Datasette plugins, and building a clustered map visualization
20th April 2018
Datasette now supports plugins!
Last Saturday I asked Twitter for examples of Python projects with successful plugin ecosystems. pytest was the clear winner: the pytest plugin compatibility table (an ingenious innovation that I would love to eventually copy for Datasette) lists 457 plugins, and even the core pytest system itself is built as a collection of default plugins that can be replaced or over-ridden.
Best of all: pytest’s plugin mechanism is available as a separate package: pluggy. And pluggy was exactly what I needed for Datasette.
You can follow the ongoing development of the feature in issue #14. This morning I released Datasette 0.20 with support for a number of different plugin hooks: plugins can add custom template tags and SQL functions, and can also bundle their own static assets, JavaScript, CSS and templates. The hooks are described in some detail in the Datasette Plugins documentation.
datasette-cluster-map
I also released my first plugin: datasette-cluster-map. Once installed, it looks out for database tables that have a latitude and longitude column. When it finds them, it draws all of the points on an interactive map using Leaflet and Leaflet.markercluster.
Let’s try it out on some polar bears!
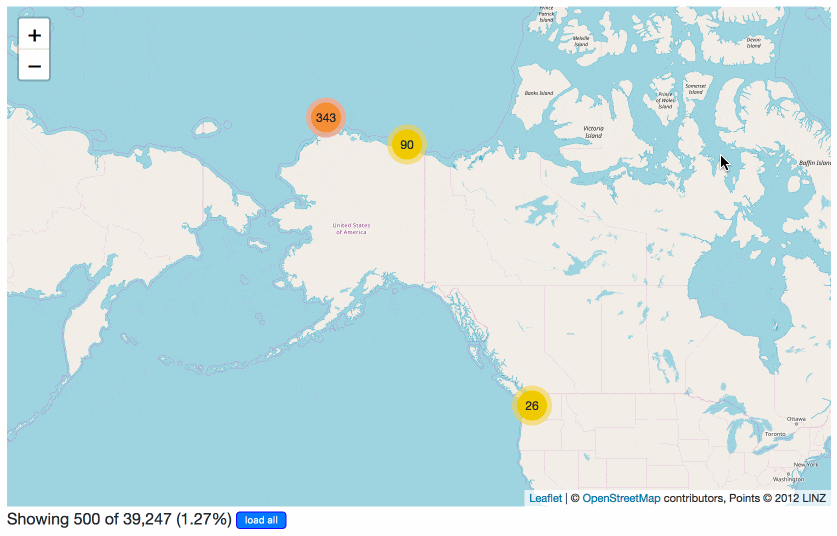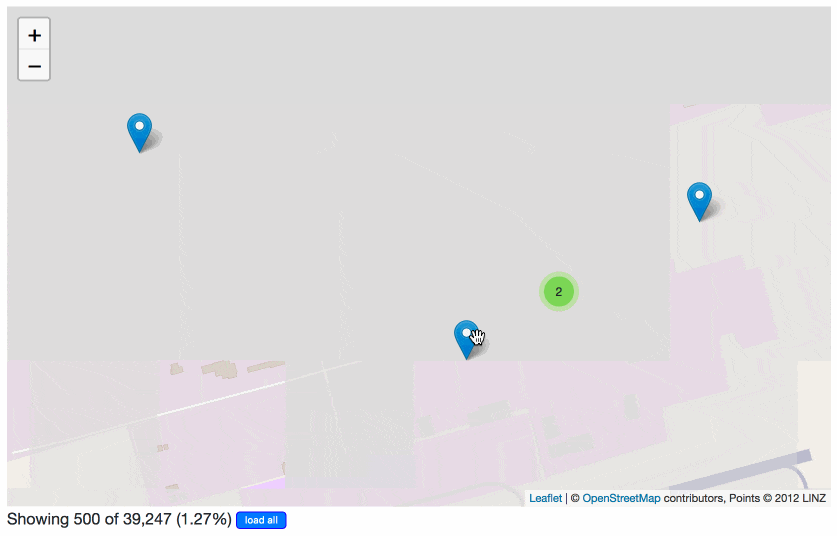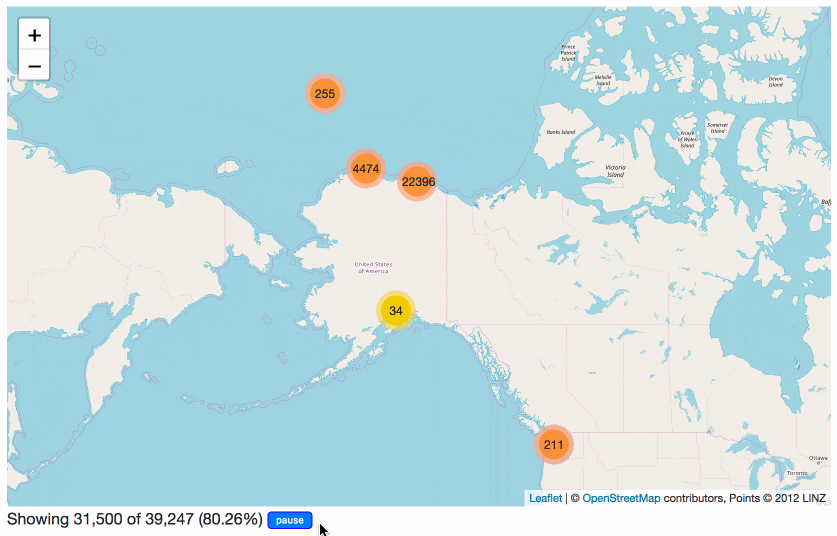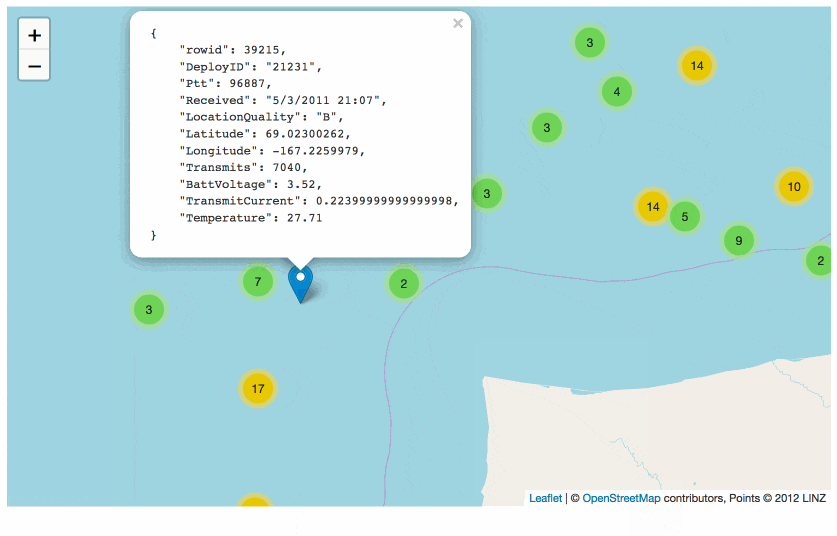
