43 posts tagged “andrej-karpathy”
2026
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref).
— Andrej Karpathy, on Claude Fable 5
I think it's non-obvious to many people that the OpenAI voice mode runs on a much older, much weaker model - it feels like the AI that you can talk to should be the smartest AI but it really isn't.
If you ask ChatGPT voice mode for its knowledge cutoff date it tells you April 2024 - it's a GPT-4o era model.
This thought inspired by this Andrej Karpathy tweet about the growing gap in understanding of AI capability based on the access points and domains people are using the models with:
[...] It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and at the same time, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems.
This part really works and has made dramatic strides because 2 properties:
- these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also
- they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them.
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]Shopify/liquid: Performance: 53% faster parse+render, 61% fewer allocations (via) PR from Shopify CEO Tobias Lütke against Liquid, Shopify's open source Ruby template engine that was somewhat inspired by Django when Tobi first created it back in 2005.
Tobi found dozens of new performance micro-optimizations using a variant of autoresearch, Andrej Karpathy's new system for having a coding agent run hundreds of semi-autonomous experiments to find new effective techniques for training nanochat.
Tobi's implementation started two days ago with this autoresearch.md prompt file and an autoresearch.sh script for the agent to run to execute the test suite and report on benchmark scores.
The PR now lists 93 commits from around 120 automated experiments. The PR description lists what worked in detail - some examples:
- Replaced StringScanner tokenizer with
String#byteindex. Single-bytebyteindexsearching is ~40% faster than regex-basedskip_until. This alone reduced parse time by ~12%.- Pure-byte
parse_tag_token. Eliminated the costlyStringScanner#string=reset that was called for every{% %}token (878 times). Manual byte scanning for tag name + markup extraction is faster than resetting and re-scanning via StringScanner. [...]- Cached small integer
to_s. Pre-computed frozen strings for 0-999 avoid 267Integer#to_sallocations per render.
This all added up to a 53% improvement on benchmarks - truly impressive for a codebase that's been tweaked by hundreds of contributors over 20 years.
I think this illustrates a number of interesting ideas:
- Having a robust test suite - in this case 974 unit tests - is a massive unlock for working with coding agents. This kind of research effort would not be possible without first having a tried and tested suite of tests.
- The autoresearch pattern - where an agent brainstorms a multitude of potential improvements and then experiments with them one at a time - is really effective.
- If you provide an agent with a benchmarking script "make it faster" becomes an actionable goal.
- CEOs can code again! Tobi has always been more hands-on than most, but this is a much more significant contribution than anyone would expect from the leader of a company with 7,500+ employees. I've seen this pattern play out a lot over the past few months: coding agents make it feasible for people in high-interruption roles to productively work with code again.
Here's Tobi's GitHub contribution graph for the past year, showing a significant uptick following that November 2025 inflection point when coding agents got really good.
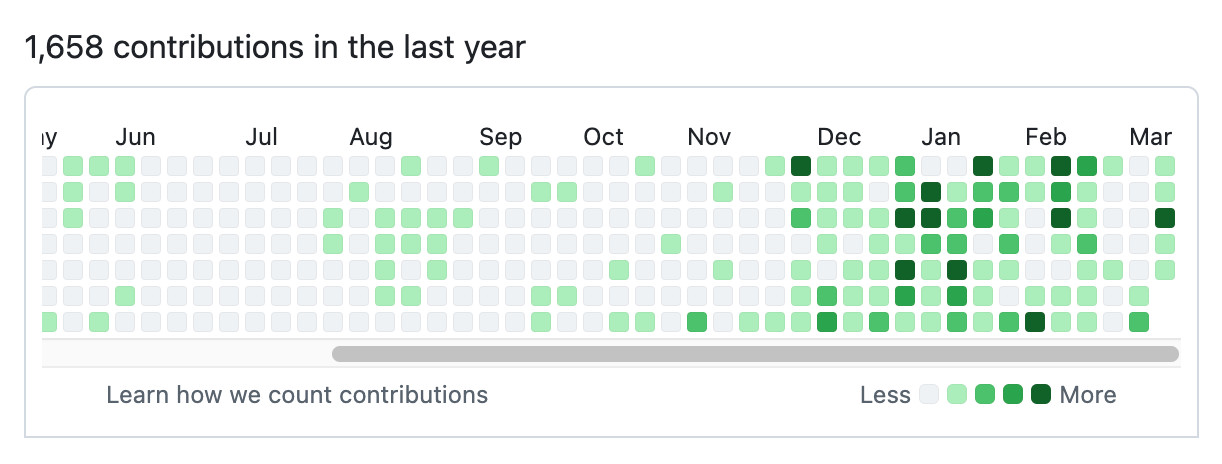
He used Pi as the coding agent and released a new pi-autoresearch plugin in collaboration with David Cortés, which maintains state in an autoresearch.jsonl file like this one.
