10 posts tagged “yaml”
2025
model.yaml. From their GitHub repo it looks like this effort quietly launched a couple of months ago, driven by the LM Studio team. Their goal is to specify an "open standard for defining crossplatform, composable AI models".
A model can be defined using a YAML file that looks like this:
model: mistralai/mistral-small-3.2 base: - key: lmstudio-community/mistral-small-3.2-24b-instruct-2506-gguf sources: - type: huggingface user: lmstudio-community repo: Mistral-Small-3.2-24B-Instruct-2506-GGUF metadataOverrides: domain: llm architectures: - mistral compatibilityTypes: - gguf paramsStrings: - 24B minMemoryUsageBytes: 14300000000 contextLengths: - 4096 vision: true
This should be enough information for an LLM serving engine - such as LM Studio - to understand where to get the model weights (here that's lmstudio-community/Mistral-Small-3.2-24B-Instruct-2506-GGUF on Hugging Face, but it leaves space for alternative providers) plus various other configuration options and important metadata about the capabilities of the model.
I like this concept a lot. I've actually been considering something similar for my LLM tool - my idea was to use Markdown with a YAML frontmatter block - but now that there's an early-stage standard for it I may well build on top of this work instead.
I couldn't find any evidence that anyone outside of LM Studio is using this yet, so it's effectively a one-vendor standard for the moment. All of the models in their Model Catalog are defined using model.yaml.
2024
openai/openai-openapi. Seeing as the LLM world has semi-standardized on imitating OpenAI's API format for a whole host of different tools, it's useful to note that OpenAI themselves maintain a dedicated repository for a OpenAPI YAML representation of their current API.
(I get OpenAI and OpenAPI typo-confused all the time, so openai-openapi is a delightfully fiddly repository name.)
