Analyzing US Election troll tweets with Datasette
6th August 2018
FiveThirtyEight published nearly 3 million tweets from accounts associated with the Russian “Internet Research Agency”, based on research by Darren Linvill and Patrick Warren at at Clemson University.
FiveThirtyEight’s tweets were shared as CSV, so I’ve used my csvs-to-sqlite tool to convert them and used Datasette to publish them in a searchable, browsable interface: https://russian-troll-tweets.datasettes.com/
The data is most interesting if you apply faceting. Here’s the full set of tweets faceted by author, language, region, post type and account category:
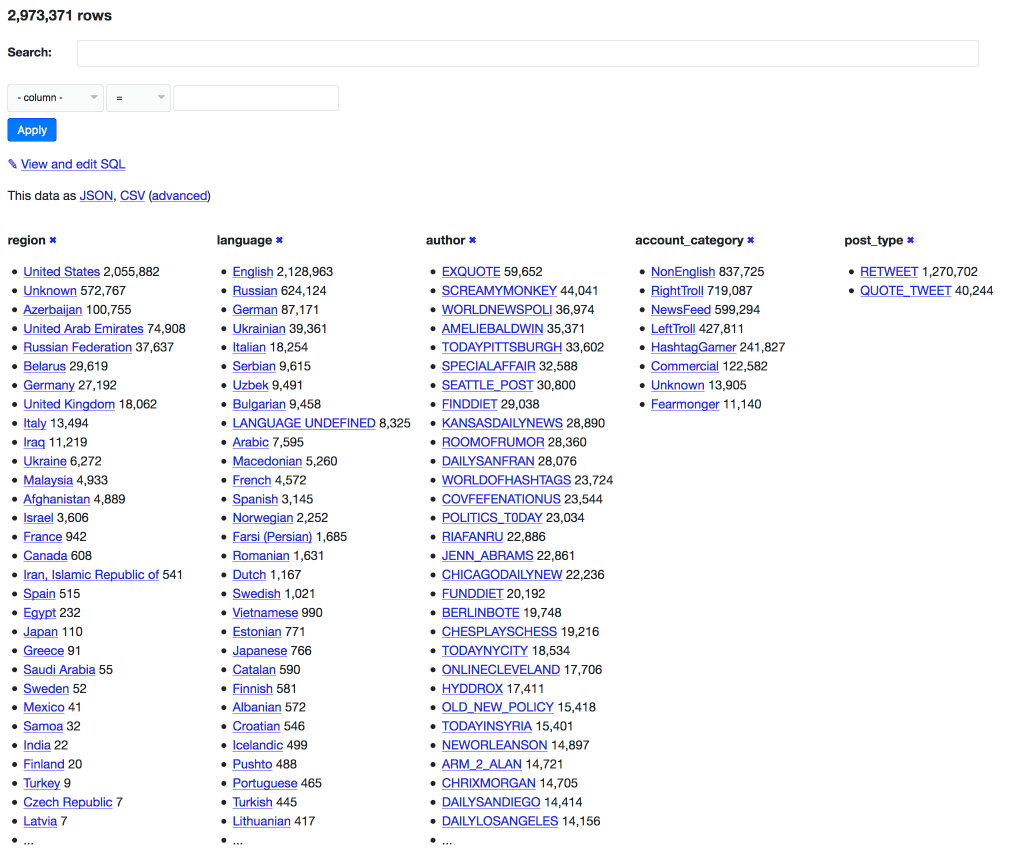
The minimal source code for this Datasette instance is on GitHub.
More recent articles
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026
- sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25) - 5th July 2026