15 posts tagged “open-data”
2025
cityofaustin/atd-data-tech issues. I stumbled across this today while looking for interesting frequently updated data sources from local governments. It turns out the City of Austin's Transportation Data & Technology Services department run everything out of a public GitHub issues instance, which currently has 20,225 closed and 2,002 open issues. They also publish an exported copy of the issues data through the data.austintexas.gov open data portal.
OpenTimes (via) Spectacular new open geospatial project by Dan Snow:
OpenTimes is a database of pre-computed, point-to-point travel times between United States Census geographies. It lets you download bulk travel time data for free and with no limits.
Here's what I get for travel times by car from El Granada, California:
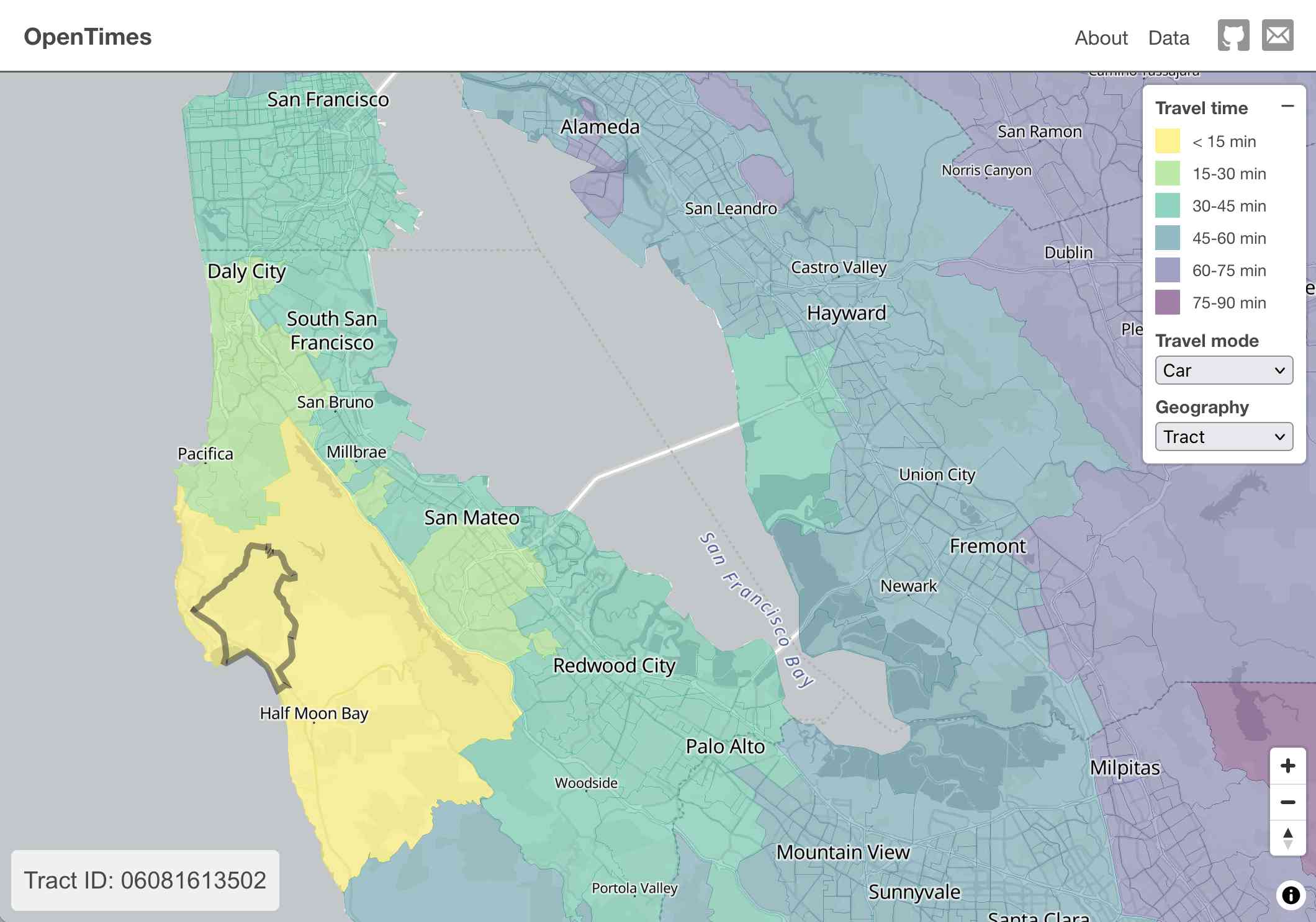
The technical details are fascinating:
- The entire OpenTimes backend is just static Parquet files on Cloudflare's R2. There's no RDBMS or running service, just files and a CDN. The whole thing costs about $10/month to host and costs nothing to serve. In my opinion, this is a great way to serve infrequently updated, large public datasets at low cost (as long as you partition the files correctly).
