34 posts tagged “ai-assisted-search”
Using LLMs to build better search engines, and providing search tool access to LLMs.
2025
My trepidation extends to complex literature searches. I use LLMs as secondary librarians when I’m doing research. They reliably find primary sources (articles, papers, etc.) that I miss in my initial searches.
But these searches are dangerous. I distrust LLM librarians. There is so much data in the world: you can (in good faith!) find evidence to support almost any position or conclusion. ChatGPT is not a human, and, unlike teachers & librarians & scholars, ChatGPT does not have a consistent, legible worldview. In my experience, it readily agrees with any premise you hand it — and brings citations. It may have read every article that can be read, but it has no real opinion — so it is not a credible expert.
— Ben Stolovitz, How I use AI
London Transport Museum Depot Open Days. I just found out about this (thanks, ChatGPT) and I'm heart-broken to learn that I'm in London a week too early! If you are in London next week (Thursday 18th through Sunday 21st 2025) you should definitely know about it:
The Museum Depot in Acton is our working museum store, and a treasure trove of over 320,000 objects.
Three times a year, we throw open the doors and welcome thousands of visitors to explore. Discover rare road and rail vehicles spanning over 100 years, signs, ceramic tiles, original posters, ephemera, ticket machines, and more.
And if you can go on Saturday 20th or Sunday 21st you can ride the small-scale railway there!
The Depot is also home to the London Transport Miniature Railway, a working miniature railway based on real London Underground locomotives, carriages, signals and signs run by our volunteers.
Note that this "miniature railway" is not the same thing as a model railway - it uses a 7¼ in gauge railway and you can sit on top of and ride the carriages.
Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide
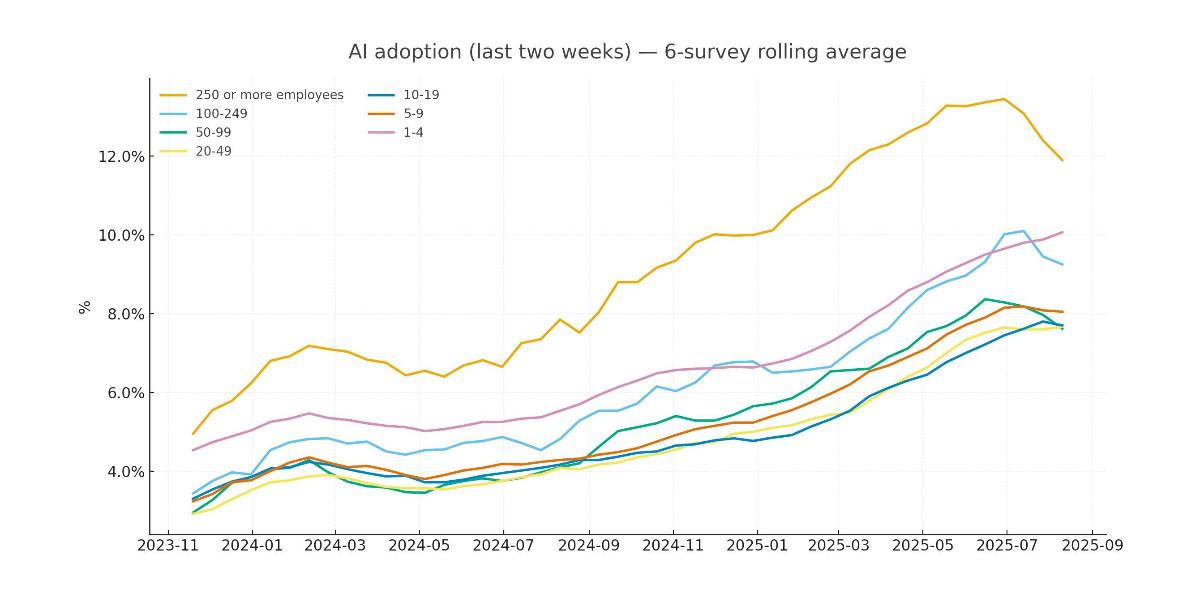
Apollo Global Management’s “Chief Economist” Dr. Torsten Sløk released this interesting chart which appears to show a slowdown in AI adoption rates among large (>250 employees) companies:
[... 2,673 words]Is the LLM response wrong, or have you just failed to iterate it? (via) More from Mike Caulfield (see also the SIFT method). He starts with a fantastic example of Google's AI mode usually correctly handling a common piece of misinformation but occasionally falling for it (the curse of non-deterministic systems), then shows an example if what he calls a "sorting prompt" as a follow-up:
What is the evidence for and against this being a real photo of Shirley Slade?
The response starts with a non-committal "there is compelling evidence for and against...", then by the end has firmly convinced itself that the photo is indeed a fake. It reads like a fact-checking variant of "think step by step".
Mike neatly describes a problem I've also observed recently where "hallucination" is frequently mis-applied as meaning any time a model makes a mistake:
The term hallucination has become nearly worthless in the LLM discourse. It initially described a very weird, mostly non-humanlike behavior where LLMs would make up things out of whole cloth that did not seem to exist as claims referenced any known source material or claims inferable from any known source material. Hallucinations as stuff made up out of nothing. Subsequently people began calling any error or imperfect summary a hallucination, rendering the term worthless.
