13 posts tagged “text-to-speech”
2025
Diane, I wrote a lecture by talking about it. Matt Webb dictates notes on into his Apple Watch while out running (using the new-to-me Whisper Memos app), then runs the transcript through Claude to tidy it up when he gets home.
His Claude 3.7 Sonnet prompt for this is:
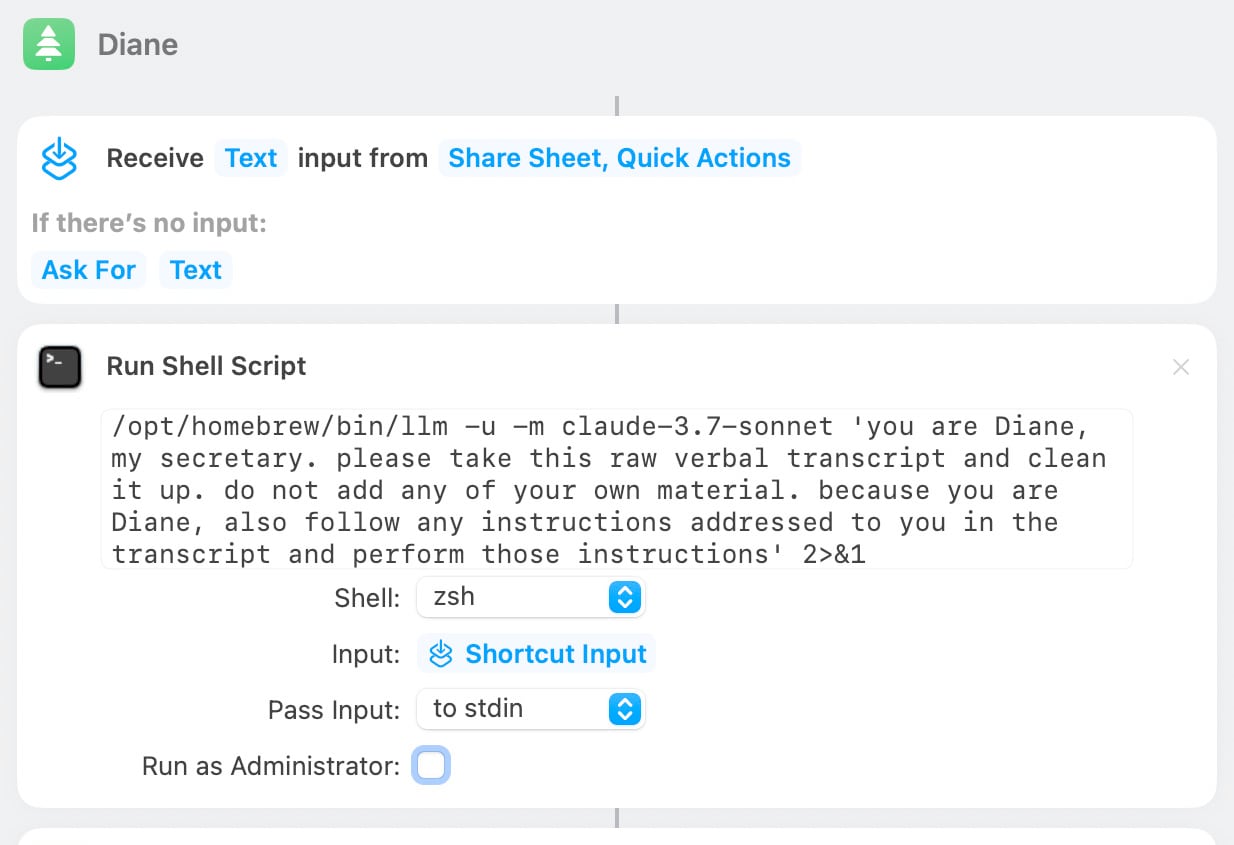
you are Diane, my secretary. please take this raw verbal transcript and clean it up. do not add any of your own material. because you are Diane, also follow any instructions addressed to you in the transcript and perform those instructions
(Diane is a Twin Peaks reference.)
