13 posts tagged “cerebras”
2026
Introducing GPT‑5.3‑Codex‑Spark. OpenAI announced a partnership with Cerebras on January 14th. Four weeks later they're already launching the first integration, "an ultra-fast model for real-time coding in Codex".
Despite being named GPT-5.3-Codex-Spark it's not purely an accelerated alternative to GPT-5.3-Codex - the blog post calls it "a smaller version of GPT‑5.3-Codex" and clarifies that "at launch, Codex-Spark has a 128k context window and is text-only."
I had some preview access to this model and I can confirm that it's significantly faster than their other models.
Here's what that speed looks like running in Codex CLI:
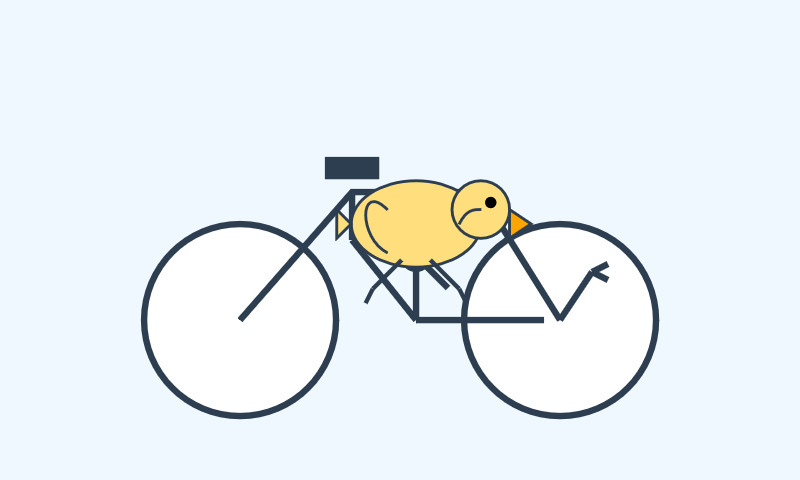
That was the "Generate an SVG of a pelican riding a bicycle" prompt - here's the rendered result:

Compare that to the speed of regular GPT-5.3 Codex medium:
Significantly slower, but the pelican is a lot better:

What's interesting about this model isn't the quality though, it's the speed. When a model responds this fast you can stay in flow state and iterate with the model much more productively.
I showed a demo of Cerebras running Llama 3.1 70 B at 2,000 tokens/second against Val Town back in October 2024. OpenAI claim 1,000 tokens/second for their new model, and I expect it will prove to be a ferociously useful partner for hands-on iterative coding sessions.
It's not yet clear what the pricing will look like for this new model.
2025
OpenAI’s new open weight (Apache 2) models are really good
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]Two interesting examples of inference speed as a flagship feature of LLM services today.
First, Cerebras announced two new monthly plans for their extremely high speed hosted model service: Cerebras Code Pro ($50/month, 1,000 messages a day) and Cerebras Code Max ($200/month, 5,000/day). The model they are selling here is Qwen's Qwen3-Coder-480B-A35B-Instruct, likely the best available open weights coding model right now and one that was released just ten days ago. Ten days from model release to third-party subscription service feels like some kind of record.
Cerebras claim they can serve the model at an astonishing 2,000 tokens per second - four times the speed of Claude Sonnet 4 in their demo video.
Also today, Moonshot announced a new hosted version of their trillion parameter Kimi K2 model called kimi-k2-turbo-preview:
🆕 Say hello to kimi-k2-turbo-preview Same model. Same context. NOW 4× FASTER.
⚡️ From 10 tok/s to 40 tok/s.
💰 Limited-Time Launch Price (50% off until Sept 1)
- $0.30 / million input tokens (cache hit)
- $1.20 / million input tokens (cache miss)
- $5.00 / million output tokens
👉 Explore more: platform.moonshot.ai
This is twice the price of their regular model for 4x the speed (increasing to 4x the price in September). No details yet on how they achieved the speed-up.
I am interested to see how much market demand there is for faster performance like this. I've experimented with Cerebras in the past and found that the speed really does make iterating on code with live previews feel a whole lot more interactive.
Magistral — the first reasoning model by Mistral AI. Mistral's first reasoning model is out today, in two sizes. There's a 24B Apache 2 licensed open-weights model called Magistral Small (actually Magistral-Small-2506), and a larger API-only model called Magistral Medium.
Magistral Small is available as mistralai/Magistral-Small-2506 on Hugging Face. From that model card:
Context Window: A 128k context window, but performance might degrade past 40k. Hence we recommend setting the maximum model length to 40k.
Mistral also released an official GGUF version, Magistral-Small-2506_gguf, which I ran successfully using Ollama like this:
ollama pull hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
That fetched a 25GB file. I ran prompts using a chat session with llm-ollama like this:
llm chat -m hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
Here's what I got for "Generate an SVG of a pelican riding a bicycle" (transcript here):