In this example is the initial incorrect answers were not hallucinations: they correctly summarized online content that contained misinformation. The trick then is to encourage the model to look further, using "sorting prompts" like these:
- Facts and misconceptions and hype about what I posted
- What is the evidence for and against the claim I posted
- Look at the most recent information on this issue, summarize how it shifts the analysis (if at all), and provide link to the latest info
I appreciated this closing footnote:
Should platforms have more features to nudge users to this sort of iteration? Yes. They should. Getting people to iterate investigation rather than argue with LLMs would be a good first step out of this mess that the chatbot model has created.
The SIFT method (via) The SIFT method is "an evaluation strategy developed by digital literacy expert, Mike Caulfield, to help determine whether online content can be trusted for credible or reliable sources of information."
This looks extremely useful as a framework for helping people more effectively consume information online (increasingly gathered with the help of LLMs).
- Stop. "Be aware of your emotional response to the headline or information in the article" to protect against clickbait, and don't read further or share until you've applied the other three steps.
- Investigate the Source. Apply lateral reading, checking what others say about the source rather than just trusting their "about" page.
- Find Better Coverage. "Use lateral reading to see if you can find other sources corroborating the same information or disputing it" and consult trusted fact checkers if necessary.
- Trace Claims, Quotes, and Media to their Original Context. Try to find the original report or referenced material to learn more and check it isn't being represented out of context.
This framework really resonates with me: it formally captures and improves on a bunch of informal techniques I've tried to apply in my own work.
When I wrote about how good ChatGPT with GPT-5 is at search yesterday I nearly added a note about how comparatively disappointing Google's efforts around this are.
I'm glad I left that out, because it turns out Google's new "AI mode" is genuinely really good! It feels very similar to GPT-5 search but returns results much faster.
www.google.com/ai (not available in the EU, as I found out this morning since I'm staying in France for a few days.)
Here's what I got for the following question:
Anthropic but lots of physical books and cut them up and scan them for training data. Do any other AI labs do the same thing?
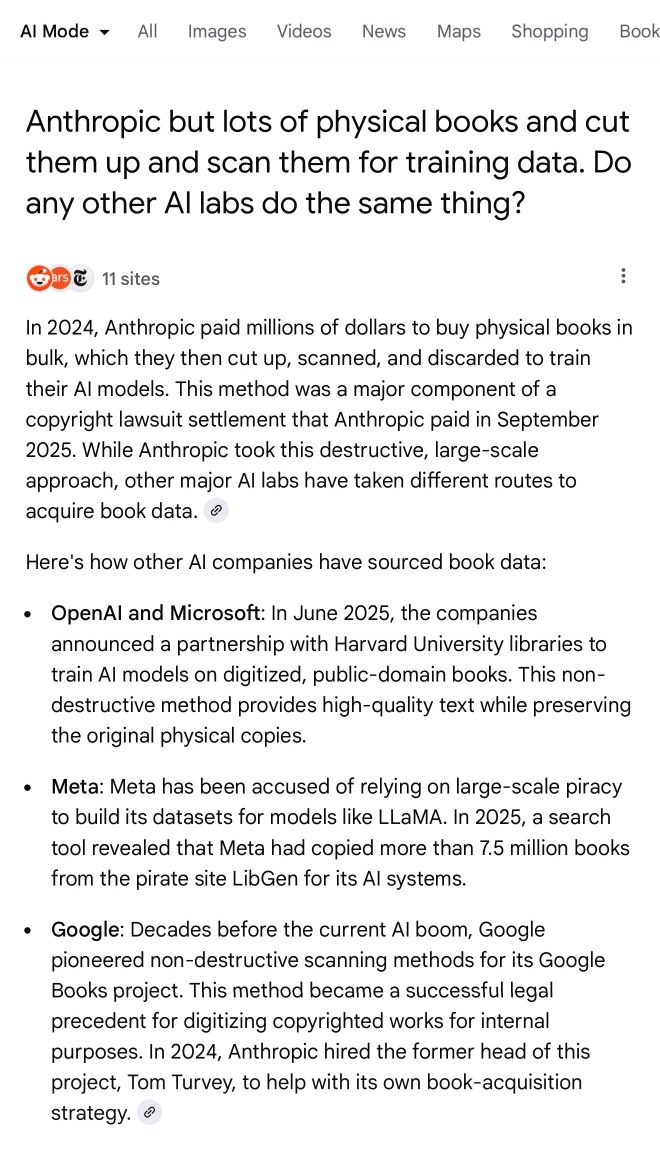
I'll be honest: I hadn't spent much time with AI mode for a couple of reasons:
- My expectations of "AI mode" were extremely low based on my terrible experience of "AI overviews"
- The name "AI mode" is so generic!
Based on some initial experiments I'm impressed - Google finally seem to be taking full advantage of their search infrastructure for building out truly great AI-assisted search.
I do have one disappointment: AI mode will tell you that it's "running 5 searches" but it won't tell you what those searches are! Seeing the searches that were run is really important for me in evaluating the likely quality of the end results. I've had the same problem with Google's Gemini app in the past - the lack of transparency as to what it's doing really damages my trust.
GPT-5 Thinking in ChatGPT (aka Research Goblin) is shockingly good at search

“Don’t use chatbots as search engines” was great advice for several years... until it wasn’t.
[... 2,679 words]Anthropic: How we built our multi-agent research system. OK, I'm sold on multi-agent LLM systems now.
I've been pretty skeptical of these until recently: why make your life more complicated by running multiple different prompts in parallel when you can usually get something useful done with a single, carefully-crafted prompt against a frontier model?
