Analyzing US Election Russian Facebook Ads
6th August 2018
Two interesting data sources have emerged in the past few weeks concerning the Russian impact on the 2016 US elections.
FiveThirtyEight published nearly 3 million tweets from accounts associated with the Russian “Internet Research Agency”—see my article and searchable tweet archive here.
Separately, the House Intelligence Committee Minority released 3,517 Facebook ads that were reported to have been bought by the Russian Internet Research Agency as a set of redacted PDF files.
Exploring the Russian Facebook Ad spend
The initial data was released as zip files full of PDFs, one of the least friendly formats you can use to publish data.
Ed Summers took on the intimidating task of cleaning that up. His results are incredible: he used the pytesseract OCR library and PyPDF2 to extract both the images and the associated metadata and convert the whole lot into a single 3.9MB JSON file.
I wrote some code to convert his JSON file to SQLite (more on the details later) and the result can be found here:
https://russian-ira-facebook-ads.datasettes.com/
Here’s an example search for “cops” ordered by the USD equivalent spent on the ad (some of the spends are in rubles, so I convert those to USD using today’s exchange rate of 0.016).
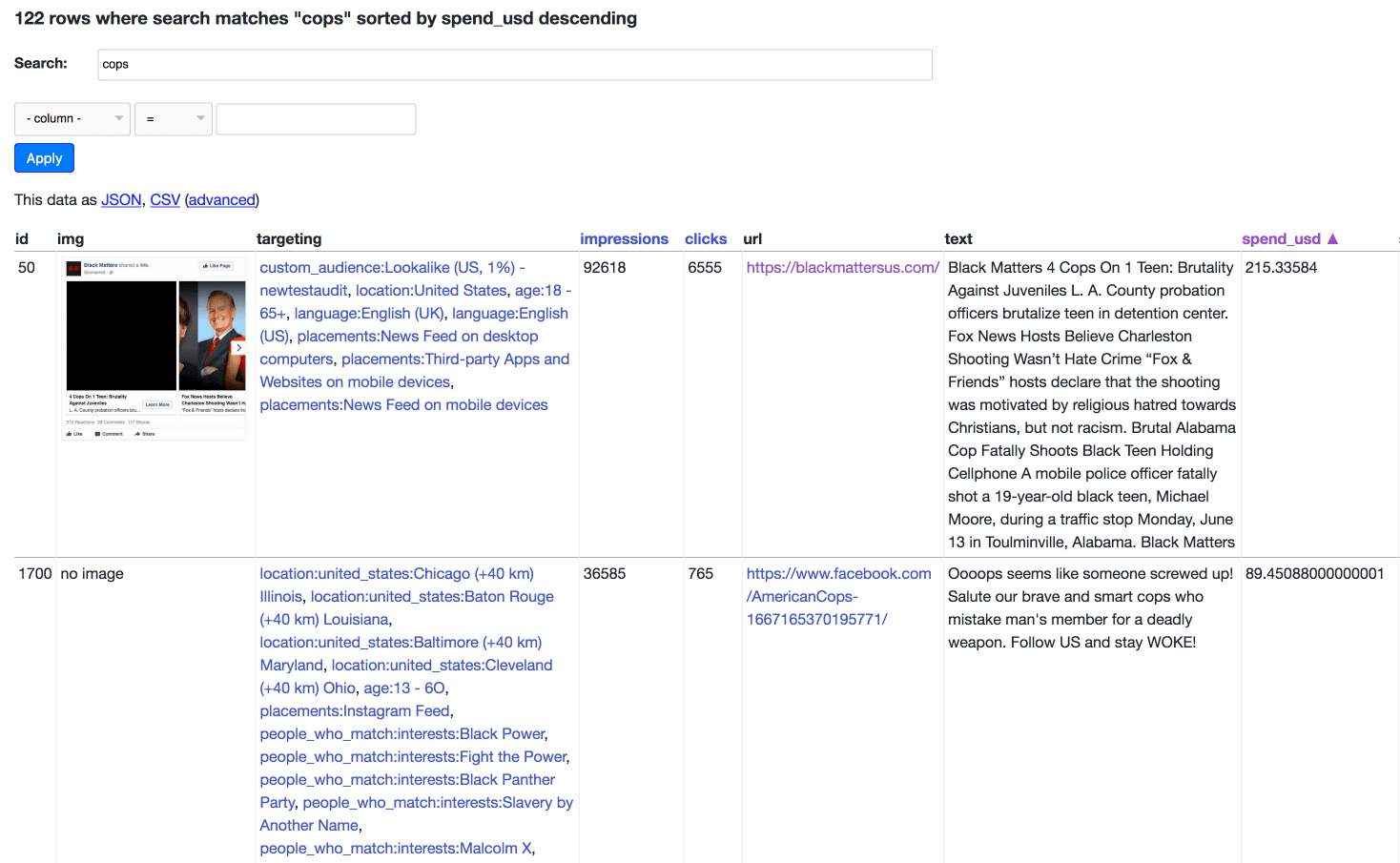
One of the most interesting things about this data is that it includes the Facebook ad targetting options that were used to promote the ads. I’ve built a separate interface for browsing those—you can see the most frequently applied targets:
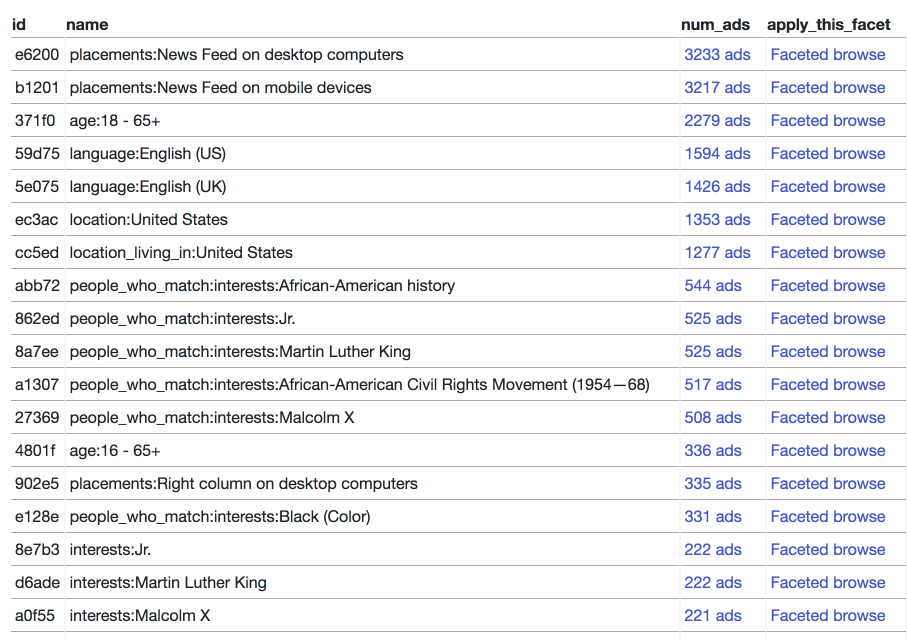
And by browsing through the different facets you can construct e.g. a search for all ads that targeted people interested in both interests:Martin Luther King and interests:Police Brutality is a Crime: https://russian-ira-facebook-ads.datasettes.com/russian-ads-919cbfd/display_ads?_targets_json=[“d6ade”%2C“40c27”]
New tooling under the hood
I ended up spinning up several new projects to help process and explore this data.
sqlite-utils
The first is a new library called sqlite-utils. If data is already in CSV I tend to convert it using csvs-to-sqlite, but if data is in a less tabular format (JSON or XML for example) I have to hand-write code. Here’s a script I wrote to process the XML version of the UK Register of Members Interests for example.
My goal with sqlite-utils is to take some of the common patterns from those scripts and make them as easy to use as possible, in particular when running inside a Jupyter notebook. It’s still very early, but the script I wrote to process the Russian ads JSON is a good example of the kind of thing I want to do with it.
datasette-json-html
The second new tool is a new Datasette plugin (and corresponding plugin hook) called datasette-json-html. I used this to solve the need to display both rendered images and customized links as part of the regular Datasette instance.