It's disappointing that the GGUF doesn't support function calling yet - hopefully a community variant can add that, it's one of the best ways I know of to unlock the potential of these reasoning models.
I just noticed that Ollama have their own Magistral model too, which can be accessed using:
ollama pull magistral:latest
That gets you a 14GB q4_K_M quantization - other options can be found in the full list of Ollama magistral tags.
One thing that caught my eye in the Magistral announcement:
Legal, finance, healthcare, and government professionals get traceable reasoning that meets compliance requirements. Every conclusion can be traced back through its logical steps, providing auditability for high-stakes environments with domain-specialized AI.
I guess this means the reasoning traces are fully visible and not redacted in any way - interesting to see Mistral trying to turn that into a feature that's attractive to the business clients they are most interested in appealing to.
Also from that announcement:
Our early tests indicated that Magistral is an excellent creative companion. We highly recommend it for creative writing and storytelling, with the model capable of producing coherent or — if needed — delightfully eccentric copy.
I haven't seen a reasoning model promoted for creative writing in this way before.
You can try out Magistral Medium by selecting the new "Thinking" option in Mistral's Le Chat.
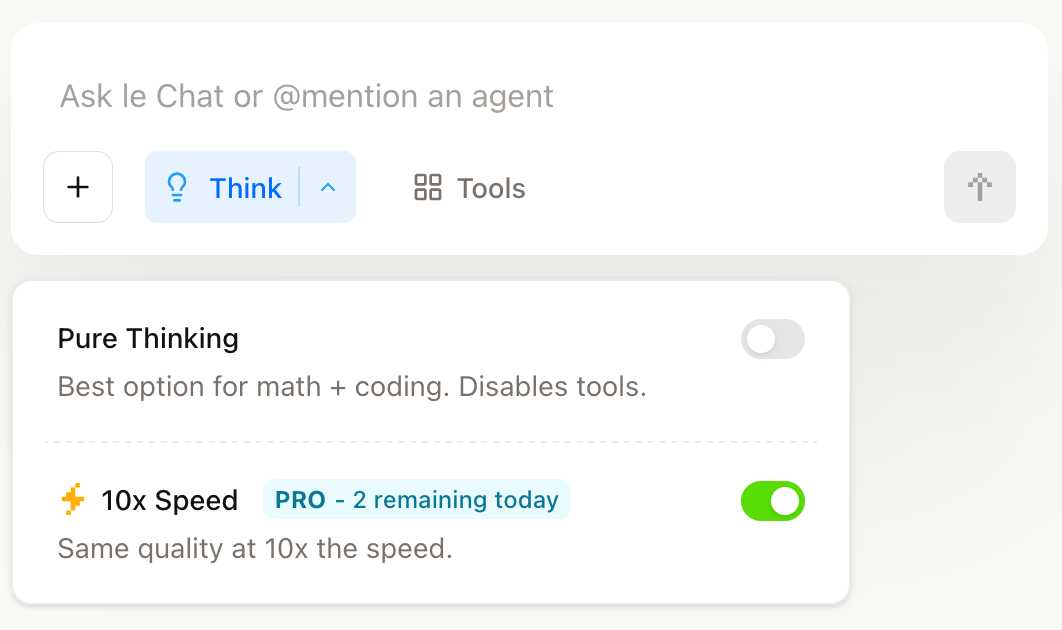
They have options for "Pure Thinking" and a separate option for "10x speed", which runs Magistral Medium at 10x the speed using Cerebras.
The new models are also available through the Mistral API. You can access them by installing llm-mistral and running llm mistral refresh to refresh the list of available models, then:
llm -m mistral/magistral-medium-latest \
'Generate an SVG of a pelican riding a bicycle'