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow. [...]
Andrej Karpathy talks about “Claws”. Andrej Karpathy tweeted a mini-essay about buying a Mac Mini ("The apple store person told me they are selling like hotcakes and everyone is confused") to tinker with Claws:
I'm definitely a bit sus'd to run OpenClaw specifically [...] But I do love the concept and I think that just like LLM agents were a new layer on top of LLMs, Claws are now a new layer on top of LLM agents, taking the orchestration, scheduling, context, tool calls and a kind of persistence to a next level.
Looking around, and given that the high level idea is clear, there are a lot of smaller Claws starting to pop out. For example, on a quick skim NanoClaw looks really interesting in that the core engine is ~4000 lines of code (fits into both my head and that of AI agents, so it feels manageable, auditable, flexible, etc.) and runs everything in containers by default. [...]
Anyway there are many others - e.g. nanobot, zeroclaw, ironclaw, picoclaw (lol @ prefixes). [...]
Not 100% sure what my setup ends up looking like just yet but Claws are an awesome, exciting new layer of the AI stack.
Andrej has an ear for fresh terminology (see vibe coding, agentic engineering) and I think he's right about this one, too: "Claw" is becoming a term of art for the entire category of OpenClaw-like agent systems - AI agents that generally run on personal hardware, communicate via messaging protocols and can both act on direct instructions and schedule tasks.
It even comes with an established emoji 🦞
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year.
2025
In 2025, Reinforcement Learning from Verifiable Rewards (RLVR) emerged as the de facto new major stage to add to this mix. By training LLMs against automatically verifiable rewards across a number of environments (e.g. think math/code puzzles), the LLMs spontaneously develop strategies that look like "reasoning" to humans - they learn to break down problem solving into intermediate calculations and they learn a number of problem solving strategies for going back and forth to figure things out (see DeepSeek R1 paper for examples).
— Andrej Karpathy, 2025 LLM Year in Review
With AI now, we are able to write new programs that we could never hope to write by hand before. We do it by specifying objectives (e.g. classification accuracy, reward functions), and we search the program space via gradient descent to find neural networks that work well against that objective.
This is my Software 2.0 blog post from a while ago. In this new programming paradigm then, the new most predictive feature to look at is verifiability. If a task/job is verifiable, then it is optimizable directly or via reinforcement learning, and a neural net can be trained to work extremely well. It's about to what extent an AI can "practice" something.
The environment has to be resettable (you can start a new attempt), efficient (a lot attempts can be made), and rewardable (there is some automated process to reward any specific attempt that was made).
Andrej Karpathy — AGI is still a decade away (via) Extremely high signal 2 hour 25 minute (!) conversation between Andrej Karpathy and Dwarkesh Patel.
It starts with Andrej's claim that "the year of agents" is actually more likely to take a decade. Seeing as I accepted 2025 as the year of agents just yesterday this instantly caught my attention!
It turns out Andrej is using a different definition of agents to the one that I prefer - emphasis mine:
When you’re talking about an agent, or what the labs have in mind and maybe what I have in mind as well, you should think of it almost like an employee or an intern that you would hire to work with you. For example, you work with some employees here. When would you prefer to have an agent like Claude or Codex do that work?
Currently, of course they can’t. What would it take for them to be able to do that? Why don’t you do it today? The reason you don’t do it today is because they just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use and all this stuff.
They don’t do a lot of the things you’ve alluded to earlier. They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking and it’s just not working. It will take about a decade to work through all of those issues.