This detailed description from Anthropic about how they engineered their "Claude Research" tool has cured me of that skepticism.
Reverse engineering Claude Code had already shown me a mechanism where certain coding research tasks were passed off to a "sub-agent" using a tool call. This new article describes a more sophisticated approach.
They start strong by providing a clear definition of how they'll be using the term "agent" - it's the "tools in a loop" variant:
A multi-agent system consists of multiple agents (LLMs autonomously using tools in a loop) working together. Our Research feature involves an agent that plans a research process based on user queries, and then uses tools to create parallel agents that search for information simultaneously.
Why use multiple agents for a research system?
The essence of search is compression: distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously before condensing the most important tokens for the lead research agent. [...]
Our internal evaluations show that multi-agent research systems excel especially for breadth-first queries that involve pursuing multiple independent directions simultaneously. We found that a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2% on our internal research eval. For example, when asked to identify all the board members of the companies in the Information Technology S&P 500, the multi-agent system found the correct answers by decomposing this into tasks for subagents, while the single agent system failed to find the answer with slow, sequential searches.
As anyone who has spent time with Claude Code will already have noticed, the downside of this architecture is that it can burn a lot more tokens:
There is a downside: in practice, these architectures burn through tokens fast. In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats. For economic viability, multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance. [...]
We’ve found that multi-agent systems excel at valuable tasks that involve heavy parallelization, information that exceeds single context windows, and interfacing with numerous complex tools.
The key benefit is all about managing that 200,000 token context limit. Each sub-task has its own separate context, allowing much larger volumes of content to be processed as part of the research task.
Providing a "memory" mechanism is important as well:
The LeadResearcher begins by thinking through the approach and saving its plan to Memory to persist the context, since if the context window exceeds 200,000 tokens it will be truncated and it is important to retain the plan.
The rest of the article provides a detailed description of the prompt engineering process needed to build a truly effective system:
Early agents made errors like spawning 50 subagents for simple queries, scouring the web endlessly for nonexistent sources, and distracting each other with excessive updates. Since each agent is steered by a prompt, prompt engineering was our primary lever for improving these behaviors. [...]
In our system, the lead agent decomposes queries into subtasks and describes them to subagents. Each subagent needs an objective, an output format, guidance on the tools and sources to use, and clear task boundaries.
They got good results from having special agents help optimize those crucial tool descriptions:
We even created a tool-testing agent—when given a flawed MCP tool, it attempts to use the tool and then rewrites the tool description to avoid failures. By testing the tool dozens of times, this agent found key nuances and bugs. This process for improving tool ergonomics resulted in a 40% decrease in task completion time for future agents using the new description, because they were able to avoid most mistakes.
Sub-agents can run in parallel which provides significant performance boosts:
For speed, we introduced two kinds of parallelization: (1) the lead agent spins up 3-5 subagents in parallel rather than serially; (2) the subagents use 3+ tools in parallel. These changes cut research time by up to 90% for complex queries, allowing Research to do more work in minutes instead of hours while covering more information than other systems.
There's also an extensive section about their approach to evals - they found that LLM-as-a-judge worked well for them, but human evaluation was essential as well:
We often hear that AI developer teams delay creating evals because they believe that only large evals with hundreds of test cases are useful. However, it’s best to start with small-scale testing right away with a few examples, rather than delaying until you can build more thorough evals. [...]
In our case, human testers noticed that our early agents consistently chose SEO-optimized content farms over authoritative but less highly-ranked sources like academic PDFs or personal blogs. Adding source quality heuristics to our prompts helped resolve this issue.
There's so much useful, actionable advice in this piece. I haven't seen anything else about multi-agent system design that's anywhere near this practical.
They even added some example prompts from their Research system to their open source prompting cookbook. Here's the bit that encourages parallel tool use:
<use_parallel_tool_calls> For maximum efficiency, whenever you need to perform multiple independent operations, invoke all relevant tools simultaneously rather than sequentially. Call tools in parallel to run subagents at the same time. You MUST use parallel tool calls for creating multiple subagents (typically running 3 subagents at the same time) at the start of the research, unless it is a straightforward query. For all other queries, do any necessary quick initial planning or investigation yourself, then run multiple subagents in parallel. Leave any extensive tool calls to the subagents; instead, focus on running subagents in parallel efficiently. </use_parallel_tool_calls>
And an interesting description of the OODA research loop used by the sub-agents:
Research loop: Execute an excellent OODA (observe, orient, decide, act) loop by (a) observing what information has been gathered so far, what still needs to be gathered to accomplish the task, and what tools are available currently; (b) orienting toward what tools and queries would be best to gather the needed information and updating beliefs based on what has been learned so far; (c) making an informed, well-reasoned decision to use a specific tool in a certain way; (d) acting to use this tool. Repeat this loop in an efficient way to research well and learn based on new results.
AI assisted search-based research actually works now
For the past two and a half years the feature I’ve most wanted from LLMs is the ability to take on search-based research tasks on my behalf. We saw the first glimpses of this back in early 2023, with Perplexity (first launched December 2022, first prompt leak in January 2023) and then the GPT-4 powered Microsoft Bing (which launched/cratered spectacularly in February 2023). Since then a whole bunch of people have taken a swing at this problem, most notably Google Gemini and ChatGPT Search.