It’s a pretty crazy solution (hence why it’s implemented as a plugin and not part of Datasette core) but it works surprisingly well. The basic idea is to support a mini JSON language which can be detected and rendered as HTML. A couple of examples:
{
"img_src": "https://raw.githubusercontent.com/edsu/irads/03fb4b/site/images/0771.png",
"width": 200
}
Is rendered as an HTML <img src=""> element.
[
{
"label": "location:United States",
"href": "/russian-ads/display_ads?_target=ec3ac"
},
{
"label": "interests:Martin Luther King",
"href": "/russian-ads/display_ads?_target=d6ade"
},
{
"label": "interests:Jr.",
"href": "/russian-ads/display_ads?_target=8e7b3"
}
]
Is rendered as a comma-separated list of HTML links.
Why use JSON for this? Because SQLite has some incredibly powerful JSON features, making it trivial to output JSON as part of the result of a SQL query. Most interestingly of all it has json_group_array() which can work as an aggregation function to combine a set of related rows into a single JSON array.
The display_ads page shown above is powered by a SQL view. Here’s the relevant subset of that view:
select ads.id,
case when image is not null then
json_object("img_src", "https://raw.githubusercontent.com/edsu/irads/03fb4b/site/" || image, "width", 200)
else
"no image"
end as img,
json_group_array(
json_object(
"label", targets.name,
"href", "/russian-ads/display_ads?_target="
|| urllib_quote_plus(targets.id)
)
) as targeting
from ads
join ad_targets on ads.id = ad_targets.ad_id
join targets on ad_targets.target_id = targets.id
group by ads.id limit 10
I’m using SQLite’s JSON functions to dynamically assemble the JSON format that datasette-json-html knows how to render. I’m delighted at how well it works.
I’ve turned off arbitrary SQL querying against the main Facebook ads Datasette instance, but there’s a copy running at https://russian-ira-facebook-ads-sql-allowed.now.sh/russian-ads if you want to play with these queries.
Weird implementation details
The full source code for my implementation is available on GitHub.
I ended up using an experimental plugin hook to enable additional custom filtering on Datasette views in order to support showing ads against multiple m2m targets, but hopefully that will be made unnecessary as work on Datasette’s support for m2m relationships progresses.
I also experimented with YAML to generate the metadata.json file as JSON strings aren’t a great way of representing multi-line HTML and SQL. And if you want to see some really convoluted SQL have a look at how the canned query for the faceted targeting interface works.
This was a really fun project, which further stretched my ideas about what Datasette should be capable of out of the box. I’m hoping that the m2m work will make a lot of these crazy hacks redundant.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026