Sure enough, R2 pricing charges "based on the total volume of data stored" - $0.015 / GB-month for standard storage, then $0.36 / million requests for "Class B" operations which include reads. They charge nothing for outbound bandwidth.
- All travel times were calculated by pre-building the inputs (OSM, OSRM networks) and then distributing the compute over hundreds of GitHub Actions jobs. This worked shockingly well for this specific workload (and was also completely free).
Here's a GitHub Actions run of the calculate-times.yaml workflow which uses a matrix to run 255 jobs!
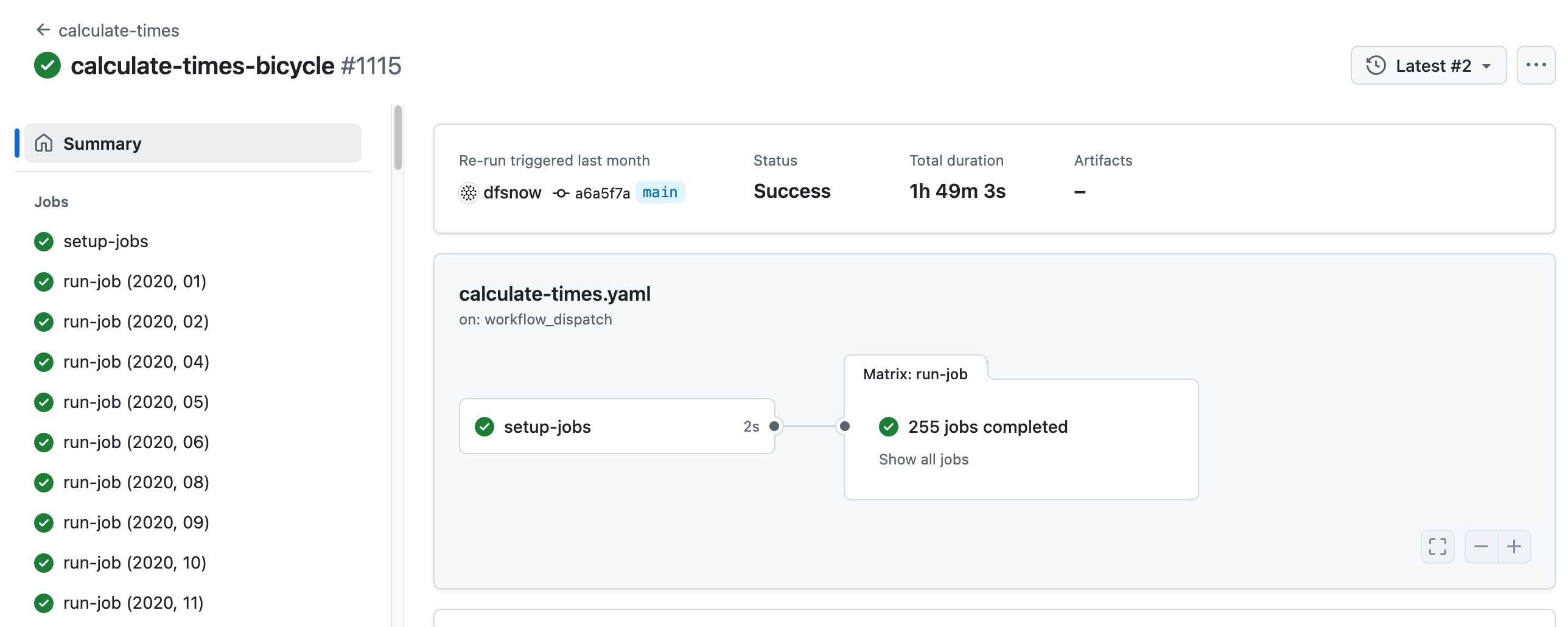
Relevant YAML:
matrix:
year: ${{ fromJSON(needs.setup-jobs.outputs.years) }}
state: ${{ fromJSON(needs.setup-jobs.outputs.states) }}
Where those JSON files were created by the previous step, which reads in the year and state values from this params.yaml file.
- The query layer uses a single DuckDB database file with views that point to static Parquet files via HTTP. This lets you query a table with hundreds of billions of records after downloading just the ~5MB pointer file.
This is a really creative use of DuckDB's feature that lets you run queries against large data from a laptop using HTTP range queries to avoid downloading the whole thing.
The README shows how to use that from R and Python - I got this working in the duckdb client (brew install duckdb):
INSTALL httpfs;
LOAD httpfs;
ATTACH 'https://data.opentimes.org/databases/0.0.1.duckdb' AS opentimes;
SELECT origin_id, destination_id, duration_sec
FROM opentimes.public.times
WHERE version = '0.0.1'
AND mode = 'car'
AND year = '2024'
AND geography = 'tract'
AND state = '17'
AND origin_id LIKE '17031%' limit 10;
In answer to a question about adding public transit times Dan said:
In the next year or so maybe. The biggest obstacles to adding public transit are:
- Collecting all the necessary scheduling data (e.g. GTFS feeds) for every transit system in the county. Not insurmountable since there are services that do this currently.