[... 1,618 words]An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
Anthropic Trust Center: Brave Search added as a subprocessor (via) Yesterday I was trying to figure out if Anthropic has rolled their own search index for Claude's new web search feature or if they were working with a partner. Here's confirmation that they are using Brave Search:
Anthropic's subprocessor list. As of March 19, 2025, we have made the following changes:
Subprocessors added:
- Brave Search (more info)
That "more info" links to the help page for their new web search feature.
I confirmed this myself by prompting Claude to "Search for pelican facts" - it ran a search for "Interesting pelican facts" and the ten results it showed as citations were an exact match for that search on Brave.
And further evidence: if you poke at it a bit Claude will reveal the definition of its web_search function which looks like this - note the BraveSearchParams property:
{
"description": "Search the web",
"name": "web_search",
"parameters": {
"additionalProperties": false,
"properties": {
"query": {
"description": "Search query",
"title": "Query",
"type": "string"
}
},
"required": [
"query"
],
"title": "BraveSearchParams",
"type": "object"
}
}Claude can now search the web. Claude 3.7 Sonnet on the paid plan now has a web search tool that can be turned on as a global setting.
This was sorely needed. ChatGPT, Gemini and Grok all had this ability already, and despite Anthropic's excellent model quality it was one of the big remaining reasons to keep other models in daily rotation.
For the moment this is purely a product feature - it's available through their consumer applications but there's no indication of whether or not it will be coming to the Anthropic API. (Update: it was added to their API on May 7th 2025.) OpenAI launched the latest version of web search in their API last week.
Surprisingly there are no details on how it works under the hood. Is this a partnership with someone like Bing, or is it Anthropic's own proprietary index populated by their own crawlers?
I think it may be their own infrastructure, but I've been unable to confirm that.
Update: it's confirmed as Brave Search.
Their support site offers some inconclusive hints.
Does Anthropic crawl data from the web, and how can site owners block the crawler? talks about their ClaudeBot crawler but the language indicates it's used for training data, with no mention of a web search index.
Blocking and Removing Content from Claude looks a little more relevant, and has a heading "Blocking or removing websites from Claude web search" which includes this eyebrow-raising tip:
Removing content from your site is the best way to ensure that it won't appear in Claude outputs when Claude searches the web.
And then this bit, which does mention "our partners":
The noindex robots meta tag is a rule that tells our partners not to index your content so that they don’t send it to us in response to your web search query. Your content can still be linked to and visited through other web pages, or directly visited by users with a link, but the content will not appear in Claude outputs that use web search.
Both of those documents were last updated "over a week ago", so it's not clear to me if they reflect the new state of the world given today's feature launch or not.
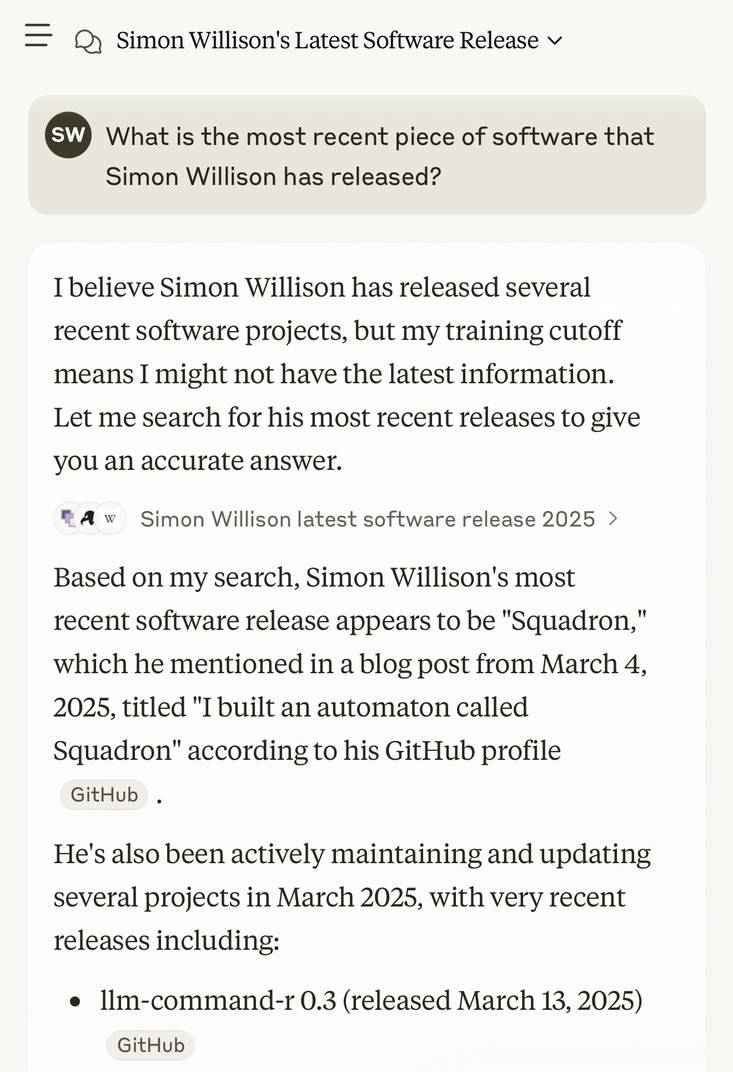
I got this delightful response trying out Claude search where it mistook my recent Squadron automata for a software project:
OpenAI API: Responses vs. Chat Completions. OpenAI released a bunch of new API platform features this morning under the headline "New tools for building agents" (their somewhat mushy interpretation of "agents" here is "systems that independently accomplish tasks on behalf of users").
