20 posts tagged “long-context”
Tracking how LLMs are getting better at accepting large amounts of input.
2026
1M context is now generally available for Opus 4.6 and Sonnet 4.6. Here's what surprised me:
Standard pricing now applies across the full 1M window for both models, with no long-context premium.
OpenAI and Gemini both charge more for prompts where the token count goes above a certain point - 200,000 for Gemini 3.1 Pro and 272,000 for GPT-5.4.
2025
Claude Sonnet 4 now supports 1M tokens of context (via) Gemini and OpenAI both have million token models, so it's good to see Anthropic catching up. This is 5x the previous 200,000 context length limit of the various Claude Sonnet models.
Anthropic have previously made 1 million tokens available to select customers. From the Claude 3 announcement in March 2024:
The Claude 3 family of models will initially offer a 200K context window upon launch. However, all three models are capable of accepting inputs exceeding 1 million tokens and we may make this available to select customers who need enhanced processing power.
This is also the first time I've seen Anthropic use prices that vary depending on context length:
- Prompts ≤ 200K: $3/million input, $15/million output
- Prompts > 200K: $6/million input, $22.50/million output
Gemini have been doing this for a while: Gemini 2.5 Pro is $1.25/$10 below 200,000 tokens and $2.50/$15 above 200,000.
Here's Anthropic's full documentation on the 1m token context window. You need to send a context-1m-2025-08-07 beta header in your request to enable it.
Note that this is currently restricted to "tier 4" users who have purchased at least $400 in API credits:
Long context support for Sonnet 4 is now in public beta on the Anthropic API for customers with Tier 4 and custom rate limits, with broader availability rolling out over the coming weeks.
AbsenceBench: Language Models Can’t Tell What’s Missing (via) Here's another interesting result to file under the "jagged frontier" of LLMs, where their strengths and weaknesses are often unintuitive.
Long context models have been getting increasingly good at passing "Needle in a Haystack" tests recently, but what about a problem in the opposite direction?
This paper explores what happens when you give a model some content and then a copy with a portion removed, then ask what changed.
Here's a truncated table of results from the paper:
| Models | Poetry | Sequences | GitHub PRs | Average |
|---|---|---|---|---|
| Gemini-2.5-flash`*` | 87.3 | 95.4 | 30.9 | 71.2 |
| Claude-3.7-Sonnet`*` | 72.7 | 96.0 | 40.0 | 69.6 |
| Claude-3.7-Sonnet | 73.5 | 91.4 | 35.7 | 66.9 |
| Gemini-2.5-flash | 79.3 | 85.2 | 26.2 | 63.6 |
| o3-mini`*` | 65.0 | 78.1 | 38.9 | 60.7 |
| GPT-4.1 | 54.3 | 57.5 | 36.2 | 49.3 |
| ... | ... | ... | ... | ... |
| DeepSeek-R1`*` | 38.7 | 29.5 | 23.1 | 30.4 |
| Qwen3-235B`*` | 26.1 | 18.5 | 24.6 | 23.1 |
| Mixtral-8x7B-Instruct | 4.9 | 21.9 | 17.3 | 14.7 |
* indicates a reasoning model. Sequences are lists of numbers like 117,121,125,129,133,137, Poetry consists of 100-1000 line portions from the Gutenberg Poetry Corpus and PRs are diffs with 10 to 200 updated lines.
The strongest models do well at numeric sequences, adequately at the poetry challenge and really poorly with those PR diffs. Reasoning models do slightly better at the cost of burning through a lot of reasoning tokens - often more than the length of the original document.
The paper authors - Harvey Yiyun Fu and Aryan Shrivastava and Jared Moore and Peter West and Chenhao Tan and Ari Holtzman - have a hypothesis as to what's going on here:
We propose an initial hypothesis explaining this behavior: identifying presence is simpler than absence with the attention mechanisms underlying Transformers (Vaswani et al., 2017). Information included in a document can be directly attended to, while the absence of information cannot.
They poison their own context. Maybe you can call it context rot, where as context grows and especially if it grows with lots of distractions and dead ends, the output quality falls off rapidly. Even with good context the rot will start to become apparent around 100k tokens (with Gemini 2.5).
They really need to figure out a way to delete or "forget" prior context, so the user or even the model can go back and prune poisonous tokens.
Right now I work around it by regularly making summaries of instances, and then spinning up a new instance with fresh context and feed in the summary of the previous instance.
— Workaccount2 on Hacker News, coining "context rot"
Building software on top of Large Language Models

I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
[... 3,726 words]llm-fragments-github 0.2.