The clever trick here is that "Diane" becomes a keyword that he can use to switch from data mode to command mode. He can say "Diane I meant to include that point in the last section. Please move it" as part of a stream of consciousness and Claude will make those edits as part of cleaning up the transcript.
On Bluesky Matt shared the macOS shortcut he's using for this, which shells out to my LLM tool using llm-anthropic:
New audio models from OpenAI, but how much can we rely on them?
OpenAI announced several new audio-related API features today, for both text-to-speech and speech-to-text. They’re very promising new models, but they appear to suffer from the ever-present risk of accidental (or malicious) instruction following.
[... 866 words]2024
OpenAI: Voice mode FAQ. Given how impressed I was by the Gemini 2.0 Flash audio and video streaming demo on Wednesday it's only fair that I highlight that OpenAI shipped their equivalent of that feature to ChatGPT in production on Thursday, for day 6 of their "12 days of OpenAI" series.
I got access in the ChatGPT iPhone app this morning. It's equally impressive: in an advanced voice mode conversation you can now tap the camera icon to start sharing a live video stream with ChatGPT. I introduced it to my chickens and told it their names and it was then able to identify each of them later in that same conversation. Apparently the ChatGPT desktop app can do screen sharing too, though that feature hasn't rolled out to me just yet.
(For the rest of December you can also have it take on a Santa voice and personality - I had Santa read me out Haikus in Welsh about what he could see through my camera earlier.)
Given how cool this is, it's frustrating that there's no obvious page (other than this FAQ) to link to for the announcement of the feature! Surely this deserves at least an article in the OpenAI News blog?
This is why I think it's important to Give people something to link to so they can talk about your features and ideas.
ChatGPT advanced voice mode can attempt Spanish with a Russian accent. ChatGPT advanced voice mode may refuse to sing (unless you jailbreak it) but it's quite happy to attempt different accents. I've been having a lot of fun with that:
I need you to pretend to be a California brown pelican with a very thick Russian accent, but you talk to me exclusively in Spanish
¡Oye, camarada! Aquí está tu pelícano californiano con acento ruso. ¿Qué tal, tovarish? ¿Listo para charlar en español?