Yeah, continual learning human-replacement agents definitely isn't happening in 2025! Coding agents that are really good at running tools in the loop on the other hand are here already.
I loved this bit introducing an analogy of LLMs as ghosts or spirits, as opposed to having brains like animals or humans:
Brains just came from a very different process, and I’m very hesitant to take inspiration from it because we’re not actually running that process. In my post, I said we’re not building animals. We’re building ghosts or spirits or whatever people want to call it, because we’re not doing training by evolution. We’re doing training by imitation of humans and the data that they’ve put on the Internet.
You end up with these ethereal spirit entities because they’re fully digital and they’re mimicking humans. It’s a different kind of intelligence. If you imagine a space of intelligences, we’re starting off at a different point almost. We’re not really building animals. But it’s also possible to make them a bit more animal-like over time, and I think we should be doing that.
The post Andrej mentions is Animals vs Ghosts on his blog.
Dwarkesh asked Andrej about this tweet where he said that Claude Code and Codex CLI "didn't work well enough at all and net unhelpful" for his nanochat project. Andrej responded:
[...] So the agents are pretty good, for example, if you’re doing boilerplate stuff. Boilerplate code that’s just copy-paste stuff, they’re very good at that. They’re very good at stuff that occurs very often on the Internet because there are lots of examples of it in the training sets of these models. There are features of things where the models will do very well.
I would say nanochat is not an example of those because it’s a fairly unique repository. There’s not that much code in the way that I’ve structured it. It’s not boilerplate code. It’s intellectually intense code almost, and everything has to be very precisely arranged. The models have so many cognitive deficits. One example, they kept misunderstanding the code because they have too much memory from all the typical ways of doing things on the Internet that I just wasn’t adopting.
Update: Here's an essay length tweet from Andrej clarifying a whole bunch of the things he talked about on the podcast.
nanochat (via) Really interesting new project from Andrej Karpathy, described at length in this discussion post.
It provides a full ChatGPT-style LLM, including training, inference and a web Ui, that can be trained for as little as $100:
This repo is a full-stack implementation of an LLM like ChatGPT in a single, clean, minimal, hackable, dependency-lite codebase.
It's around 8,000 lines of code, mostly Python (using PyTorch) plus a little bit of Rust for training the tokenizer.
Andrej suggests renting a 8XH100 NVIDA node for around $24/ hour to train the model. 4 hours (~$100) is enough to get a model that can hold a conversation - almost coherent example here. Run it for 12 hours and you get something that slightly outperforms GPT-2. I'm looking forward to hearing results from longer training runs!
The resulting model is ~561M parameters, so it should run on almost anything. I've run a 4B model on my iPhone, 561M should easily fit on even an inexpensive Raspberry Pi.
The model defaults to training on ~24GB from karpathy/fineweb-edu-100b-shuffle derived from FineWeb-Edu, and then midtrains on 568K examples from SmolTalk (460K), MMLU auxiliary train (100K), and GSM8K (8K), followed by supervised finetuning on 21.4K examples from ARC-Easy (2.3K), ARC-Challenge (1.1K), GSM8K (8K), and SmolTalk (10K).
Here's the code for the web server, which is fronted by this pleasantly succinct vanilla JavaScript HTML+JavaScript frontend.
Update: Sam Dobson pushed a build of the model to sdobson/nanochat on Hugging Face. It's designed to run on CUDA but I pointed Claude Code at a checkout and had it hack around until it figured out how to run it on CPU on macOS, which eventually resulted in this script which I've published as a Gist. You should be able to try out the model using uv like this:
cd /tmp
git clone https://huggingface.co/sdobson/nanochat
uv run https://gist.githubusercontent.com/simonw/912623bf00d6c13cc0211508969a100a/raw/80f79c6a6f1e1b5d4485368ef3ddafa5ce853131/generate_cpu.py \
--model-dir /tmp/nanochat \
--prompt "Tell me about dogs."
I got this (truncated because it ran out of tokens):
I'm delighted to share my passion for dogs with you. As a veterinary doctor, I've had the privilege of helping many pet owners care for their furry friends. There's something special about training, about being a part of their lives, and about seeing their faces light up when they see their favorite treats or toys.
