December 2018
20 posts: 1 entry, 11 links, 5 quotes, 3 beats
Dec. 2, 2018
Software Sprawl, The Golden Path, and Scaling Teams With Agency (via) This is smart: the "golden path" approach to encouraging a standard stack within a large engineering organization. If you build using the components on the golden path you get guaranteed ongoing support and as much free monitoring/tooling as can possibly be provided. I also really like the suggestion that this should be managed by a "council" of senior engineers with one member of the council rotated out every quarter to keep things from getting stale and cabal-like.
Charity Majors describes the process like this:
- Assemble a small council of trusted senior engineers.
- Task them with creating a recommended list of default components for developers to use when building out new services. This will be your Golden Path, the path of convergence (and the path of least resistance).
- Tell all your engineers that going forward, the Golden Path will be fully supported by the org. Upgrades, patches, security fixes; backups, monitoring, build pipeline; deploy tooling, artifact versioning, development environment, even tier 1 on call support. Pave the path with gold. Nobody HAS to use these components ... but if they don't, they're on their own. They will have to support it themselves. [...]
The nature of NPM is such that I'd expect most large corporate Node software to depend on at least a couple of single individuals' hobby projects. The problem is that those projects don't tend to fulfill the same expectations of security, quality and maintenance.
Dec. 3, 2018
How Does React Tell a Class from a Function? (via) Understanding the answer requires a deep understanding of the history of the JavaScript class system plus how Babel and other tools work with it.
Dan Abramov:
For an API to be simple to use, you often need to consider the language semantics (possibly, for several languages, including future directions), runtime performance, ergonomics with and without compile-time steps, the state of the ecosystem and packaging solutions, early warnings, and many other things. The end result might not always be the most elegant, but it must be practical.
Dec. 4, 2018
npm users have downloaded more than 489 billion packages in the 9 year life of the project, with the strange effect of exponential growth being that 286 billion, or 58% of those, were just in the last year.

Dec. 11, 2018
Things About Real-World Data Science Not Discussed In MOOCs and Thought Pieces (via) Really good article, pointing out that carefully optimizing machine learning models is only a small part of the day-to-day work of a data scientist: cleaning up data, building dashboards, shipping models to production, deciding on trade-offs between performance and production and considering the product design and ethical implementations of what you are doing make up a much larger portion of the job.
Dec. 12, 2018
The _repr_html_ method in Jupyter notebooks (via) Today I learned that if you add a _repr_html_ method returning a string of HTML to any Python class Jupyter notebooks will render that HTML inline to represent that object.
nip.io.
"NIP.IO maps <anything>.<IP Address>.nip.io to the corresponding <IP Address>, even 127.0.0.1.nip.io maps to 127.0.0.1" - looks useful. xip.io is a different service that does the same thing. Being able to put anything at the start looks handy for testing systems that handle different subdomains.
Dec. 15, 2018
for those open source companies that still harbor magical beliefs, let me put this to you as directly as possible: cloud services providers are emphatically not going to license your proprietary software. I mean, you knew that, right? The whole premise with your proprietary license is that you are finding that there is no way to compete with the operational dominance of the cloud services providers; did you really believe that those same dominant cloud services providers can’t simply reimplement your LDAP integration or whatever? The cloud services providers are currently reproprietarizing all of computing — they are making their own CPUs for crying out loud! — reimplementing the bits of your software that they need in the name of the service that their customers want (and will pay for!) won’t even move the needle in terms of their effort.
Dec. 16, 2018
Dec. 17, 2018
Pampy: Pattern Matching for Python (via) Ingenious implementation of Erlang/Rust style pattern matching in just 150 lines of extremely cleanly designed and well-tested Python.
PEP 8016 -- The Steering Council Model (via) The votes are in and Python has a new governance model, partly inspired by the model used by the Django Software Foundation. A core elected council of five people (with a maximum of two employees from any individual company) will oversee the project.
Dec. 18, 2018
Develop Your Naturalist Superpowers with Observable Notebooks and iNaturalist (via) Natalie’s article for this year’s 24 ways advent calendar shows how you can use Observable notebooks to quickly build interactive visualizations against web APIs. She uses the iNaturalist API to show species of Nudibranchs that you might see in a given month, plus a Vega-powered graph of sightings over the course of the year. This really inspired me to think harder about how I can use Observable to solve some of my API debugging needs, and I’ve already spun up a couple of private Notebooks to exercise new APIs that I’m building at work. It’s a huge productivity boost.
