I wrote this recently in a conversation about whether coding agents can work as a replacement for human programmers.
The "agentic" coding tools we have right now work like this:
- A skilled individual with both deep domain understanding and deep understanding of the capabilities of the agent (including understanding what tools are available to that agent) poses a clear task to it.
- The agent writes some code relating to that task. It runs a tool to execute and test that code. It inspects the result, and if there are errors it edits the code and tries again.
- It may call other tools as well, for example a search tool to find related code or even to look up API documentation elsewhere (including via web search).
- It continues like this until it hits a loosely defined “done” state or gets stuck.
- The skilled individual then reviews what it has done and almost always finds that it has not solved the problem to their satisfaction... so they apply their expertise and domain understanding to prompt it again to try and get to that desired state.
Without the skilled individual, the “agent” is useless. It may as well not exist.
That memvid thing that's been going around recently is a trap. It's an embedding store that records the original text that has been embedded in QR codes in a video file. That's an absurd thing to do, and the only purpose of the repo is to make people who uncritically share it look foolish. Don't fall for the trap.
Every time I get into an online conversation about prompt injection it's inevitable that someone will argue that a mitigation which works 99% of the time is still worthwhile because there's no such thing as a security fix that is 100% guaranteed to work.
I don't think that's true.
If I use parameterized SQL queries my systems are 100% protected against SQL injection attacks.
If I make a mistake applying those and someone reports it to me I can fix that mistake and now I'm back up to 100%.
If our measures against SQL injection were only 99% effective none of our digital activities involving relational databases would be safe.
I don't think it is unreasonable to want a security fix that, when applied correctly, works 100% of the time.
(I first argued a version of this back in September 2022 in You can’t solve AI security problems with more AI.)
My post this morning about Design Patterns for Securing LLM Agents against Prompt Injections is an example of a blogging format I'd love to see more of: informal but informed commentary on academic papers.
Academic papers are generally hard to read. Sadly that's almost a requirement of the format: the incentives for publishing papers that make it through peer review are often at odds with producing text that's easy for non-academics to digest.
(This new Design Patterns paper bucks that trend, the writing is clear, it’s enjoyable to read and the target audience clearly includes practitioners, not just other researchers.)
In addition to breaking a paper down into more digestible chunks, writing about papers offers an extremely valuable filter. There are hundreds of new papers published every day: seeing someone who's work you respect confirm that a paper is worth your time is a really strong signal.
I added a paper-review tag this morning, gathering six posts where I’ve attempted this kind of review. Notes on the SQLite DuckDB paper in September 2022 was my first.
I apply the same principle to these as my link blog: try to add something extra, so that anyone who reads both my post and the paper itself gets a little bit of extra value from my notes.
It's this blog's 23rd birthday today!
On June 12th 2022 I celebrated Twenty years of my blog with a big post full of highlights. Looking back now I'm amused to notice that my 20th birthday post came within two weeks of my earliest writing about LLMs: A Datasette tutorial written by GPT-3 and How to use the GPT-3 language model.
My generative-ai tag has reached 1,184 posts now.
I really do feel like blogging is onto its second wind. The amount of influence you can have on the world by consistently blogging about a subject is just as high today as it was back in the 2000s when blogging first started.
The best time to start a blog may have been twenty years ago, but the second best time to start a blog is today.
OpenAI just dropped the price of their o3 model by 80% - from $10/million input tokens and $40/million output tokens to just $2/million and $8/million for the very same model. This is in advance of the release of o3-pro which apparently is coming later today (update: here it is).
This is a pretty huge shake-up in LLM pricing. o3 is now priced the same as GPT 4.1, and slightly less than GPT-4o ($2.50/$10). It’s also less than Anthropic’s Claude Sonnet 4 ($3/$15) and Opus 4 ($15/$75) and sits in between Google’s Gemini 2.5 Pro for >200,00 tokens ($2.50/$15) and 2.5 Pro for <200,000 ($1.25/$10).
I’ve updated my llm-prices.com pricing calculator with the new rate.
How have they dropped the price so much? OpenAI's Adam Groth credits ongoing optimization work:
thanks to the engineers optimizing inferencing.
Solomon Hykes just presented the best definition of an AI agent I've seen yet, on stage at the AI Engineer World's Fair:

An AI agent is an LLM wrecking its environment in a loop.
I collect AI agent definitions and I really like this how this one combines the currently popular "tools in a loop" one (see Anthropic) with the classic academic definition that I think dates back to at least the 90s:
An agent is something that acts in an environment; it does something. Agents include worms, dogs, thermostats, airplanes, robots, humans, companies, and countries.