I've had the chance to work with over 1,000 dogs, and I must say, it's a rewarding experience. The bond between owner and pet
The term context engineering has recently started to gain traction as a better alternative to prompt engineering. I like it. I think this one may have sticking power.
Here's an example tweet from Shopify CEO Tobi Lutke:
I really like the term “context engineering” over prompt engineering.
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
Recently amplified by Andrej Karpathy:
+1 for "context engineering" over "prompt engineering".
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting [...] Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits. [...]
I've spoken favorably of prompt engineering in the past - I hoped that term could capture the inherent complexity of constructing reliable prompts. Unfortunately, most people's inferred definition is that it's a laughably pretentious term for typing things into a chatbot!
It turns out that inferred definitions are the ones that stick. I think the inferred definition of "context engineering" is likely to be much closer to the intended meaning.
Understanding the recent criticism of the Chatbot Arena

The Chatbot Arena has become the go-to place for vibes-based evaluation of LLMs over the past two years. The project, originating at UC Berkeley, is home to a large community of model enthusiasts who submit prompts to two randomly selected anonymous models and pick their favorite response. This produces an Elo score leaderboard of the “best” models, similar to how chess rankings work.
[... 1,579 words]Semantic Diffusion. I learned about this term today while complaining about how the definition of "vibe coding" is already being distorted to mean "any time an LLM writes code" as opposed to the intended meaning of "code I wrote with an LLM without even reviewing what it wrote".
I posted this salty note:
Feels like I'm losing the battle on this one, I keep seeing people use "vibe coding" to mean any time an LLM is used to write code
I'm particularly frustrated because for a few glorious moments we had the chance at having ONE piece of AI-related terminology with a clear, widely accepted definition!
But it turns out people couldn't be trusted to read all the way to the end of Andrej's tweet, so now we are back to yet another term where different people assume it means different things
Martin Fowler coined Semantic Diffusion in 2006 with this very clear definition:
Semantic diffusion occurs when you have a word that is coined by a person or group, often with a pretty good definition, but then gets spread through the wider community in a way that weakens that definition. This weakening risks losing the definition entirely - and with it any usefulness to the term. [...]
Semantic diffusion is essentially a succession of the telephone game where a different group of people to the originators of a term start talking about it without being careful about following the original definition.
What's happening with vibe coding right now is such a clear example of this effect in action! I've seen the same thing happen to my own coinage prompt injection over the past couple of years.
This kind of dillution of meaning is frustrating, but does appear to be inevitable. As Martin Fowler points out it's most likely to happen to popular terms - the more popular a term is the higher the chance a game of telephone will ensue where misunderstandings flourish as the chain continues to grow.
Andrej Karpathy, who coined vibe coding, posted this just now in reply to my article:
Good post! It will take some time to settle on definitions. Personally I use "vibe coding" when I feel like this dog. My iOS app last night being a good example. But I find that in practice I rarely go full out vibe coding, and more often I still look at the code, I add complexity slowly and I try to learn over time how the pieces work, to ask clarifying questions etc.

{kind=link}
I love that vibe coding has an official illustrative GIF now!
Not all AI-assisted programming is vibe coding (but vibe coding rocks)
Vibe coding is having a moment. The term was coined by Andrej Karpathy just a few weeks ago (on February 6th) and has since been featured in the New York Times, Ars Technica, the Guardian and countless online discussions.
[... 1,486 words]Will the future of software development run on vibes? I got a few quotes in this piece by Benj Edwards about vibe coding, the term Andrej Karpathy coined for when you prompt an LLM to write code, accept all changes and keep feeding it prompts and error messages and see what you can get it to build.
Here's what I originally sent to Benj:
I really enjoy vibe coding - it's a fun way to play with the limits of these models. It's also useful for prototyping, where the aim of the exercise is to try out an idea and prove if it can work.
Where vibe coding fails is in producing maintainable code for production settings. I firmly believe that as a developer you have to take accountability for the code you produce - if you're going to put your name to it you need to be confident that you understand how and why it works - ideally to the point that you can explain it to somebody else.
Vibe coding your way to a production codebase is clearly a terrible idea. Most of the work we do as software engineers is about evolving existing systems, and for those the quality and understandability of the underlying code is crucial.
