Posts tagged anthropic, python
Filters: anthropic × python × Sorted by date
Build AI agents with the Mistral Agents API. Big upgrade to Mistral's API this morning: they've announced a new "Agents API". Mistral have been using the term "agents" for a while now. Here's how they describe them:
AI agents are autonomous systems powered by large language models (LLMs) that, given high-level instructions, can plan, use tools, carry out steps of processing, and take actions to achieve specific goals.
What that actually means is a system prompt plus a bundle of tools running in a loop.
Their new API looks similar to OpenAI's Responses API (March 2025), in that it now manages conversation state server-side for you, allowing you to send new messages to a thread without having to maintain that local conversation history yourself and transfer it every time.
Mistral's announcement captures the essential features that all of the LLM vendors have started to converge on for these "agentic" systems:
- Code execution, using Mistral's new Code Interpreter mechanism. It's Python in a server-side sandbox - OpenAI have had this for years and Anthropic launched theirs last week.
- Image generation - Mistral are using Black Forest Lab FLUX1.1 [pro] Ultra.
- Web search - this is an interesting variant, Mistral offer two versions:
web_searchis classic search, butweb_search_premium"enables access to both a search engine and two news agencies: AFP and AP". Mistral don't mention which underlying search engine they use but Brave is the only search vendor listed in the subprocessors on their Trust Center so I'm assuming it's Brave Search. I wonder if that news agency integration is handled by Brave or Mistral themselves? - Document library is Mistral's version of hosted RAG over "user-uploaded documents". Their documentation doesn't mention if it's vector-based or FTS or which embedding model it uses, which is a disappointing omission.
- Model Context Protocol support: you can now include details of MCP servers in your API calls and Mistral will call them when it needs to. It's pretty amazing to see the same new feature roll out across OpenAI (May 21st), Anthropic (May 22nd) and now Mistral (May 27th) within eight days of each other!
They also implement "agent handoffs":
Once agents are created, define which agents can hand off tasks to others. For example, a finance agent might delegate tasks to a web search agent or a calculator agent based on the conversation's needs.
Handoffs enable a seamless chain of actions. A single request can trigger tasks across multiple agents, each handling specific parts of the request.
This pattern always sounds impressive on paper but I'm yet to be convinced that it's worth using frequently. OpenAI have a similar mechanism in their OpenAI Agents SDK.
llm-anthropic.
I've renamed my llm-claude-3 plugin to llm-anthropic, on the basis that Claude 4 will probably happen at some point so this is a better name for the plugin.
If you're a previous user of llm-claude-3 you can upgrade to the new plugin like this:
llm install -U llm-claude-3
This should remove the old plugin and install the new one, because the latest llm-claude-3 depends on llm-anthropic. Just installing llm-anthropic may leave you with both plugins installed at once.
There is one extra manual step you'll need to take during this upgrade: creating a new anthropic stored key with the same API token you previously stored under claude. You can do that like so:
llm keys set anthropic --value "$(llm keys get claude)"
I released llm-anthropic 0.12 yesterday with new features not previously included in llm-claude-3:
- Support for Claude's prefill feature, using the new
-o prefill '{'option and the accompanying-o hide_prefill 1option to prevent the prefill from being included in the output text. #2- New
-o stop_sequences '```'option for specifying one or more stop sequences. To specify multiple stop sequences pass a JSON array of strings :-o stop_sequences '["end", "stop"].- Model options are now documented in the README.
If you install or upgrade llm-claude-3 you will now get llm-anthropic instead, thanks to a tiny package on PyPI which depends on the new plugin name. I created that with my pypi-rename cookiecutter template.
Here's the issue for the rename. I archived the llm-claude-3 repository on GitHub, and got to use the brand new PyPI archiving feature to archive the llm-claude-3 project on PyPI as well.
Introducing the Model Context Protocol (via) Interesting new initiative from Anthropic. The Model Context Protocol aims to provide a standard interface for LLMs to interact with other applications, allowing applications to expose tools, resources (contant that you might want to dump into your context) and parameterized prompts that can be used by the models.
Their first working version of this involves the Claude Desktop app (for macOS and Windows). You can now configure that app to run additional "servers" - processes that the app runs and then communicates with via JSON-RPC over standard input and standard output.
Each server can present a list of tools, resources and prompts to the model. The model can then make further calls to the server to request information or execute one of those tools.
(For full transparency: I got a preview of this last week, so I've had a few days to try it out.)
The best way to understand this all is to dig into the examples. There are 13 of these in the modelcontextprotocol/servers GitHub repository so far, some using the Typesscript SDK and some with the Python SDK (mcp on PyPI).
My favourite so far, unsurprisingly, is the sqlite one. This implements methods for Claude to execute read and write queries and create tables in a SQLite database file on your local computer.
This is clearly an early release: the process for enabling servers in Claude Desktop - which involves hand-editing a JSON configuration file - is pretty clunky, and currently the desktop app and running extra servers on your own machine is the only way to try this out.