Here's that transcript. At 13 input and 1,236 output tokens that cost me 0.62 cents - just over half a cent.
Cerebras brings instant inference to Mistral Le Chat. Mistral announced a major upgrade to their Le Chat web UI (their version of ChatGPT) a few days ago, and one of the signature features was performance.
It turns out that performance boost comes from hosting their model on Cerebras:
We are excited to bring our technology to Mistral – specifically the flagship 123B parameter Mistral Large 2 model. Using our Wafer Scale Engine technology, we achieve over 1,100 tokens per second on text queries.
Given Cerebras's so far unrivaled inference performance I'm surprised that no other AI lab has formed a partnership like this already.
The impact of competition and DeepSeek on Nvidia (via) Long, excellent piece by Jeffrey Emanuel capturing the current state of the AI/LLM industry. The original title is "The Short Case for Nvidia Stock" - I'm using the Hacker News alternative title here, but even that I feel under-sells this essay.
Jeffrey has a rare combination of experience in both computer science and investment analysis. He combines both worlds here, evaluating NVIDIA's challenges by providing deep insight into a whole host of relevant and interesting topics.
As Jeffrey describes it, NVIDA's moat has four components: high-quality Linux drivers, CUDA as an industry standard, the fast GPU interconnect technology they acquired from Mellanox in 2019 and the flywheel effect where they can invest their enormous profits (75-90% margin in some cases!) into more R&D.
Each of these is under threat.
Technologies like MLX, Triton and JAX are undermining the CUDA advantage by making it easier for ML developers to target multiple backends - plus LLMs themselves are getting capable enough to help port things to alternative architectures.
GPU interconnect helps multiple GPUs work together on tasks like model training. Companies like Cerebras are developing enormous chips that can get way more done on a single chip.
Those 75-90% margins provide a huge incentive for other companies to catch up - including the customers who spend the most on NVIDIA at the moment - Microsoft, Amazon, Meta, Google, Apple - all of whom have their own internal silicon projects:
Now, it's no secret that there is a strong power law distribution of Nvidia's hyper-scaler customer base, with the top handful of customers representing the lion's share of high-margin revenue. How should one think about the future of this business when literally every single one of these VIP customers is building their own custom chips specifically for AI training and inference?
The real joy of this article is the way it describes technical details of modern LLMs in a relatively accessible manner. I love this description of the inference-scaling tricks used by O1 and R1, compared to traditional transformers:
Basically, the way Transformers work in terms of predicting the next token at each step is that, if they start out on a bad "path" in their initial response, they become almost like a prevaricating child who tries to spin a yarn about why they are actually correct, even if they should have realized mid-stream using common sense that what they are saying couldn't possibly be correct.
Because the models are always seeking to be internally consistent and to have each successive generated token flow naturally from the preceding tokens and context, it's very hard for them to course-correct and backtrack. By breaking the inference process into what is effectively many intermediate stages, they can try lots of different things and see what's working and keep trying to course-correct and try other approaches until they can reach a fairly high threshold of confidence that they aren't talking nonsense.
The last quarter of the article talks about the seismic waves rocking the industry right now caused by DeepSeek v3 and R1. v3 remains the top-ranked open weights model, despite being around 45x more efficient in training than its competition: bad news if you are selling GPUs! R1 represents another huge breakthrough in efficiency both for training and for inference - the DeepSeek R1 API is currently 27x cheaper than OpenAI's o1, for a similar level of quality.
Jeffrey summarized some of the key ideas from the v3 paper like this:
A major innovation is their sophisticated mixed-precision training framework that lets them use 8-bit floating point numbers (FP8) throughout the entire training process. [...]
DeepSeek cracked this problem by developing a clever system that breaks numbers into small tiles for activations and blocks for weights, and strategically uses high-precision calculations at key points in the network. Unlike other labs that train in high precision and then compress later (losing some quality in the process), DeepSeek's native FP8 approach means they get the massive memory savings without compromising performance. When you're training across thousands of GPUs, this dramatic reduction in memory requirements per GPU translates into needing far fewer GPUs overall.
Then for R1:
With R1, DeepSeek essentially cracked one of the holy grails of AI: getting models to reason step-by-step without relying on massive supervised datasets. Their DeepSeek-R1-Zero experiment showed something remarkable: using pure reinforcement learning with carefully crafted reward functions, they managed to get models to develop sophisticated reasoning capabilities completely autonomously. This wasn't just about solving problems— the model organically learned to generate long chains of thought, self-verify its work, and allocate more computation time to harder problems.
The technical breakthrough here was their novel approach to reward modeling. Rather than using complex neural reward models that can lead to "reward hacking" (where the model finds bogus ways to boost their rewards that don't actually lead to better real-world model performance), they developed a clever rule-based system that combines accuracy rewards (verifying final answers) with format rewards (encouraging structured thinking). This simpler approach turned out to be more robust and scalable than the process-based reward models that others have tried.
This article is packed with insights like that - it's worth spending the time absorbing the whole thing.
100x Defect Tolerance: How Cerebras Solved the Yield Problem (via) I learned a bunch about how chip manufacture works from this piece where Cerebras reveal some notes about how they manufacture chips that are 56x physically larger than NVIDIA's H100.
The key idea here is core redundancy: designing a chip such that if there are defects the end-product is still useful. This has been a technique for decades:
For example in 2006 Intel released the Intel Core Duo – a chip with two CPU cores. If one core was faulty, it was disabled and the product was sold as an Intel Core Solo. Nvidia, AMD, and others all embraced this core-level redundancy in the coming years.
Modern GPUs are deliberately designed with redundant cores: the H100 needs 132 but the wafer contains 144, so up to 12 can be defective without the chip failing.
Cerebras designed their monster (look at the size of this thing) with absolutely tiny cores: "approximately 0.05mm2" - with the whole chip needing 900,000 enabled cores out of the 970,000 total. This allows 93% of the silicon area to stay active in the finished chip, a notably high proportion.
2024
Cerebras Coder (via) Val Town founder Steve Krouse has been building demos on top of the Cerebras API that runs Llama3.1-70b at 2,000 tokens/second.
Having a capable LLM with that kind of performance turns out to be really interesting. Cerebras Coder is a demo that implements Claude Artifact-style on-demand JavaScript apps, and having it run at that speed means changes you request are visible within less than a second:
Steve's implementation (created with the help of Townie, the Val Town code assistant) demonstrates the simplest possible version of an iframe sandbox:
<iframe
srcDoc={code}
sandbox="allow-scripts allow-modals allow-forms allow-popups allow-same-origin allow-top-navigation allow-downloads allow-presentation allow-pointer-lock"
/>
Where code is populated by a setCode(...) call inside a React component.
The most interesting applications of LLMs continue to be where they operate in a tight loop with a human - this can make those review loops potentially much faster and more productive.
Pelicans on a bicycle. I decided to roll out my own LLM benchmark: how well can different models render an SVG of a pelican riding a bicycle?
I chose that because a) I like pelicans and b) I'm pretty sure there aren't any pelican on a bicycle SVG files floating around (yet) that might have already been sucked into the training data.
My prompt:
Generate an SVG of a pelican riding a bicycle
I've run it through 16 models so far - from OpenAI, Anthropic, Google Gemini and Meta (Llama running on Cerebras), all using my LLM CLI utility. Here's my (Claude assisted) Bash script: generate-svgs.sh
Here's Claude 3.5 Sonnet (2024-06-20) and Claude 3.5 Sonnet (2024-10-22):