For experiments and low-stake projects where you want to explore what's possible and build fun prototypes? Go wild! But stay aware of the very real risk that a good enough prototype often faces pressure to get pushed to production.
If an LLM wrote every line of your code but you've reviewed, tested and understood it all, that's not vibe coding in my book - that's using an LLM as a typing assistant.
Initial impressions of GPT-4.5
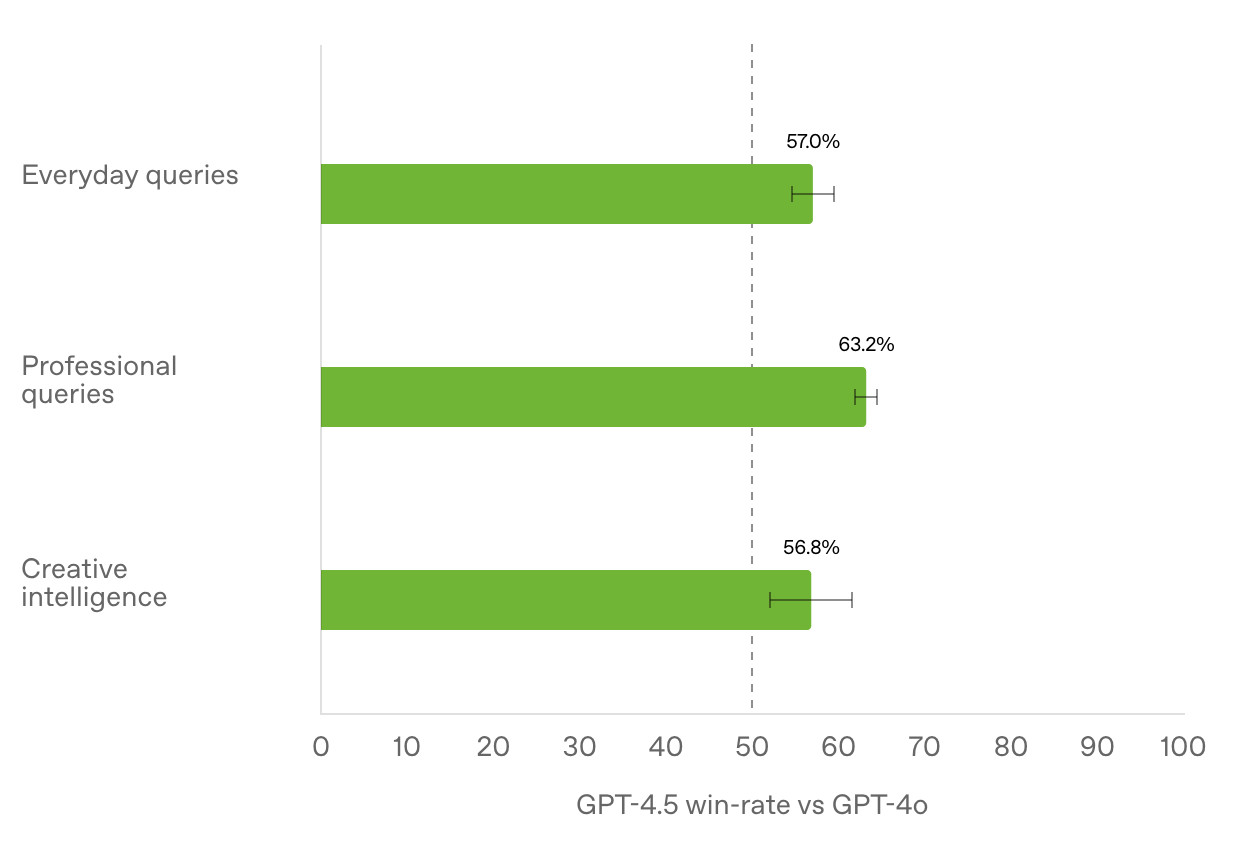
GPT-4.5 is out today as a “research preview”—it’s available to OpenAI Pro ($200/month) customers and to developers with an API key. OpenAI also published a GPT-4.5 system card.