We're hosting the sixth in our series of Datasette Public Office Hours livestream sessions this Friday, 6th of June at 2pm PST (here's that time in your location).
The topic is going to be tool support in LLM, as introduced here.
I'll be walking through the new features, and we're also inviting five minute lightning demos from community members who are doing fun things with the new capabilities. If you'd like to present one of those please get in touch via this form.

Here's a link to add it to Google Calendar.
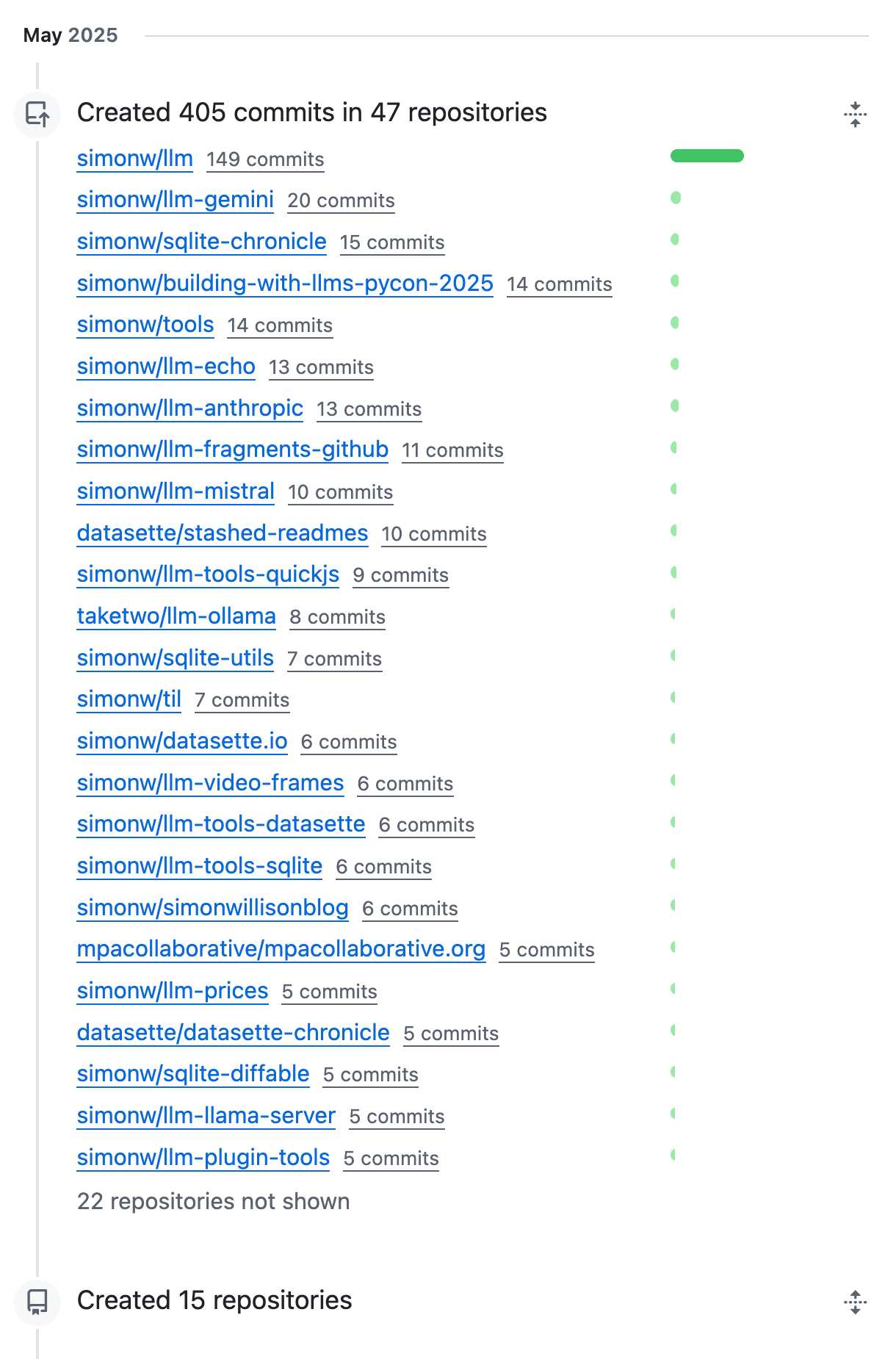
OK, May was a busy month for coding on GitHub. I blame tool support!
I've been having some good results recently asking reasoning LLMs for "implementation plans" for features I'm working on.
I dump either the whole codebase in or the most relevent sections, then dump in my issue thread with several comments describing my planned feature, then ask it to provide an implementation plan for what I've outlined so far.