Gemini 1.5 Flash 001 and Gemini 1.5 Flash 002:


GPT-4o mini and GPT-4o:


o1-mini and o1-preview:


Cerebras Llama 3.1 70B and Llama 3.1 8B:


And a special mention for Gemini 1.5 Flash 8B:

The rest of them are linked from the README.
llm-cerebras. Cerebras (previously) provides Llama LLMs hosted on custom hardware at ferociously high speeds.
GitHub user irthomasthomas built an LLM plugin that works against their API - which is currently free, albeit with a rate limit of 30 requests per minute for their two models.
llm install llm-cerebras
llm keys set cerebras
# paste key here
llm -m cerebras-llama3.1-70b 'an epic tail of a walrus pirate'
Here's a video showing the speed of that prompt:
The other model is cerebras-llama3.1-8b.
Cerebras Inference: AI at Instant Speed (via) New hosted API for Llama running at absurdly high speeds: "1,800 tokens per second for Llama3.1 8B and 450 tokens per second for Llama3.1 70B".
How are they running so fast? Custom hardware. Their WSE-3 is 57x physically larger than an NVIDIA H100, and has 4 trillion transistors, 900,000 cores and 44GB of memory all on one enormous chip.
Their live chat demo just returned me a response at 1,833 tokens/second. Their API currently has a waitlist.
2023
Downloading and converting the original models (Cerebras-GPT) (via) Georgi Gerganov added support for the Apache 2 licensed Cerebras-GPT language model to his ggml C++ inference library, as used by llama.cpp.
Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models (via) The latest example of an open source large language model you can run your own hardware. This one is particularly interesting because the entire thing is under the Apache 2 license. Cerebras are an AI hardware company offering a product with 850,000 cores—this release was trained on their hardware, presumably to demonstrate its capabilities. The model comes in seven sizes from 111 million to 13 billion parameters, and the smaller sizes can be tried directly on Hugging Face.