The USGS Alaska Science Center have released a delightful set of data entitled Sensor and Location data from Ear Tag PTTs Deployed on Polar Bears in the Southern Beaufort Sea 2009 to 2011. It’s a collection of CSV files, which means it’s trivial to convert it to SQLite using my csvs-to-sqlite tool.
Having created the SQLite database, we can deploy it to a hosting account on Zeit Now alongside the new plugin like this:
# Make sure we have the latest datasette
pip3 install datasette --upgrade
# Deploy polar-bears.db to now with an increased default page_size
datasette publish now \
--install=datasette-cluster-map \
--extra-options "--page_size=500" \
polar-bears.db
The --install option is new in Datasette 0.20 (it works for datasette publish heroku as well)—it tells the publishing provider to pip install the specified package. You can use it more than once to install multiple plugins, and it accepts a path to a zip file in addition to the name of a PyPI package.
Explore the full demo at https://datasette-cluster-map-demo.now.sh/polar-bears
Visualize any query on a map
Since the plugin inserts itself at the top of any Datasette table view with latitude and longitude columns, there are all sorts of neat tricks you can do with it.
I also loaded the San Francisco tree list (thanks, Department of Public Works) into the demo. Impressively, you can click “load all” on this page and Leaflet.markercluster will load in all 189,144 points and display them on the same map… and it works fine on my laptop and my phone. Computers in 2018 are pretty good!