I'm finding this really valuable, because the model will often spot corners of the codebase that will need to be changed that I haven't thought about yet.
My two preferred models for this at the moment are Gemini 2.5 Flash and o4-mini, because they both have reasoning abilities, long context support (1m tokens for Flash, 200,000 for o4-mini) and they're both really cheap: most of the time the prompt costs me 15 cents or less, depending on the amount of code I feed in.
They rarely get the implementation plan exactly right, but that doesn't matter: what I'm looking for with these prompts is hints that tip me off to parts of the codebase I might not have considered yet.
(I wrote this as a draft in June 2025 but only noticed and hit publish on it in February 2026, I think it's an interesting time capsule of how I was using the models at the time.)
If you've found web development frustrating over the past 5-10 years, here's something that has worked worked great for me: give yourself permission to avoid any form of frontend build system (so no npm / React / TypeScript / JSX / Babel / Vite / Tailwind etc) and code in HTML and JavaScript like it's 2009.
The joy came flooding back to me! It turns out browser APIs are really good now.
You don't even need jQuery to paper over the gaps any more - use document.querySelectorAll() and fetch() directly and see how much value you can build with a few dozen lines of code.
I'll be sending out my first curated monthly highlights newsletter tomorrow, only to $10/month and up sponsors. Sign up now if you want to pay me to send you less!
My weekly-ish newsletter remains free, in fact I just sent out the latest edition.
I wonder if one of the reasons I'm finding LLMs so much more useful for coding than a lot of people that I see in online discussions is that effectively all of the code I work on has automated tests.
I've been trying to stay true to the idea of a Perfect Commit - one that bundles the implementation, tests and documentation in a single unit - for over five years now. As a result almost every piece of (non vibe-coding) code I work on has pretty comprehensive test coverage.
This massively derisks my use of LLMs. If an LLM writes weird, convoluted code that solves my problem I can prove that it works with tests - and then have it refactor the code until it looks good to me, keeping the tests green the whole time.
LLMs help write the tests, too. I finally have a 24/7 pair programmer who can remember how to use unittest.mock!
Next time someone complains that they've found LLMs to be more of a hindrance than a help in their programming work, I'm going to try to remember to ask after the health of their test suite.
Here's a quick demo of the kind of casual things I use LLMs for on a daily basis.
I just found out that Perplexity offer their Deep Research feature via their API, through a model called Sonar Deep Research.
Their documentation includes an example response, which included this usage data in the JSON:
{"prompt_tokens": 19, "completion_tokens": 498, "total_tokens": 517, "citation_tokens": 10175, "num_search_queries": 48, "reasoning_tokens": 95305}
But how much would that actually cost?
Their pricing page lists the price for that model. I snapped this screenshot of the prices:

I could break out a calculator at this point, but I'm not quite curious enough to go through the extra effort.
So I pasted that screenshot into Claude along with the JSON and prompted:
{"prompt_tokens": 19, "completion_tokens": 498, "total_tokens": 517, "citation_tokens": 10175, "num_search_queries": 48, "reasoning_tokens": 95305}Calculate price, use javascript
I wanted to make sure Claude would use its JavaScript analysis tool, since LLMs can't do maths.
I watched Claude Sonnet 4 write 61 lines of JavaScript - keeping an eye on it to check it didn't do anything obviously wrong. The code spat out this output:
=== COST CALCULATIONS ===
Input tokens cost: 19 tokens × $2/million = $0.000038
Output tokens cost: 498 tokens × $8/million = $0.003984
Search queries cost: 48 queries × $5/1000 = $0.240000
Reasoning tokens cost: 95305 tokens × $3/million = $0.285915
=== COST SUMMARY ===
Input tokens: $0.000038
Output tokens: $0.003984
Search queries: $0.240000
Reasoning tokens: $0.285915
─────────────────────────
TOTAL COST: $0.529937
TOTAL COST: $0.5299 (rounded to 4 decimal places)
So that Deep Research API call would cost 53 cents! Curiosity satisfied in less than a minute.
GitHub issues is almost the best notebook in the world.
Free and unlimited, for both public and private notes.
Comprehensive Markdown support, including syntax highlighting for almost any language. Plus you can drag and drop images or videos directly onto a note.
It has fantastic inter-linking abilities. You can paste in URLs to other issues (in any other repository on GitHub) in a markdown list like this:
- https://github.com/simonw/llm/issues/1078
- https://github.com/simonw/llm/issues/1080
Your issue will pull in the title of the other issue, plus that other issue will get back a link to yours - taking issue visibility rules into account.
It has excellent search, both within a repo, across all of your repos or even across the whole of GitHub if you've completely forgotten where you put something.