The openapi.yaml file itself is over 26,000 lines long, defining 76 API endpoints ("paths" in OpenAPI terminology) and 284 "schemas" for JSON that can be sent to and from those endpoints. A much more interesting view onto it is the commit history for that file, showing details of when each different API feature was released.
Browsing 26,000 lines of YAML isn't pleasant, so I got Claude to build me a rudimentary YAML expand/hide exploration tool. Here's that tool running against the OpenAI schema, loaded directly from GitHub via a CORS-enabled fetch() call: https://tools.simonwillison.net/yaml-explorer#.eyJ1c... - the code after that fragment is a base64-encoded JSON for the current state of the tool (mostly Claude's idea).
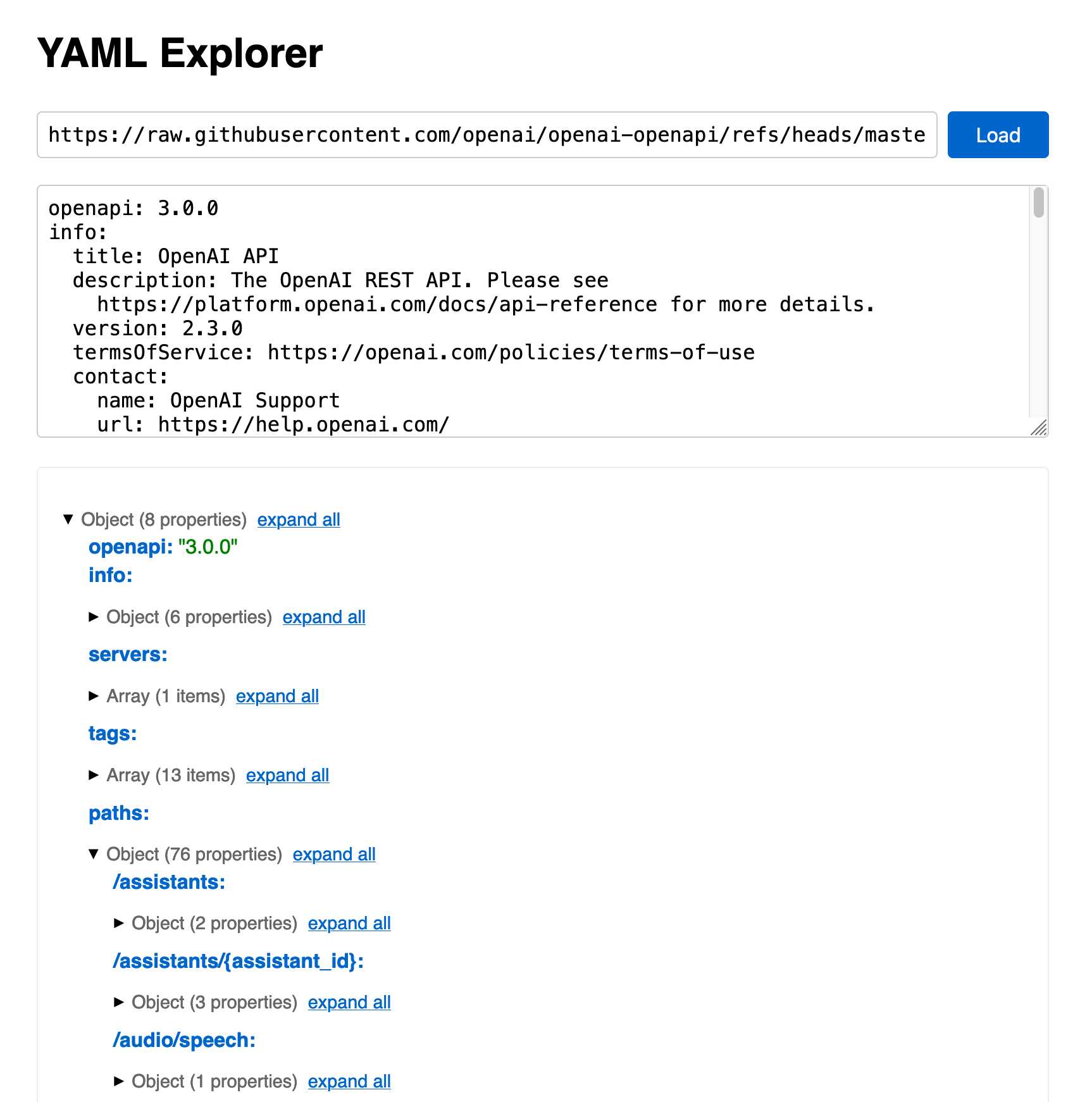
The tool is a little buggy - the expand-all option doesn't work quite how I want - but it's useful enough for the moment.
Update: It turns out the petstore.swagger.io demo has an (as far as I can tell) undocumented ?url= parameter which can load external YAML files, so here's openai-openapi/openapi.yaml in an OpenAPI explorer interface.
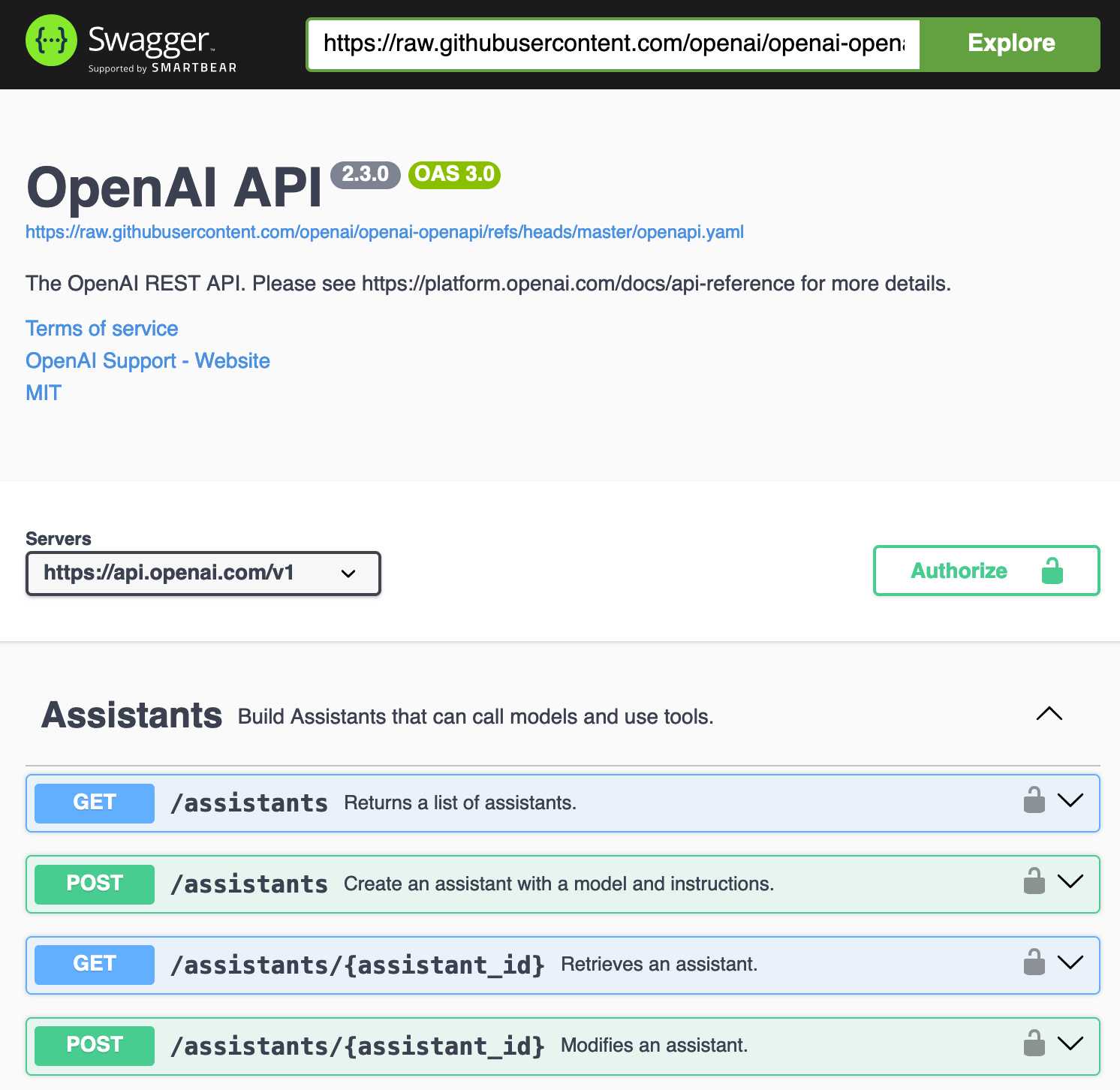
2020
Weeknotes: airtable-export, generating screenshots in GitHub Actions, Dogsheep!
This week I figured out how to populate Datasette from Airtable, wrote code to generate social media preview card page screenshots using Puppeteer, and made a big breakthrough with my Dogsheep project.
[... 1,461 words]airtable-export. I wrote a command-line utility for exporting data from Airtable and dumping it to disk as YAML, JSON or newline delimited JSON files. This means you can backup an Airtable database from a GitHub Action and get a commit history of changes made to your data.
Goodbye Zeit Now v1, hello datasette-publish-now—and talking to myself in GitHub issues
This week I’ve been mostly dealing with the finally announced shutdown of Zeit Now v1. And having long-winded conversations with myself in GitHub issues.