[... 745 words]Andrej Karpathy’s initial impressions of Grok 3. Andrej has the most detailed analysis I've seen so far of xAI's Grok 3 release from last night. He runs through a bunch of interesting test prompts, and concludes:
As far as a quick vibe check over ~2 hours this morning, Grok 3 + Thinking feels somewhere around the state of the art territory of OpenAI's strongest models (o1-pro, $200/month), and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking. Which is quite incredible considering that the team started from scratch ~1 year ago, this timescale to state of the art territory is unprecedented.
I was delighted to see him include my Generate an SVG of a pelican riding a bicycle benchmark in his tests:
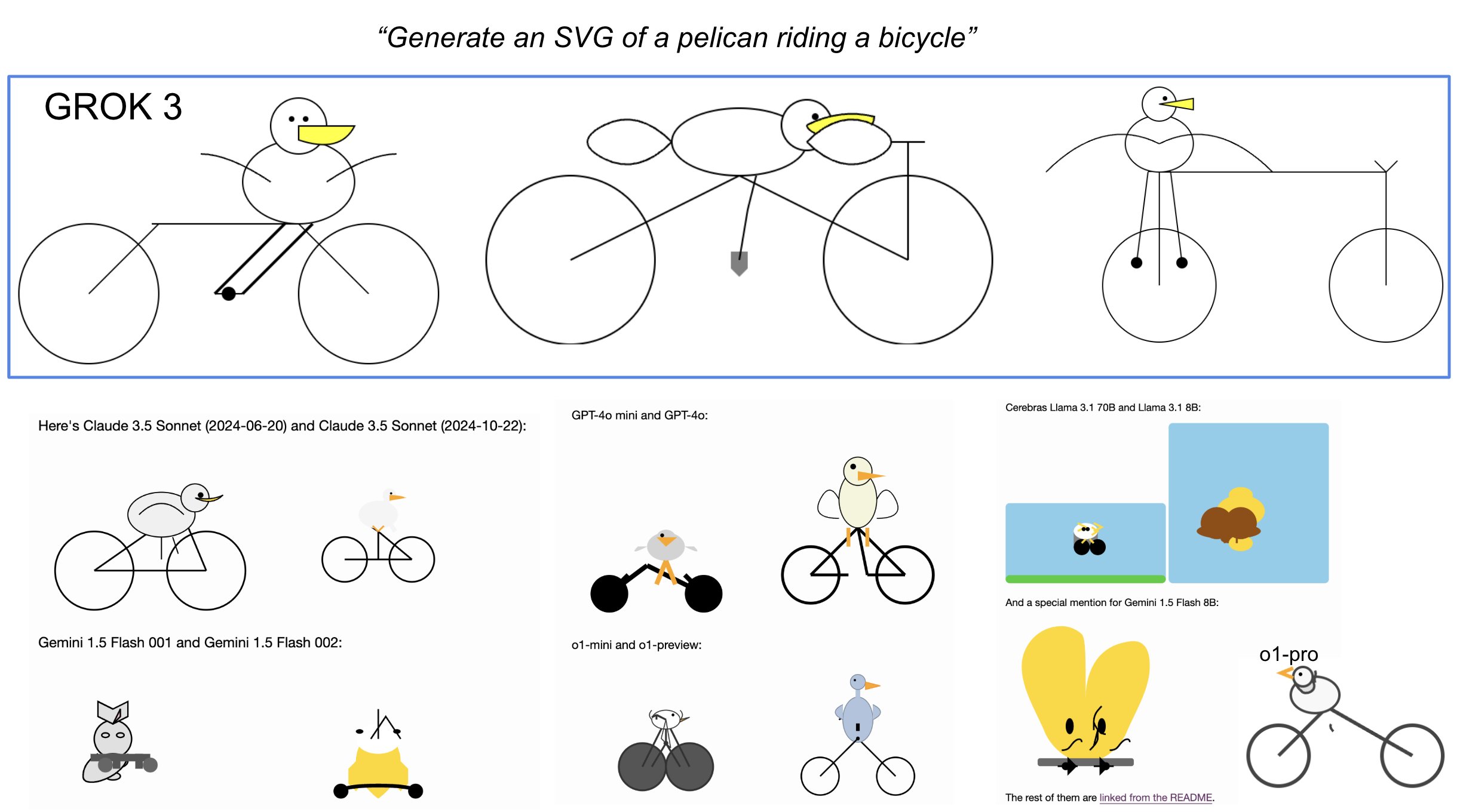
Grok 3 is currently sat at the top of the LLM Chatbot Arena (across all of their categories) so it's doing very well based on vibes for the voters there.
