Exploring the UK Register of Members Interests with SQL and Datasette
25th April 2018
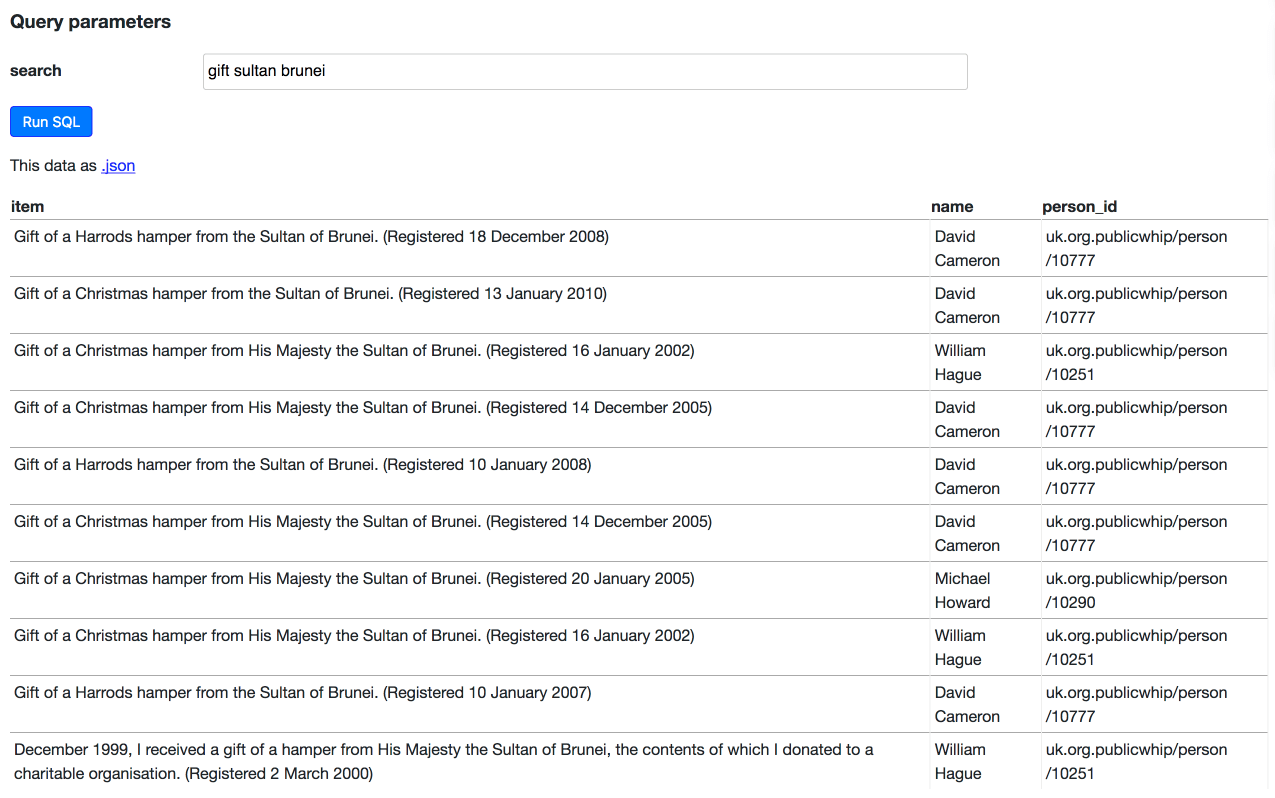
Ever wondered which UK Members of Parliament get gifted the most helicopter rides? How about which MPs have been given Christmas hampers by the Sultan of Brunei? (David Cameron, William Hague and Michael Howard apparently). Here’s how to dig through the Register of Members Interests using SQL and Datasette.
mySociety have been building incredible civic participation applications like TheyWorkForYou and FixMyStreet for nearly 15 years now, and have accumulated all kinds of interesting data along the way.
They recently launched their own data portal at data.mysociety.org listing all of the information they have available. While exploring it I stumbled across their copy of the UK Register of Members Interests. Every UK Member of Parliament has to register their conflicts of interest and income sources, and mySociety have an ongoing project to parse that data into a more useful format.
It won’t surprise you to hear that I couldn’t resist turning their XML files into a SQLite database.
The result is register-of-members-interests.datasettes.com—a Datasette instance running against a SQLite database containing over 1.3 million line-items registered by 1,419 MPs over the course of 18 years.