A particularly significant change is the introduction of a new Responses API, which is a slightly different shape from the Chat Completions API that they've offered for the past couple of years and which others in the industry have widely cloned as an ad-hoc standard.
In this guide they illustrate the differences, with a reassuring note that:
The Chat Completions API is an industry standard for building AI applications, and we intend to continue supporting this API indefinitely. We're introducing the Responses API to simplify workflows involving tool use, code execution, and state management. We believe this new API primitive will allow us to more effectively enhance the OpenAI platform into the future.
An API that is going away is the Assistants API, a perpetual beta first launched at OpenAI DevDay in 2023. The new responses API solves effectively the same problems but better, and assistants will be sunset "in the first half of 2026".
The best illustration I've seen of the differences between the two is this giant commit to the openai-python GitHub repository updating ALL of the example code in one go.
The most important feature of the Responses API (a feature it shares with the old Assistants API) is that it can manage conversation state on the server for you. An oddity of the Chat Completions API is that you need to maintain your own records of the current conversation, sending back full copies of it with each new prompt. You end up making API calls that look like this (from their examples):
{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "knock knock.",
},
{
"role": "assistant",
"content": "Who's there?",
},
{
"role": "user",
"content": "Orange."
}
]
}These can get long and unwieldy - especially when attachments such as images are involved - but the real challenge is when you start integrating tools: in a conversation with tool use you'll need to maintain that full state and drop messages in that show the output of the tools the model requested. It's not a trivial thing to work with.
The new Responses API continues to support this list of messages format, but you also get the option to outsource that to OpenAI entirely: you can add a new "store": true property and then in subsequent messages include a "previous_response_id: response_id key to continue that conversation.
This feels a whole lot more natural than the Assistants API, which required you to think in terms of threads, messages and runs to achieve the same effect.
Also fun: the Response API supports HTML form encoding now in addition to JSON:
curl https://api.openai.com/v1/responses \
-u :$OPENAI_API_KEY \
-d model="gpt-4o" \
-d input="What is the capital of France?"
I found that in an excellent Twitter thread providing background on the design decisions in the new API from OpenAI's Atty Eleti. Here's a nitter link for people who don't have a Twitter account.
New built-in tools
A potentially more exciting change today is the introduction of default tools that you can request while using the new Responses API. There are three of these, all of which can be specified in the "tools": [...] array.
{"type": "web_search_preview"}- the same search feature available through ChatGPT. The documentation doesn't clarify which underlying search engine is used - I initially assumed Bing, but the tool documentation links to this Overview of OpenAI Crawlers page so maybe it's entirely in-house now? Web search is priced at between $25 and $50 per thousand queries depending on if you're using GPT-4o or GPT-4o mini and the configurable size of your "search context".{"type": "file_search", "vector_store_ids": [...]}provides integration with the latest version of their file search vector store, mainly used for RAG. "Usage is priced at $2.50 per thousand queries and file storage at $0.10/GB/day, with the first GB free".{"type": "computer_use_preview", "display_width": 1024, "display_height": 768, "environment": "browser"}is the most surprising to me: it's tool access to the Computer-Using Agent system they built for their Operator product. This one is going to be a lot of fun to explore. The tool's documentation includes a warning about prompt injection risks. Though on closer inspection I think this may work more like Claude Computer Use, where you have to run the sandboxed environment yourself rather than outsource that difficult part to them.
I'm still thinking through how to expose these new features in my LLM tool, which is made harder by the fact that a number of plugins now rely on the default OpenAI implementation from core, which is currently built on top of Chat Completions. I've been worrying for a while about the impact of our entire industry building clones of one proprietary API that might change in the future, I guess now we get to see how that shakes out!
llm-openrouter 0.4. I found out this morning that OpenRouter include support for a number of (rate-limited) free API models.
I occasionally run workshops on top of LLMs (like this one) and being able to provide students with a quick way to obtain an API key against models where they don't have to setup billing is really valuable to me!
This inspired me to upgrade my existing llm-openrouter plugin, and in doing so I closed out a bunch of open feature requests.
Consider this post the annotated release notes:
- LLM schema support for OpenRouter models that support structured output. #23
I'm trying to get support for LLM's new schema feature into as many plugins as possible.
OpenRouter's OpenAI-compatible API includes support for the response_format structured content option, but with an important caveat: it only works for some models, and if you try to use it on others it is silently ignored.
I filed an issue with OpenRouter requesting they include schema support in their machine-readable model index. For the moment LLM will let you specify schemas for unsupported models and will ignore them entirely, which isn't ideal.
llm openrouter keycommand displays information about your current API key. #24
Useful for debugging and checking the details of your key's rate limit.
llm -m ... -o online 1enables web search grounding against any model, powered by Exa. #25
OpenRouter apparently make this feature available to every one of their supported models! They're using new-to-me Exa to power this feature, an AI-focused search engine startup who appear to have built their own index with their own crawlers (according to their FAQ). This feature is currently priced by OpenRouter at $4 per 1000 results, and since 5 results are returned for every prompt that's 2 cents per prompt.
llm openrouter modelscommand for listing details of the OpenRouter models, including a--jsonoption to get JSON and a--freeoption to filter for just the free models. #26
This offers a neat way to list the available models. There are examples of the output in the comments on the issue.