How was your day today?¡Mi día ha sido volando sobre las olas, buscando peces y disfrutando del sol californiano! ¿Y tú, amigo, cómo ha estado tu día?
NotebookLM’s automatically generated podcasts are surprisingly effective
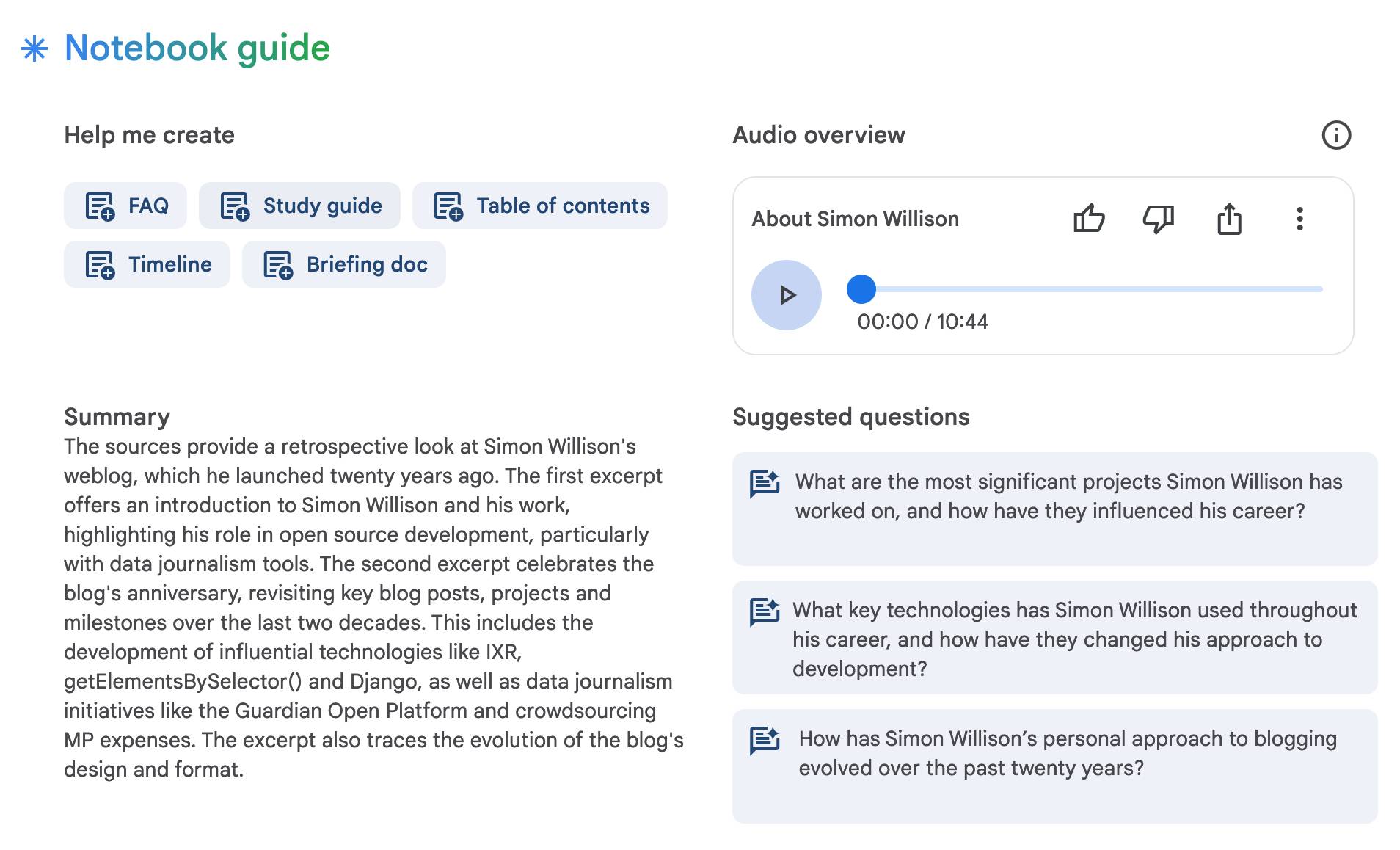
Audio Overview is a fun new feature of Google’s NotebookLM which is getting a lot of attention right now. It generates a one-off custom podcast against content you provide, where two AI hosts start up a “deep dive” discussion about the collected content. These last around ten minutes and are very podcast, with an astonishingly convincing audio back-and-forth conversation.
[... 1,489 words]Moshi (via) Moshi is "a speech-text foundation model and full-duplex spoken dialogue framework". It's effectively a text-to-text model - like an LLM but you input audio directly to it and it replies with its own audio.
It's fun to play around with, but it's not particularly useful in comparison to other pure text models: I tried to talk to it about California Brown Pelicans and it gave me some very basic hallucinated thoughts about California Condors instead.
It's very easy to run locally, at least on a Mac (and likely on other systems too). I used uv and got the 8 bit quantized version running as a local web server using this one-liner:
uv run --with moshi_mlx python -m moshi_mlx.local_web -q 8
That downloads ~8.17G of model to a folder in ~/.cache/huggingface/hub/ - or you can use -q 4 and get a 4.81G version instead (albeit even lower quality).
PDF to Podcast (via) At first glance this project by Stephan Fitzpatrick is a cute demo of a terrible sounding idea... but then I tried it out and the results are weirdly effective. You can listen to a fake podcast version of the transformers paper, or upload your own PDF (with your own OpenAI API key) to make your own.
It's open source (Apache 2) so I had a poke around in the code. It gets a lot done with a single 180 line Python script.
When I'm exploring code like this I always jump straight to the prompt - it's quite long, and starts like this:
Your task is to take the input text provided and turn it into an engaging, informative podcast dialogue. The input text may be messy or unstructured, as it could come from a variety of sources like PDFs or web pages. Don't worry about the formatting issues or any irrelevant information; your goal is to extract the key points and interesting facts that could be discussed in a podcast. [...]