Some fun queries
A few of my favourites so far:
- Which MPs have taken the most donated helicopter rides
- Which MPs have accepted gifts from the Surtan of Brunei
- A better gifts query with more robust de-duping: here’s gifts of hampers, watches and Glastonbury festival tickets
- Which MPs own significant shares in Shell, Apple, or BP.
- Who has reported the most overseas trips to Saudi Arabia? The top hit there was Daniel Kawczynski, and it turns out his Wikipedia page has a section dedicated to his relationship with the kindgom.
- How much do MPs get paid for appearances on Have I Got News For You. The going rate seems to be £1,500 but you can find some interesting discrepancies if you exclude that value from the results.
- Which MPs are responsible for the most total line items reported
Understanding the data model
Most of the action takes place in the items table, where each item is a line-item from an MP’s filing. You can search that table by keyword (see helicopter example above) or apply filters to it using the standard Datasette interface. You can also execute your own SQL directly against the database.
Each item is filed against a category. There appears to have been quite a bit of churn in the way that the categories are defined over the years, plus the data is pretty untidy—there are no less than 10 ways of spelling “Remunerated employment, office, profession etc.” for example!

There are also a LOT of duplicate items in the set—it appears that MPs frequently list the same item (a rental property for example) every time they fill out the register. SQL DISTINCT clauses can help filter through these, as seen in some of the above examples.
The data also has the concepts of both members and people. As far as I can tell people are distinct, but members may contain duplicates—presumably to represent MPs who have served more than one term in office. It looks like the member field stopped being populated in March 2015 so analysis is best performed against the people table.
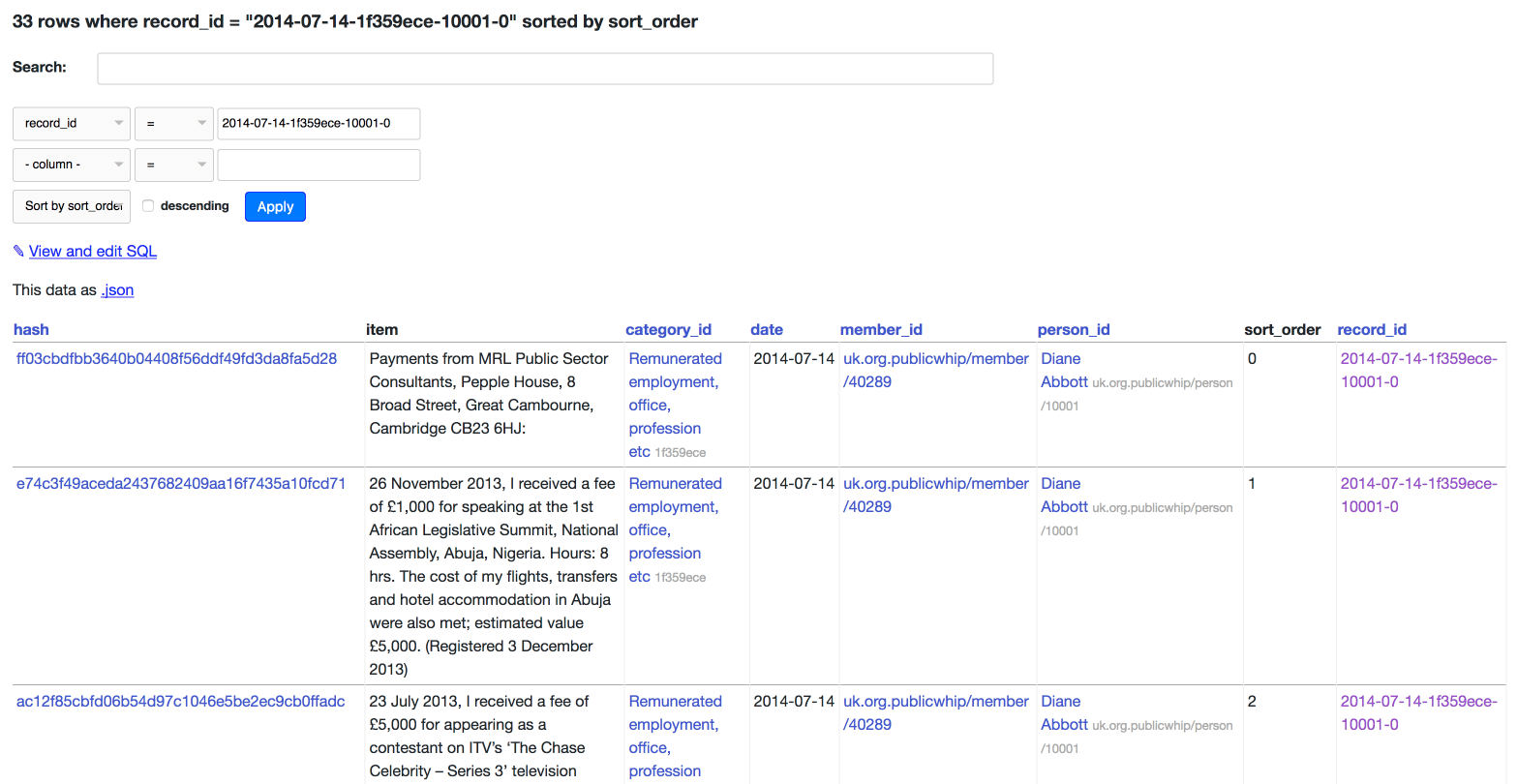
Once concept I have introduced myself is the record_id. In the XML documents the items are often grouped together into a related collection, like this:
<regmem personid="uk.org.publicwhip/person/10001"
memberid="uk.org.publicwhip/member/40289" membername="Diane Abbott" date="2014-07-14">
<category type="2" name="Remunerated employment, office, profession etc">
<item>Payments from MRL Public Sector Consultants, Pepple House, 8 Broad Street, Great Cambourne, Cambridge CB23 6HJ:</item>
<item>26 November 2013, I received a fee of £1,000 for speaking at the 1st African Legislative Summit, National Assembly, Abuja, Nigeria. Hours: 8 hrs. The cost of my flights, transfers and hotel accommodation in Abuja were also met; estimated value £5,000. <em>(Registered 3 December 2013)</em></item>
<item>23 July 2013, I received a fee of £5,000 for appearing as a contestant on ITV’s ‘The Chase Celebrity – Series 3’ television programme. Address of payer: ITV Studios Ltd, London Television Centre, Upper Ground, London SE1 9Lt. Hours: 12 hrs. <em>(Registered 23 July 2013)</em></item>