- New option to specify custom provider routing:
-o provider '{JSON here}'. #17
Part of OpenRouter's USP is that it can route prompts to different providers depending on factors like latency, cost or as a fallback if your first choice is unavailable - great for if you are using open weight models like Llama which are hosted by competing companies.
The options they provide for routing are very thorough - I had initially hoped to provide a set of CLI options that covered all of these bases, but I decided instead to reuse their JSON format and forward those options directly on to the model.
A Practical Guide to Implementing DeepSearch / DeepResearch. I really like the definitions Han Xiao from Jina AI proposes for the terms DeepSearch and DeepResearch in this piece:
DeepSearch runs through an iterative loop of searching, reading, and reasoning until it finds the optimal answer. [...]
DeepResearch builds upon DeepSearch by adding a structured framework for generating long research reports.
I've recently found myself cooling a little on the classic RAG pattern of finding relevant documents and dumping them into the context for a single call to an LLM.
I think this definition of DeepSearch helps explain why. RAG is about answering questions that fall outside of the knowledge baked into a model. The DeepSearch pattern offers a tools-based alternative to classic RAG: we give the model extra tools for running multiple searches (which could be vector-based, or FTS, or even systems like ripgrep) and run it for several steps in a loop to try to find an answer.
I think DeepSearch is a lot more interesting than DeepResearch, which feels to me more like a presentation layer thing. Pulling together the results from multiple searches into a "report" looks more impressive, but I still worry that the report format provides a misleading impression of the quality of the "research" that took place.
Introducing Perplexity Deep Research. Perplexity become the third company to release a product with "Deep Research" in the name.
- Google's Gemini Deep Research: Try Deep Research and our new experimental model in Gemini, your AI assistant on December 11th 2024
- OpenAI's ChatGPT Deep Research: Introducing deep research - February 2nd 2025
And now Perplexity Deep Research, announced on February 14th.
The three products all do effectively the same thing: you give them a task, they go out and accumulate information from a large number of different websites and then use long context models and prompting to turn the result into a report. All three of them take several minutes to return a result.
In my AI/LLM predictions post on January 10th I expressed skepticism at the idea of "agents", with the exception of coding and research specialists. I said:
It makes intuitive sense to me that this kind of research assistant can be built on our current generation of LLMs. They’re competent at driving tools, they’re capable of coming up with a relatively obvious research plan (look for newspaper articles and research papers) and they can synthesize sensible answers given the right collection of context gathered through search.
Google are particularly well suited to solving this problem: they have the world’s largest search index and their Gemini model has a 2 million token context. I expect Deep Research to get a whole lot better, and I expect it to attract plenty of competition.
Just over a month later I'm feeling pretty good about that prediction!
llm-gemini 0.9.
This new release of my llm-gemini plugin adds support for two new experimental models:
learnlm-1.5-pro-experimentalis "an experimental task-specific model that has been trained to align with learning science principles when following system instructions for teaching and learning use cases" - more here.-
gemini-2.0-flash-thinking-exp-01-21is a brand new version of the Gemini 2.0 Flash Thinking model released today:Latest version also includes code execution, a 1M token content window & a reduced likelihood of thought-answer contradictions.
The most exciting new feature though is support for Google search grounding, where some Gemini models can execute Google searches as part of answering a prompt. This feature can be enabled using the new -o google_search 1 option.
My AI/LLM predictions for the next 1, 3 and 6 years, for Oxide and Friends
The Oxide and Friends podcast has an annual tradition of asking guests to share their predictions for the next 1, 3 and 6 years. Here’s 2022, 2023 and 2024. This year they invited me to participate. I’ve never been brave enough to share any public predictions before, so this was a great opportunity to get outside my comfort zone!
[... 2,675 words]2024
Google search hallucinates Encanto 2. Jason Schreier on Bluesky:
I was excited to tell my kids that there's a sequel to Encanto, only to scroll down and learn that Google's AI just completely made this up
I just replicated the same result by searching Google for encanto 2. Here's what the "AI overview" at the top of the page looked like:
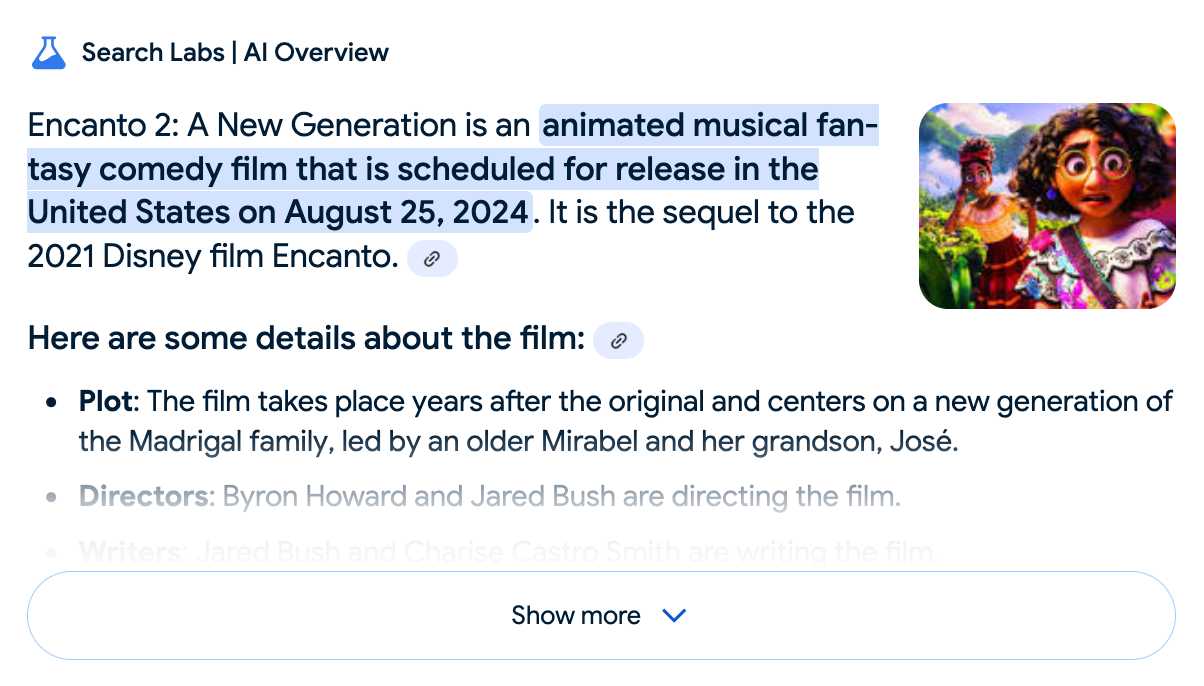
Only when I clicked the "Show more" link did it become clear what had happened:

The link in that first snippet was to the Encanto 2: A New Generation page on Idea Wiki:
This is a fanon wiki, and just like fan-fiction wikis, this one has a variety of fan created ideas on here! These include potential sequels and new series that have yet to exist.
Other cited links included this article about Instagram fan art and Encanto's Sequel Chances Addressed by Disney Director, a very thin article built around a short quote from Encanto's director at D23 Brazil.
And that August 2024 release date (which the AI summary weirdly lists as "scheduled for release" despite that date being five months in the past)? It's from the Idea Wiki imaginary info box for the film.
This is a particularly clear example of how badly wrong AI summarization can go. LLMs are gullible: they believe what you tell them, and the web is full of misleading information - some of which is completely innocent.
Update: I've had some pushback over my use of the term "hallucination" here, on the basis that the LLM itself is doing what it's meant to: summarizing the RAG content that has been provided to it by the host system.
That's fair: this is not a classic LLM hallucination, where the LLM produces incorrect data purely from knowledge partially encoded in its weights.
I classify this as a bug in Google's larger LLM-powered AI overview system. That system should be able to take the existence of invalid data sources into account - given how common searches for non-existent movie sequels (or TV seasons) are, I would hope that AI overviews could classify such searches and take extra steps to avoid serving misleading answers.
So think this is a "hallucination" bug in the AI overview system itself: it's making statements about the world that are not true.
Notes from Bing Chat—Our First Encounter With Manipulative AI

I participated in an Ars Live conversation with Benj Edwards of Ars Technica today, talking about that wild period of LLM history last year when Microsoft launched Bing Chat and it instantly started misbehaving, gaslighting and defaming people.
[... 438 words]If you have worked in search, you know how freaking hard even getting started with something close to this with traditional methods. Now, you can zero-shot it.
System Instructions: As a query categorization expert, you try to break down the intent of a search query. First, provide your reasoning and then describe the intent using a single category (broad, detailed, comparision)
User: The query from the user is "nike versus adidas for terrain running". The user is a female, age 22.Model: The user is clearly looking to compare two specific brands, Nike and Adidas, for a particular activity, terrain running. While the user's demographics might be helpful in some situations (e.g., recommending specific product lines), the core intent remains a comparison. Category: Comparison
There's a lot of hand-waving around query intent classification; it's always been like that. Now, it's straightforward (add a few examples to improve accuracy). But my point is that you could only dream about building something like this without having access to lots of interaction data.
OpenAI: Improve file search result relevance with chunk ranking (via) I've mostly been ignoring OpenAI's Assistants API. It provides an alternative to their standard messages API where you construct "assistants", chatbots with optional access to additional tools and that store full conversation threads on the server so you don't need to pass the previous conversation with every call to their API.
I'm pretty comfortable with their existing API and I found the assistants API to be quite a bit more complicated. So far the only thing I've used it for is a script to scrape OpenAI Code Interpreter to keep track of updates to their enviroment's Python packages.
Code Interpreter aside, the other interesting assistants feature is File Search. You can upload files in a wide variety of formats and OpenAI will chunk them, store the chunks in a vector store and make them available to help answer questions posed to your assistant - it's their version of hosted RAG.
Prior to today OpenAI had kept the details of how this worked undocumented. I found this infuriating, because when I'm building a RAG system the details of how files are chunked and scored for relevance is the whole game - without understanding that I can't make effective decisions about what kind of documents to use and how to build on top of the tool.
This has finally changed! You can now run a "step" (a round of conversation in the chat) and then retrieve details of exactly which chunks of the file were used in the response and how they were scored using the following incantation:
run_step = client.beta.threads.runs.steps.retrieve( thread_id="thread_abc123", run_id="run_abc123", step_id="step_abc123", include=[ "step_details.tool_calls[*].file_search.results[*].content" ] )
(See what I mean about the API being a little obtuse?)
I tried this out today and the results were very promising. Here's a chat transcript with an assistant I created against an old PDF copy of the Datasette documentation - I used the above new API to dump out the full list of snippets used to answer the question "tell me about ways to use spatialite".