[... 2,050 words]2019
niche-museums.com, powered by Datasette
I just released a major upgrade to my www.niche-museums.com website (launched last month).
[... 1,154 words]2018
Analyzing US Election Russian Facebook Ads
Two interesting data sources have emerged in the past few weeks concerning the Russian impact on the 2016 US elections.
[... 922 words]2010
twitter-text-conformance (via) This is a neat idea: Twitter have released open source libraries for parsing standard tweet syntax in Ruby and Java, but they’ve also released a set of YAML unit tests aimed at anyone who wants to implement the same parsing logic in other languages.
2003
More YAML
Paul Tchistopolskii’s XML Alternatives reminded me to take another look at YAML. The specification has been updated since I last looked and seems to be a bit more complicated, but it’s still a very nicely designed format. Implementations are available for Perl, Python and Ruby with C and Java on the way but strangely no one seems to be doing one for PHP yet. I’m doing a course at Uni on compilers at the moment which includes quite a lot of stuff about writing parsers so I’m very tempted to have a go at a YAML implementation in the next few weeks just to try stuff out. The possibility of easily swapping relatively complex data structures between PHP and Python is pretty tempting as well.
2002
YAML
I forget quite how I got there, but the other day I found myself reading about YAML—YAML Ain’t Markup Language. It looks really interesting. YAML aims to be an easily human readable format for storing and transferring structured data—so far, so XML. Where it differs from the IT world’s favourite buzzword is that YAML is specifically designed to handle the three most common data structures—scalars (single values), lists and dictionaries. Here’s a sample (taken from the official specification):
[... 288 words]