- Finding a routing engine that can compute nation-scale travel time matrices quickly. Currently, the two fastest open-source engines I've tried (OSRM and Valhalla) don't support public transit for matrix calculations and the engines that do support public transit (R5, OpenTripPlanner, etc.) are too slow.
GTFS is a popular CSV-based format for sharing transit schedules - here's an official list of available feed directories.
This whole project feels to me like a great example of the baked data architectural pattern in action.
2023
Overture Maps Foundation Releases Its First World-Wide Open Map Dataset. The Overture Maps Foundation is a collaboration lead by Amazon, Meta, Microsoft and TomTom dedicated to producing “reliable, easy-to-use, and interoperable open map data”.
Yesterday they put out their first release and it’s pretty astonishing: four different layers of geodata, covering Places of Interest (shops, restaurants, attractions etc), administrative boundaries, building outlines and transportation networks.
The data is available as Parquet. I just downloaded the 8GB places dataset and can confirm that it contains 59 million listings from around the world—I filtered to just places in my local town and a spot check showed that recently opened businesses (last 12 months) were present and the details all looked accurate.
The places data is licensed under “Community Data License Agreement – Permissive” which looks like the only restriction is that you have to include that license when you further share the data.
2022
Most researchers don’t share their data. If you’ve ever read the words “data is available upon request" in an academic paper, and emailed the authors to request it, the chances that you'll actually receive the data are just 7 percent. The rest of the time, the authors have lost access to their data, changed emails, or are too busy or unwilling.
Weeknotes: datasette-socrata, and the last 10%...
... takes 90% of the work. I continue to work towards a preview of the new Datasette Cloud, and keep finding new “just one more things” to delay inviting in users.
[... 1,214 words]2019
Usable Data (via) A Paul Ford essay from February 2016 in which he advocates for SQLite as the ideal format for sharing interesting data. I don’t know how I missed this one—it predates Datasette, but it perfectly captures the benefits that I’m trying to expose with the project. “In my dream universe, there would be a massive searchable torrent site filled with open, explorable data sets, in SQLite format, some with full text search indexes already in place.”
2018
A rating system for open data proposed by Tim Berners-Lee, founder of the World Wide Web. To score the maximum five stars, data must (1) be available on the Web under an open licence, (2) be in the form of structured data, (3) be in a non-proprietary file format, (4) use URIs as its identifiers (see also RDF), (5) include links to other data sources (see linked data). To score 3 stars, it must satisfy all of (1)-(3), etc.
2017
GOV.UK Registers (via) Canonical sources of “lists of information” intended for use by GDS teams building software for the UK government, but available for anyone. 17 registers are “ready for use”, 45 are “in progress”. Covers things like the FCO’s country list, the official list of prison estates, and DEFRA’s list of public bodies in England that manage drainage systems.
Exploring United States Policing Data Using Python. Outstanding introduction to data analysis with Jupyter and Pandas.
2010
OpenCorporates (via) “The Open Database Of The Corporate World”—a URL for every UK company.
Doing things with Ordnance Survey OpenData. Jo Walsh’s guide to processing Ordnance Survey OpenData using PostgreSQL and PostGIS.
Preview: Freebase Gridworks (via) If my experience with government datasets has taught me anything, it’s that most datasets are collected by human beings (probably using Excel) and human beings are inconsistent. The first step in any data related project inevitably involves cleaning up the data. The Freebase team must run up against this all the time, and it looks like they’re tackling the problem head-on. Freebase Gridworks is just a screencast preview at the moment but an open source release is promised “within a month”—and the tool looks absolutely fantastic. DabbleDB-style data refactoring of spreadsheet data, running on your desktop but with the UI served in a browser. Full undo, a JavaScript-based expression language, powerful faceting and the ability to “reconcile” data against Freebase types (matching up country names, for example). I can’t wait to get my hands on this.
2009
No PDFs! The Sunlight Foundation point out that PDFs are a terrible way of implementing “more transparent government” due to their general lack of structure. At the Guardian (and I’m sure at other newspapers) we waste an absurd amount of time manually extracting data from PDF files and turning it in to something more useful. Even CSV is significantly more useful for many types of information.
2008
Show Us a Better Way. The UK Government’s Power of Information Taskforce are running a mashup competition (a.k.a. “ideas for new products that could improve the way public information is communicated”) with a £20,000 prize fund and gigabytes of brand new data and APIs. This is a great opportunity for the software community to demonstrate how important this kind of open data really is.
2006
Freeing the postcode
UK postcodes have some interesting characteristics: a full six character post code identifies an average of around 14 house holds, and postcodes are mainly hierarchical—W1W will always be contained within W1 for example. They’re useful for a huge range of interesting things.
[... 295 words]