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard.
I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away.
It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
2024
DeepSeek_V3.pdf (via) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented model weights.
Plenty of interesting details in here. The model pre-trained on 14.8 trillion "high-quality and diverse tokens" (not otherwise documented).
Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
By far the most interesting detail though is how much the training cost. DeepSeek v3 trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. For comparison, Meta AI's Llama 3.1 405B (smaller than DeepSeek v3's 685B parameters) trained on 11x that - 30,840,000 GPU hours, also on 15 trillion tokens.
DeepSeek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now possible to train a frontier-class model (at least for the 2024 version of the frontier) for less than $6 million!
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
DeepSeek also announced their API pricing. From February 8th onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Claude 3.5 Sonnet is currently $3/million for input and $15/million for output, so if the models are indeed of equivalent quality this is a dramatic new twist in the ongoing LLM pricing wars.
People have too inflated sense of what it means to "ask an AI" about something. The AI are language models trained basically by imitation on data from human labelers. Instead of the mysticism of "asking an AI", think of it more as "asking the average data labeler" on the internet. [...]
Post triggered by someone suggesting we ask an AI how to run the government etc. TLDR you're not asking an AI, you're asking some mashup spirit of its average data labeler.
It's a bit sad and confusing that LLMs ("Large Language Models") have little to do with language; It's just historical. They are highly general purpose technology for statistical modeling of token streams. A better name would be Autoregressive Transformers or something.
They don't care if the tokens happen to represent little text chunks. It could just as well be little image patches, audio chunks, action choices, molecules, or whatever. If you can reduce your problem to that of modeling token streams (for any arbitrary vocabulary of some set of discrete tokens), you can "throw an LLM at it".
AI-powered Git Commit Function
(via)
Andrej Karpathy built a shell alias, gcm, which passes your staged Git changes to an LLM via my LLM tool, generates a short commit message and then asks you if you want to "(a)ccept, (e)dit, (r)egenerate, or (c)ancel?".
Here's the incantation he's using to generate that commit message:
git diff --cached | llm "
Below is a diff of all staged changes, coming from the command:
\`\`\`
git diff --cached
\`\`\`
Please generate a concise, one-line commit message for these changes."This pipes the data into LLM (using the default model, currently gpt-4o-mini unless you set it to something else) and then appends the prompt telling it what to do with that input.
SQL injection-like attack on LLMs with special tokens. Andrej Karpathy explains something that's been confusing me for the best part of a year:
The decision by LLM tokenizers to parse special tokens in the input string (
<s>,<|endoftext|>, etc.), while convenient looking, leads to footguns at best and LLM security vulnerabilities at worst, equivalent to SQL injection attacks.
LLMs frequently expect you to feed them text that is templated like this:
<|user|>\nCan you introduce yourself<|end|>\n<|assistant|>
But what happens if the text you are processing includes one of those weird sequences of characters, like <|assistant|>? Stuff can definitely break in very unexpected ways.
LLMs generally reserve special token integer identifiers for these, which means that it should be possible to avoid this scenario by encoding the special token as that ID (for example 32001 for <|assistant|> in the Phi-3-mini-4k-instruct vocabulary) while that same sequence of characters in untrusted text is encoded as a longer sequence of smaller tokens.
Many implementations fail to do this! Thanks to Andrej I've learned that modern releases of Hugging Face transformers have a split_special_tokens=True parameter (added in 4.32.0 in August 2023) that can handle it. Here's an example:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
>>> tokenizer.encode("<|assistant|>")
[32001]
>>> tokenizer.encode("<|assistant|>", split_special_tokens=True)
[529, 29989, 465, 22137, 29989, 29958]A better option is to use the apply_chat_template() method, which should correctly handle this for you (though I'd like to see confirmation of that).