Dec. 19, 2018
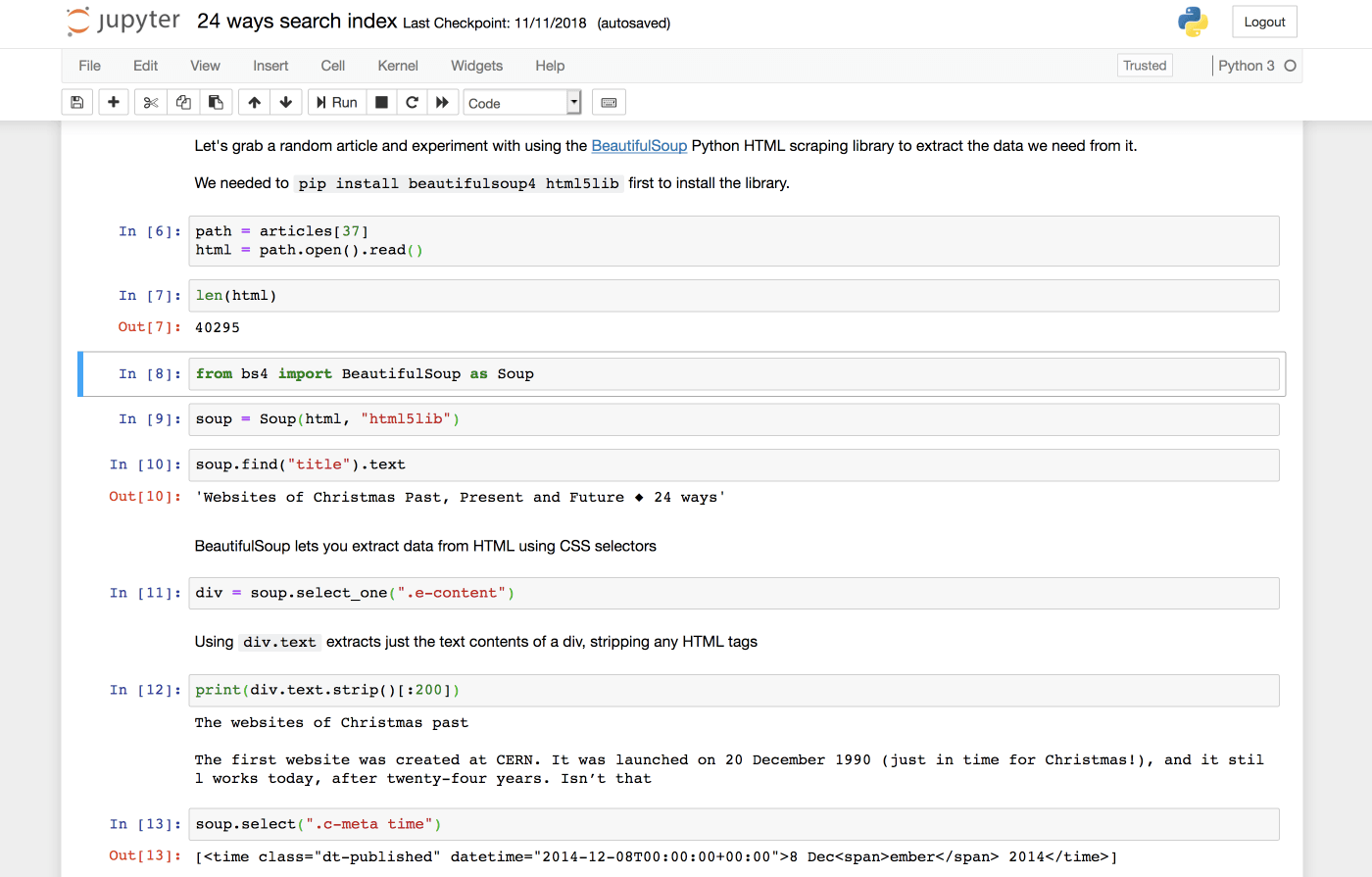
Fast Autocomplete Search for Your Website (via) I wrote a tutorial for the 24 ways advent calendar on building fast autocomplete search for a website on top of Datasette and SQLite. I built the demo against 24 ways itself—I used wget to recursively fetch all 330 articles as HTML, then wrote code in a Jupyter notebook to extract the raw data from them (with BeautifulSoup) and load them into SQLite using my sqlite-utils Python library. I deployed the resulting database using Datasette, then wrote some vanilla JavaScript to implement autocomplete using fast SQL queries against the Datasette JSON API.
Fast Autocomplete Search for Your Website
Every website deserves a great search engine—but building a search engine can be a lot of work, and hosting it can quickly get expensive.
[... 4,159 words]If you wrap your main content – that is, the stuff that isn’t navigation, logo and main header etc – in a
tag, a screen reader user can jump immediately to it using a keyboard shortcut. Imagine how useful that is – they don’t have to listen to all the content before it, or tab through it to get to the main meat of your page.
Dec. 26, 2018
Without deep understanding of the basic tools needed to build and train new algorithms, he says, researchers creating AIs resort to hearsay, like medieval alchemists. "People gravitate around cargo-cult practices," relying on "folklore and magic spells," adds François Chollet, a computer scientist at Google in Mountain View, California.
Dec. 29, 2018
benfred/py-spy (via) A Python port of Julia Evans’ rbspy profiler, which she describes as “probably better” than the original. I just tried it out and it’s really impressive: it’s written in Rust but has precompiled binaries so you can just run “pip install py-spy” to install it. Shows live output in the terminal while your program is running and also includes the option to generate neat SVG flame graphs.
Dec. 31, 2018
The Friendship That Made Google Huge. The New Yorker profiles Jeff Dean and Sanjay Ghemawat, Google’s first and only level 11 Senior Fellows. This is some of the best writing on complex software engineering topics (map-reduce, Tensor Flow and the like) aimed at a general audience that I’ve ever seen. Also a very compelling case study in pair programming.