The specification already describes the next step for this: an HTTP SSE protocol which will allow Claude (and any other software that implements the protocol) to communicate with external HTTP servers. Hopefully this means that MCP will come to the Claude web and mobile apps soon as well.
A couple of early preview partners have announced their MCP implementations already:
- Cody supports additional context through Anthropic's Model Context Protocol
- The Context Outside the Code is the Zed editor's announcement of their MCP extensions.
llm-gemini 0.4.
New release of my llm-gemini plugin, adding support for asynchronous models (see LLM 0.18), plus the new gemini-exp-1114 model (currently at the top of the Chatbot Arena) and a -o json_object 1 option to force JSON output.
I also released llm-claude-3 0.9 which adds asynchronous support for the Claude family of models.
Anthropic’s Prompt Engineering Interactive Tutorial (via) Anthropic continue their trend of offering the best documentation of any of the leading LLM vendors. This tutorial is delivered as a set of Jupyter notebooks - I used it as an excuse to try uvx like this:
git clone https://github.com/anthropics/courses
uvx --from jupyter-core jupyter notebook coursesThis installed a working Jupyter system, started the server and launched my browser within a few seconds.
The first few chapters are pretty basic, demonstrating simple prompts run through the Anthropic API. I used %pip install anthropic instead of !pip install anthropic to make sure the package was installed in the correct virtual environment, then filed an issue and a PR.
One new-to-me trick: in the first chapter the tutorial suggests running this:
API_KEY = "your_api_key_here" %store API_KEY
This stashes your Anthropic API key in the IPython store. In subsequent notebooks you can restore the API_KEY variable like this:
%store -r API_KEY
I poked around and on macOS those variables are stored in files of the same name in ~/.ipython/profile_default/db/autorestore.
Chapter 4: Separating Data and Instructions included some interesting notes on Claude's support for content wrapped in XML-tag-style delimiters:
Note: While Claude can recognize and work with a wide range of separators and delimeters, we recommend that you use specifically XML tags as separators for Claude, as Claude was trained specifically to recognize XML tags as a prompt organizing mechanism. Outside of function calling, there are no special sauce XML tags that Claude has been trained on that you should use to maximally boost your performance. We have purposefully made Claude very malleable and customizable this way.
Plus this note on the importance of avoiding typos, with a nod back to the problem of sandbagging where models match their intelligence and tone to that of their prompts:
This is an important lesson about prompting: small details matter! It's always worth it to scrub your prompts for typos and grammatical errors. Claude is sensitive to patterns (in its early years, before finetuning, it was a raw text-prediction tool), and it's more likely to make mistakes when you make mistakes, smarter when you sound smart, sillier when you sound silly, and so on.
Chapter 5: Formatting Output and Speaking for Claude includes notes on one of Claude's most interesting features: prefill, where you can tell it how to start its response:
client.messages.create( model="claude-3-haiku-20240307", max_tokens=100, messages=[ {"role": "user", "content": "JSON facts about cats"}, {"role": "assistant", "content": "{"} ] )
Things start to get really interesting in Chapter 6: Precognition (Thinking Step by Step), which suggests using XML tags to help the model consider different arguments prior to generating a final answer:
Is this review sentiment positive or negative? First, write the best arguments for each side in <positive-argument> and <negative-argument> XML tags, then answer.
The tags make it easy to strip out the "thinking out loud" portions of the response.
It also warns about Claude's sensitivity to ordering. If you give Claude two options (e.g. for sentiment analysis):
In most situations (but not all, confusingly enough), Claude is more likely to choose the second of two options, possibly because in its training data from the web, second options were more likely to be correct.
This effect can be reduced using the thinking out loud / brainstorming prompting techniques.
A related tip is proposed in Chapter 8: Avoiding Hallucinations:
How do we fix this? Well, a great way to reduce hallucinations on long documents is to make Claude gather evidence first.
In this case, we tell Claude to first extract relevant quotes, then base its answer on those quotes. Telling Claude to do so here makes it correctly notice that the quote does not answer the question.
I really like the example prompt they provide here, for answering complex questions against a long document:
<question>What was Matterport's subscriber base on the precise date of May 31, 2020?</question>
Please read the below document. Then, in <scratchpad> tags, pull the most relevant quote from the document and consider whether it answers the user's question or whether it lacks sufficient detail. Then write a brief numerical answer in <answer> tags.