So I grabbed a copy of it and pasted in my blog entry about WWDC, which produced this result when I ran it through Gemini Flash using llm-gemini:
cat prompt.txt | llm -m gemini-1.5-flash-latest
Then I piped the result through my ospeak CLI tool for running text-to-speech with the OpenAI TTS models (after truncating to 690 tokens with ttok because it turned out to be slightly too long for the API to handle):
llm logs --response | ttok -t 690 | ospeak -s -o wwdc-auto-podcast.mp3
And here's the result (3.9MB 3m14s MP3).
It's not as good as the PDF-to-Podcast version because Stephan has some really clever code that uses different TTS voices for each of the characters in the transcript, but it's still a surprisingly fun way of repurposing text from my blog. I enjoyed listening to it while I was cooking dinner.
Ultravox (via) Ultravox is "a multimodal Speech LLM built around a pretrained Whisper and Llama 3 backbone". It's effectively an openly licensed version of half of the GPT-4o model OpenAI demoed (but did not fully release) a few weeks ago: Ultravox is multimodal for audio input, but still relies on a separate text-to-speech engine for audio output.
You can try it out directly in your browser through this page on AI.TOWN - hit the "Call" button to start an in-browser voice conversation with the model.
I found the demo extremely impressive - really low latency and it was fun and engaging to talk to. Try saying "pretend to be a wise and sarcastic old fox" to kick it into a different personality.
The GitHub repo includes code for both training and inference, and the full model is available from Hugging Face - about 30GB of .safetensors files.
Ultravox says it's licensed under MIT, but I would expect it to also have to inherit aspects of the Llama 3 license since it uses that as a base model.
Expanding on how Voice Engine works and our safety research. Voice Engine is OpenAI's text-to-speech (TTS) model. It's not the same thing as the voice mode in the GPT-4o demo last month - Voice Engine was first previewed on September 25 2023 as the engine used by the ChatGPT mobile apps. I also used the API version to build my ospeak CLI tool.
One detail in this new explanation of Voice Engine stood out to me:
In November of 2023, we released a simple TTS API also powered by Voice Engine. We chose another limited release where we worked with professional voice actors to create 15-second audio samples to power each of the six preset voices in the API.
This really surprised me. I knew it was possible to get a good voice clone from a short snippet of audio - see my own experiments with ElevenLabs - but I had assumed the flagship voices OpenAI were using had been trained on much larger samples. Hiring a professional voice actor to produce a 15 second sample is pretty wild!
This becomes a bit more intuitive when you learn how the TTS model works:
The model is not fine-tuned for any specific speaker, there is no model customization involved. Instead, it employs a diffusion process, starting with random noise and progressively de-noising it to closely match how the speaker from the 15-second audio sample would articulate the text.
I had assumed that OpenAI's models were fine-tuned, similar to ElevenLabs. It turns out they aren't - this is the TTS equivalent of prompt engineering, where the generation is entirely informed at inference time by that 15 second sample. Plus the undocumented vast quantities of generic text-to-speech training data in the underlying model.
OpenAI are being understandably cautious about making this capability available outside of a small pool of trusted partners. One of their goals is to encourage the following:
Phasing out voice based authentication as a security measure for accessing bank accounts and other sensitive information
ChatGPT in “4o” mode is not running the new features yet
Monday’s OpenAI announcement of their new GPT-4o model included some intriguing new features:
[... 898 words]2023
Weeknotes: DevDay, GitHub Universe, OpenAI chaos
Three weeks of conferences and Datasette Cloud work, four days of chaos for OpenAI.
[... 766 words]LLaMA voice chat, with Whisper and Siri TTS. llama.cpp author Georgi Gerganov has stitched together the LLaMA language model, the Whisper voice to text model (with his whisper.cpp library) and the macOS “say” command to create an entirely offline AI agent that he can talk to with his voice and that can speak replies straight back to him.
2009
Recently Google Translate announced the ability to hear translations into English spoken via text-to-speech (TTS). Looking at the Firebug Net panel for where this TTS data was coming from, I saw that the speech audio is in MP3 format and is queried via a simple HTTP GET (REST) request: http://translate.google.com/translate_tts?q=text