It pulled in a lot of content! 57,017 characters by my count, spread across 20 search results (customizable), for a total of 15,021 tokens as measured by ttok. At current GPT-4o-mini prices that would cost 0.225 cents (less than a quarter of a cent), but with regular GPT-4o it would cost 7.5 cents.
OpenAI provide up to 1GB of vector storage for free, then charge $0.10/GB/day for vector storage beyond that. My 173 page PDF seems to have taken up 728KB after being chunked and stored, so that GB should stretch a pretty long way.
Confession: I couldn't be bothered to work through the OpenAI code examples myself, so I hit Ctrl+A on that web page and copied the whole lot into Claude 3.5 Sonnet, then prompted it:
Based on this documentation, write me a Python CLI app (using the Click CLi library) with the following features:
openai-file-chat add-files name-of-vector-store *.pdf *.txt
This creates a new vector store called name-of-vector-store and adds all the files passed to the command to that store.
openai-file-chat name-of-vector-store1 name-of-vector-store2 ...
This starts an interactive chat with the user, where any time they hit enter the question is answered by a chat assistant using the specified vector stores.
We iterated on this a few times to build me a one-off CLI app for trying out the new features. It's got a few bugs that I haven't fixed yet, but it was a very productive way of prototyping against the new API.
Using gpt-4o-mini as a reranker. Tip from David Zhang: "using gpt-4-mini as a reranker gives you better results, and now with strict mode it's just as reliable as any other reranker model".
David's code here demonstrates the Vercel AI SDK for TypeScript, and its support for structured data using Zod schemas.
const res = await generateObject({
model: gpt4MiniModel,
prompt: `Given the list of search results, produce an array of scores measuring the liklihood of the search result containing information that would be useful for a report on the following objective: ${objective}\n\nHere are the search results:\n<results>\n${resultsString}\n</results>`,
system: systemMessage(),
schema: z.object({
scores: z
.object({
reason: z
.string()
.describe(
'Think step by step, describe your reasoning for choosing this score.',
),
id: z.string().describe('The id of the search result.'),
score: z
.enum(['low', 'medium', 'high'])
.describe(
'Score of relevancy of the result, should be low, medium, or high.',
),
})
.array()
.describe(
'An array of scores. Make sure to give a score to all ${results.length} results.',
),
}),
});It's using the trick where you request a reason key prior to the score, in order to implement chain-of-thought - see also Matt Webb's Braggoscope Prompts.
Building search-based RAG using Claude, Datasette and Val Town
Retrieval Augmented Generation (RAG) is a technique for adding extra “knowledge” to systems built on LLMs, allowing them to answer questions against custom information not included in their training data. A common way to implement this is to take a question from a user, translate that into a set of search queries, run those against a search engine and then feed the results back into the LLM to generate an answer.
[... 3,372 words]Val Vibes: Semantic search in Val Town. A neat case-study by JP Posma on how Val Town's developers can use Val Town Vals to build prototypes of new features that later make it into Val Town core.
This one explores building out semantic search against Vals using OpenAI embeddings and the PostgreSQL pgvector extension.
What We Learned from a Year of Building with LLMs (Part I). Accumulated wisdom from six experienced LLM hackers. Lots of useful tips in here. On providing examples in a prompt:
If n is too low, the model may over-anchor on those specific examples, hurting its ability to generalize. As a rule of thumb, aim for n ≥ 5. Don’t be afraid to go as high as a few dozen.
There's a recommendation not to overlook keyword search when implementing RAG - tricks with embeddings can miss results for things like names or acronyms, and keyword search is much easier to debug.
Plus this tip on using the LLM-as-judge pattern for implementing automated evals:
Instead of asking the LLM to score a single output on a Likert scale, present it with two options and ask it to select the better one. This tends to lead to more stable results.
Some goofy results from ‘AI Overviews’ in Google Search. John Gruber collects two of the best examples of Google’s new AI overviews going horribly wrong.
Gullibility is a fundamental trait of all LLMs, and Google’s new feature apparently doesn’t know not to parrot ideas it picked up from articles in the Onion, or jokes from Reddit.
I’ve heard that LLM providers internally talk about “screenshot attacks”—bugs where the biggest risk is that someone will take an embarrassing screenshot.
In Google search’s case this class of bug feels like a significant reputational threat.
But where the company once limited itself to gathering low-hanging fruit along the lines of “what time is the super bowl,” on Tuesday executives showcased generative AI tools that will someday plan an entire anniversary dinner, or cross-country-move, or trip abroad. A quarter-century into its existence, a company that once proudly served as an entry point to a web that it nourished with traffic and advertising revenue has begun to abstract that all away into an input for its large language models.
More than an OpenAI Wrapper: Perplexity Pivots to Open Source. I’m increasingly impressed with Perplexity.ai—I’m using it on a daily basis now. It’s by far the best implementation I’ve seen of LLM-assisted search—beating Microsoft Bing and Google Bard at their own game.
A year ago it was implemented as a GPT 3.5 powered wrapper around Microsoft Bing. To my surprise they’ve now evolved way beyond that: Perplexity has their own search index now and is running their own crawlers, and they’re using variants of Mistral 7B and Llama 70B as their models rather than continuing to depend on OpenAI.
2023
Thoughts and impressions of AI-assisted search from Bing
It’s been a wild couple of weeks.
[... 1,763 words]