I upgraded my llm-fragments-github plugin to add a new fragment type called issue. It lets you pull the entire content of a GitHub issue thread into your prompt as a concatenated Markdown file.
(If you haven't seen fragments before I introduced them in Long context support in LLM 0.24 using fragments and template plugins.)
I used it just now to have Gemini 2.5 Pro provide feedback and attempt an implementation of a complex issue against my LLM project:
llm install llm-fragments-github
llm -f github:simonw/llm \
-f issue:simonw/llm/938 \
-m gemini-2.5-pro-exp-03-25 \
--system 'muse on this issue, then propose a whole bunch of code to help implement it'
Here I'm loading the FULL content of the simonw/llm repo using that -f github:simonw/llm fragment (documented here), then loading all of the comments from issue 938 where I discuss quite a complex potential refactoring. I ask Gemini 2.5 Pro to "muse on this issue" and come up with some code.
This worked shockingly well. Here's the full response, which highlighted a few things I hadn't considered yet (such as the need to migrate old database records to the new tree hierarchy) and then spat out a whole bunch of code which looks like a solid start to the actual implementation work I need to do.
I ran this against Google's free Gemini 2.5 Preview, but if I'd used the paid model it would have cost me 202,680 input tokens, 10,460 output tokens and 1,859 thinking tokens for a total of 62.989 cents.
As a fun extra, the new issue: feature itself was written almost entirely by OpenAI o3, again using fragments. I ran this:
llm -m openai/o3 \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
Here I'm using the ability to pass a URL to -f and giving it the full source of my llm_hacker_news.py plugin (which shows how a fragment can load data from an API) plus the HTML source of my github-issue-to-markdown tool (which I wrote a few months ago with Claude). I effectively asked o3 to take that HTML/JavaScript tool and port it to Python to work with my fragments plugin mechanism.
o3 provided almost the exact implementation I needed, and even included support for a GITHUB_TOKEN environment variable without me thinking to ask for it. Total cost: 19.928 cents.
On a final note of curiosity I tried running this prompt against Gemma 3 27B QAT running on my Mac via MLX and llm-mlx:
llm install llm-mlx llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit llm -m mlx-community/gemma-3-27b-it-qat-4bit \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
That worked pretty well too. It turns out a 16GB local model file is powerful enough to write me an LLM plugin now!
Maybe Meta’s Llama claims to be open source because of the EU AI act

I encountered a theory a while ago that one of the reasons Meta insist on using the term “open source” for their Llama models despite the Llama license not actually conforming to the terms of the Open Source Definition is that the EU’s AI act includes special rules for open source models without requiring OSI compliance.
[... 852 words]GPT-4.1: Three new million token input models from OpenAI, including their cheapest model yet

OpenAI introduced three new models this morning: GPT-4.1, GPT-4.1 mini and GPT-4.1 nano. These are API-only models right now, not available through the ChatGPT interface (though you can try them out in OpenAI’s API playground). All three models can handle 1,047,576 tokens of input and 32,768 tokens of output, and all three have a May 31, 2024 cut-off date (their previous models were mostly September 2023).
[... 1,124 words]Long context support in LLM 0.24 using fragments and template plugins
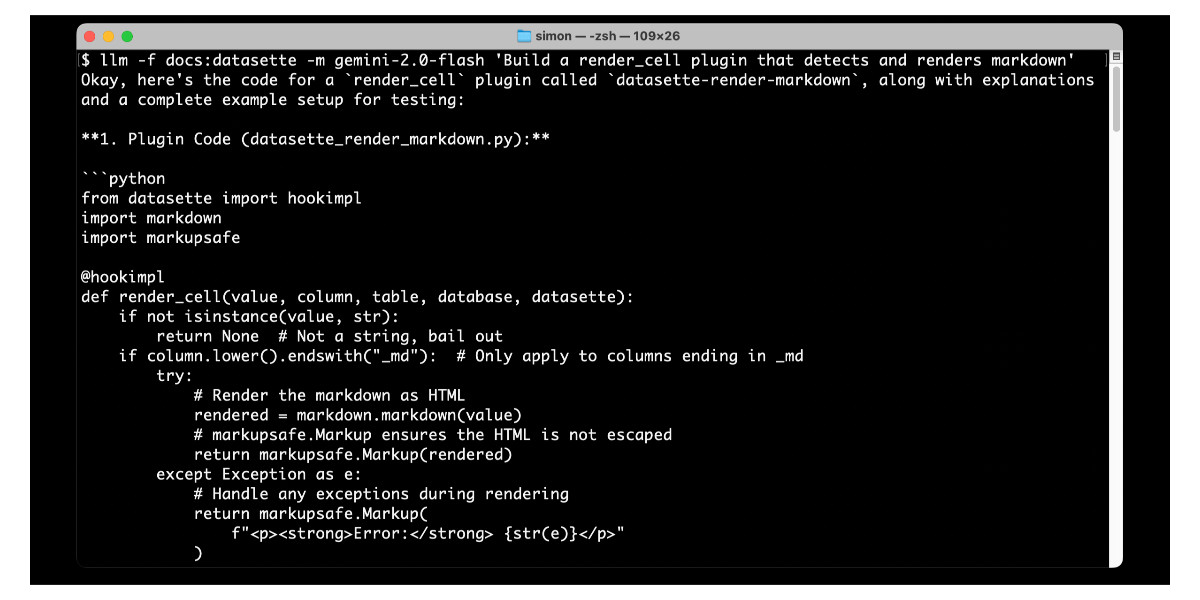
LLM 0.24 is now available with new features to help take advantage of the increasingly long input context supported by modern LLMs.