</category>
</regmem>
While these items are presented as separate line items, their grouping carries meaning: the first line item here acts as a kind of heading to help provide context to the other items.
To model this in the simplest way possible, I’ve attempted to preserve the order of these groups using a pair of additional columns: the record_id and the sort_order. I construct the record_id using a collection of other fields—the idea is for it to be sortable, and for each line-item in the same grouping to have the same record_id:
record_id = "{date}-{category_id}-{person_id}-{record}".format(
date=date,
category_id=category_id,
person_id=person_id.split("/")[
-1
],
record=record,
)
The resulting record_id might look like this: 2018-04-16-70b64e89-24878-0
To recreate that particular sequence of line-items, you can search for all items matching that record_id and then sort them by their sort_order. Here’s that record from Diane Abbott shown with its surrounding context.
How I built it
The short version: I downloaded all of the XML files and wrote a Python script which parsed them using ElementTree and inserted them into a SQLite database. I’ve put the code on GitHub.
A couple of fun tricks: firstly, I borrowed some code from csvs-to-sqlite to create the full-text search index and enable searching:
def create_and_populate_fts(conn):
create_sql = """
CREATE VIRTUAL TABLE "items_fts"
USING {fts_version} (item, person_name, content="items")
""".format(
fts_version=best_fts_version()
)
conn.executescript(create_sql)
conn.executescript(
"""
INSERT INTO "items_fts" (rowid, item, person_name)
SELECT items.rowid, items.item, people.name
FROM items LEFT JOIN people ON items.person_id = people.id
"""
)
The best_fts_version() function implements basic feature detection against SQLite by trying operations in an in-memory database.
Secondly, I ended up writing my own tiny utility function for inserting records into SQLite. SQLite has useful INSERT OR REPLACE INTO syntax which allows you to insert a record and will automatically update an existing record if there is a match on the primary key. This meant I could write this utility function and use it for all of my data inserts:
def insert_or_replace(conn, table, record):
pairs = record.items()
columns = [p[0] for p in pairs]
params = [p[1] for p in pairs]
sql = "INSERT OR REPLACE INTO {table} ({column_list}) VALUES ({value_list});".format(
table=table,
column_list=", ".join(columns),
value_list=", ".join(["?" for p in params]),
)
conn.execute(sql, params)
# ...
insert_or_replace(
db,
"people",
{
"id": person_id,
"name": regmem_el.attrib["membername"],
},
)
What can you find?
I’ve really only scratched the surface of what’s in here with my initial queries. What can you find? Send me Datasette query links on Twitter with your discoveries!
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026