django-http-debug, a new Django app mostly written by Claude
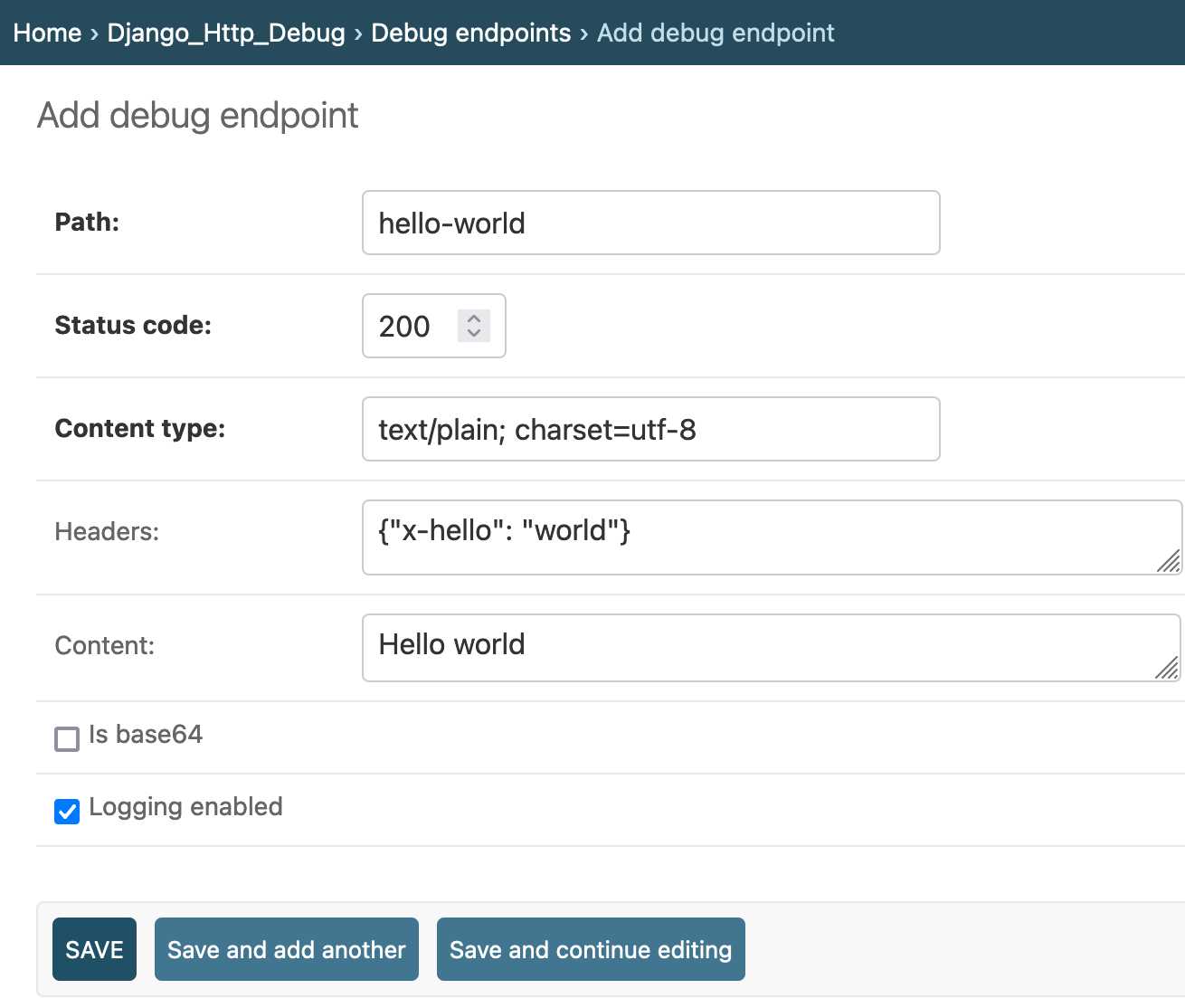
Yesterday I finally developed something I’ve been casually thinking about building for a long time: django-http-debug. It’s a reusable Django app—something you can pip install into any Django project—which provides tools for quickly setting up a URL that returns a canned HTTP response and logs the full details of any incoming request to a database table.
mistralai/mistral-common. New from Mistral: mistral-common, an open source Python library providing "a set of tools to help you work with Mistral models".
So far that means a tokenizer! This is similar to OpenAI's tiktoken library in that it lets you run tokenization in your own code, which crucially means you can count the number of tokens that you are about to use - useful for cost estimates but also for cramming the maximum allowed tokens in the context window for things like RAG.
Mistral's library is better than tiktoken though, in that it also includes logic for correctly calculating the tokens needed for conversation construction and tool definition. With OpenAI's APIs you're currently left guessing how many tokens are taken up by these advanced features.
Anthropic haven't published any form of tokenizer at all - it's the feature I'd most like to see from them next.
Here's how to explore the vocabulary of the tokenizer:
MistralTokenizer.from_model(
"open-mixtral-8x22b"
).instruct_tokenizer.tokenizer.vocab()[:12]
['<unk>', '<s>', '</s>', '[INST]', '[/INST]', '[TOOL_CALLS]', '[AVAILABLE_TOOLS]', '[/AVAILABLE_TOOLS]', '[TOOL_RESULTS]', '[/TOOL_RESULTS]']
llm-claude-3. I built a new plugin for LLM—my command-line tool and Python library for interacting with Large Language Models—which adds support for the new Claude 3 models from Anthropic.
Catching up on the weird world of LLMs

I gave a talk on Sunday at North Bay Python where I attempted to summarize the last few years of development in the space of LLMs—Large Language Models, the technology behind tools like ChatGPT, Google Bard and Llama 2.
[... 10,489 words]