[... 1,896 words]Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]In my experience with AI coding, very large context windows aren't useful in practice. Every model seems to get confused when you feed them more than ~25-30k tokens. The models stop obeying their system prompts, can't correctly find/transcribe pieces of code in the context, etc.
Developing aider, I've seen this problem with gpt-4o, Sonnet, DeepSeek, etc. Many aider users report this too. It's perhaps the #1 problem users have, so I created a dedicated help page.
Very large context may be useful for certain tasks with lots of "low value" context. But for coding, it seems to lure users into a problematic regime.
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra
2024
Things we learned about LLMs in 2024
A lot has happened in the world of Large Language Models over the course of 2024. Here’s a review of things we figured out about the field in the past twelve months, plus my attempt at identifying key themes and pivotal moments.
[... 7,490 words]When we started working on what became NotebookLM in the summer of 2022, we could fit about 1,500 words in the context window. Now we can fit up to 1.5 million words. (And using various other tricks, effectively fit 25 million words.) The emergence of long context models is, I believe, the single most unappreciated AI development of the past two years, at least among the general public. It radically transforms the utility of these models in terms of actual, practical applications.
Long context prompting tips (via) Interesting tips here from Anthropic's documentation about how to best prompt Claude to work with longer documents.
Put longform data at the top: Place your long documents and inputs (~20K+ tokens) near the top of your prompt, above your query, instructions, and examples. This can significantly improve Claude’s performance across all models. Queries at the end can improve response quality by up to 30% in tests, especially with complex, multi-document inputs.
It recommends using not-quite-valid-XML to add those documents to those prompts, and using a prompt that asks Claude to extract direct quotes before replying to help it focus its attention on the most relevant information:
Find quotes from the patient records and appointment history that are relevant to diagnosing the patient's reported symptoms. Place these in <quotes> tags. Then, based on these quotes, list all information that would help the doctor diagnose the patient's symptoms. Place your diagnostic information in <info> tags.
Context caching for Google Gemini (via) Another new Gemini feature announced today. Long context models enable answering questions against large chunks of text, but the price of those long prompts can be prohibitive - $3.50/million for Gemini Pro 1.5 up to 128,000 tokens and $7/million beyond that.
Context caching offers a price optimization, where the long prefix prompt can be reused between requests, halving the cost per prompt but at an additional cost of $4.50 / 1 million tokens per hour to keep that context cache warm.
Given that hourly extra charge this isn't a default optimization for all cases, but certain high traffic applications might be able to save quite a bit on their longer prompt systems.
It will be interesting to see if other vendors such as OpenAI and Anthropic offer a similar optimization in the future.
Update 14th August 2024: Anthropic's Claude now has its own version of prompt caching.
llm-gemini 0.1a1. I upgraded my llm-gemini plugin to add support for the new Google Gemini Pro 1.5 model, which is beginning to roll out in early access.
The 1.5 model supports 1,048,576 input tokens and generates up to 8,192 output tokens—a big step up from Gemini 1.0 Pro which handled 30,720 and 2,048 respectively.
The big missing feature from my LLM tool at the moment is image input—a fantastic way to take advantage of that huge context window. I have a branch for this which I really need to get into a useful state.