It has a comprehensive API, both for exporting notes and creating and editing new ones. Add GitHub Actions, triggered by issue events, and you can automate it to do almost anything.
The one missing feature? Synchronized offline support. I still mostly default to Apple Notes on my phone purely because it works with or without the internet and syncs up with my laptop later on.
A few extra notes inspired by the discussion of this post on Hacker News:
- I'm not worried about privacy here. A lot of companies pay GitHub a lot of money to keep the source code and related assets safe. I do not think GitHub are going to sacrifice that trust to "train a model" or whatever.
- There is always the risk of bug that might expose my notes, across any note platform. That's why I keep things like passwords out of my notes!
- Not paying and not self-hosting is a very important feature. I don't want to risk losing my notes to a configuration or billing error!
- The thing where notes can include checklists using
- [ ] itemsyntax is really useful. You can even do- [ ] #refto reference another issue and the checkbox will be automatically checked when that other issue is closed. - I've experimented with a bunch of ways of backing up my notes locally, such as github-to-sqlite. I'm not running any of them on cron on a separate machine at the moment, but I really should!
- I'll go back to pen and paper as soon as my paper notes can be instantly automatically backed up to at least two different continents.
- GitHub issues also scales! microsoft/vscode has 195,376 issues. flutter/flutter has 106,572. I'm not going to run out of space.
- Having my notes in a format that's easy to pipe into an LLM is really fun. Here's a recent example where I summarized a 50+ comment, 1.5 year long issue thread into a new comment using llm-fragments-github.
I was curious how many issues and comments I've created on GitHub. With Claude's help I figured out you can get that using a GraphQL query:
{
viewer {
issueComments {
totalCount
}
issues {
totalCount
}
}
}
Running that with the GitHub GraphQL Explorer tool gave me this:
{
"data": {
"viewer": {
"issueComments": {
"totalCount": 39087
},
"issues": {
"totalCount": 9413
}
}
}
}
That's 48,500 combined issues and comments!
Subscribe to my sponsors-only monthly newsletter
I’ve never liked the idea of charging for my content. I get enormous value from putting all of my writing and research out there for free.
So I’m trying something a little different: pay me to send you less.
I’m starting a sponsors-only monthly newsletter featuring just my heavily curated and edited highlights. If you only have ten minutes, what are the most important things not to miss from the last month?
Don’t want to pay? That’s fine, you can continue to follow my firehose for free!
Anyone who sponsors me for $10/month (or $50/month or more) on GitHub sponsors will receive my new newsletter on approximately the last day of the month. I’ll be sending out the first edition next week.
This blog and my newsletter will continue at their same breakneck pace. Paying subscribers can get a lower volume of stuff.
I'm cautiously optimistic that this could work. I've never liked the idea of business models that incentivize me to publish less. This feels like it encourages me to do what I'm doing already while giving people a rational reason to support my work, at a relatively small incremental cost to myself.
I'm helping make some changes to a large, complex and very unfamiliar to me WordPress site. It's a perfect opportunity to try out Claude Code running against the new Claude 4 models.
It's going extremely well. So far Claude has helped get MySQL working on an older laptop (fixing some inscrutable Homebrew errors), disabled a CAPTCHA plugin that didn't work on localhost, toggled visible warnings on and off several times and figured out which CSS file to modify in the theme that the site is using. It even took a reasonable stab at making the site responsive on mobile!
I'm now calling Claude Code honey badger on account of its voracious appetite for crunching through code (and tokens) looking for the right thing to fix.
I got ChatGPT to make me some fan art:

I was going slightly spare at the fact that every talk at this Anthropic developer conference has used the word "agents" dozens of times, but nobody ever stopped to provide a useful definition.
I'm now in the "Prompting for Agents" workshop and Anthropic's Hannah Moran finally broke the trend by saying that at Anthropic:
Agents are models using tools in a loop
I can live with that! I'm glad someone finally said it out loud.
If your library doesn't have any documentation, it can't have any bugs.
Documentation specifies what your code is supposed to do. Your tests specify what it actually does.
Bugs exist when your test-enforced implementation fails to match the behavior described in your documentation. Without documentation a bug is just undefined behavior.
If you aim to follow semantic versioning you bump your major version when you release a backwards incompatible change. Such changes cannot exist if your code is not comprehensively documented!
Inspired by a half-remembered conversation I had with Tom Insam many years ago.
Tucked into today's Google I/O keynote, a blink-and-you'll miss it moment:
The pelican in the keynote was created by Alexander Chen. Here's the code they wrote with the help of Gemini, which uses p5.js to power the animation.