But since it’s a Datasette table, we can filter it. Here’s a map of every New Zealand Xmas Tree in San Francisco (8,683 points). Here’s every tree where the Caretaker is Friends of the Urban Forest. Here’s every palm tree planted in 1990:
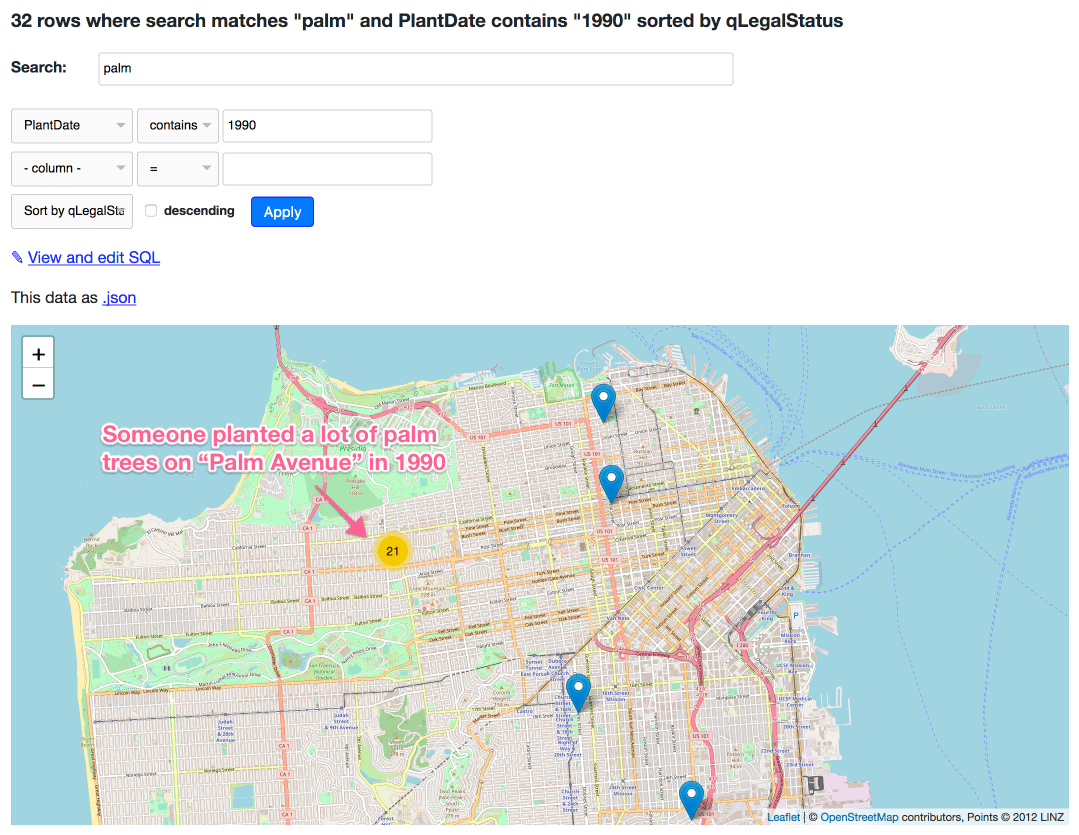
Update: This is an incorrect example: there are 21 matches on “palm avenue” because the FTS search index covers the address field—they’re not actually palm trees. Here’s a corrected query for palm trees planted in 1990.
The plugin currently only works against columns called latitude and longitude… but if your columns are called something else, don’t worry: you can craft a custom SQL query that aliases your columns and everything will work as intended. Here’s an example against some more polar bear data:
select *, "Capture Latitude" as latitude, "Capture Longitude" as longitude
from [USGS_WC_eartag_deployments_2009-2011]
Writing your own plugins
I’m really excited to see what people invent. If you want to have a go, your first stop should be the Plugins documentation. If you want an example of a simple plugin (including the all-important mechanism for packaging it up using setup.py) take a look at datasette-cluster-map on GitHub.
And if you have any thoughts, ideas or suggestions on how the plugin mechanism can be further employed please join the conversation on issue #14. I’ve literally just got started with Datasette’s plugin hooks, and I’m very keen to hear about things people want to build that aren’t yet supported.
More recent articles
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026