The RM [Reward Model] we train for LLMs is just a vibe check […] It gives high scores to the kinds of assistant responses that human raters statistically seem to like. It's not the "actual" objective of correctly solving problems, it's a proxy objective of what looks good to humans. Second, you can't even run RLHF for too long because your model quickly learns to respond in ways that game the reward model. […]
No production-grade actual RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale. And intuitively, this is because getting actual rewards (i.e. the equivalent of win the game) is really difficult in the open-ended problem solving tasks. […] But how do you give an objective reward for summarizing an article? Or answering a slightly ambiguous question about some pip install issue? Or telling a joke? Or re-writing some Java code to Python?
The reason current models are so large is because we're still being very wasteful during training - we're asking them to memorize the internet and, remarkably, they do and can e.g. recite SHA hashes of common numbers, or recall really esoteric facts. (Actually LLMs are really good at memorization, qualitatively a lot better than humans, sometimes needing just a single update to remember a lot of detail for a long time). But imagine if you were going to be tested, closed book, on reciting arbitrary passages of the internet given the first few words. This is the standard (pre)training objective for models today. The reason doing better is hard is because demonstrations of thinking are "entangled" with knowledge, in the training data.
Therefore, the models have to first get larger before they can get smaller, because we need their (automated) help to refactor and mold the training data into ideal, synthetic formats.
It's a staircase of improvement - of one model helping to generate the training data for next, until we're left with "perfect training set". When you train GPT-2 on it, it will be a really strong / smart model by today's standards. Maybe the MMLU will be a bit lower because it won't remember all of its chemistry perfectly.
Introducing Eureka Labs (via) Andrej Karpathy's new AI education company, exploring an AI-assisted teaching model:
The teacher still designs the course materials, but they are supported, leveraged and scaled with an AI Teaching Assistant who is optimized to help guide the students through them. This Teacher + AI symbiosis could run an entire curriculum of courses on a common platform.
On Twitter Andrej says:
@EurekaLabsAI is the culmination of my passion in both AI and education over ~2 decades. My interest in education took me from YouTube tutorials on Rubik's cubes to starting CS231n at Stanford, to my more recent Zero-to-Hero AI series. While my work in AI took me from academic research at Stanford to real-world products at Tesla and AGI research at OpenAI. All of my work combining the two so far has only been part-time, as side quests to my "real job", so I am quite excited to dive in and build something great, professionally and full-time.
The first course will be LLM101n - currently just a stub on GitHub, but with the goal to build an LLM chat interface "from scratch in Python, C and CUDA, and with minimal computer science prerequisites".
Turns out that LLMs learn a lot better and faster from educational content as well. This is partly because the average Common Crawl article (internet pages) is not of very high value and distracts the training, packing in too much irrelevant information. The average webpage on the internet is so random and terrible it's not even clear how prior LLMs learn anything at all.
The realization hit me [when the GPT-3 paper came out] that an important property of the field flipped. In ~2011, progress in AI felt constrained primarily by algorithms. We needed better ideas, better modeling, better approaches to make further progress. If you offered me a 10X bigger computer, I'm not sure what I would have even used it for. GPT-3 paper showed that there was this thing that would just become better on a large variety of practical tasks, if you only trained a bigger one. Better algorithms become a bonus, not a necessity for progress in AGI. Possibly not forever and going forward, but at least locally and for the time being, in a very practical sense. Today, if you gave me a 10X bigger computer I would know exactly what to do with it, and then I'd ask for more.
Reproducing GPT-2 (124M) in llm.c in 90 minutes for $20 (via) GPT-2 124M was the smallest model in the GPT-2 series released by OpenAI back in 2019. Andrej Karpathy's llm.c is an evolving 4,000 line C/CUDA implementation which can now train a GPT-2 model from scratch in 90 minutes against a 8X A100 80GB GPU server. This post walks through exactly how to run the training, using 10 billion tokens of FineWeb.
Andrej notes that this isn't actually that far off being able to train a GPT-3:
Keep in mind that here we trained for 10B tokens, while GPT-3 models were all trained for 300B tokens. [...] GPT-3 actually didn't change too much at all about the model (context size 1024 -> 2048, I think that's it?).
Estimated cost for a GPT-3 ADA (350M parameters)? About $2,000.