The killer app of Gemini Pro 1.5 is video
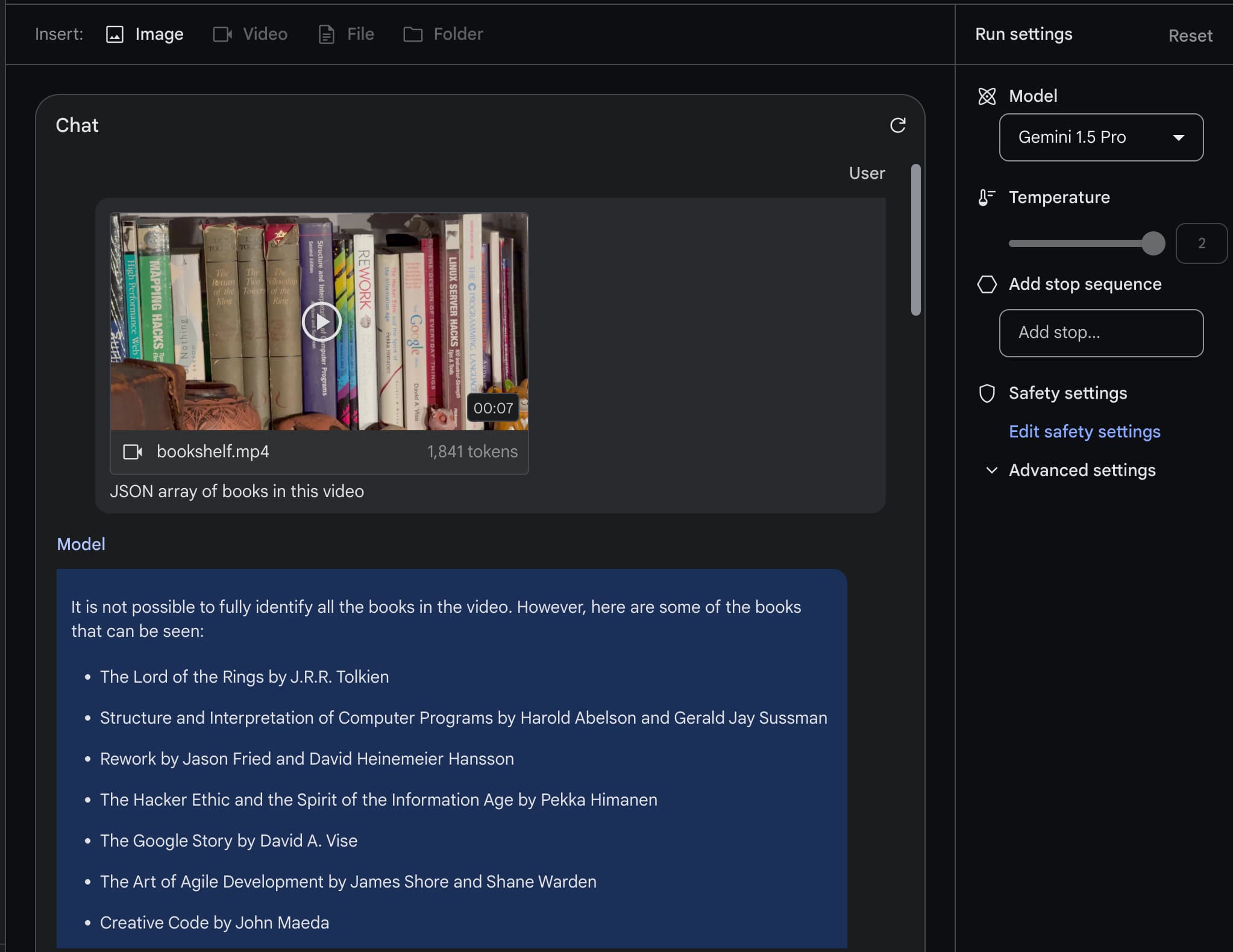
Last week Google introduced Gemini Pro 1.5, an enormous upgrade to their Gemini series of AI models.
[... 2,839 words]Our next-generation model: Gemini 1.5 (via) The big news here is about context length: Gemini 1.5 (a Mixture-of-Experts model) will do 128,000 tokens in general release, available in limited preview with a 1 million token context and has shown promising research results with 10 million tokens!
1 million tokens is 700,000 words or around 7 novels—also described in the blog post as an hour of video or 11 hours of audio.
2023
Long context prompting for Claude 2.1. Claude 2.1 has a 200,000 token context, enough for around 500 pages of text. Convincing it to answer a question based on a single sentence buried deep within that content can be difficult, but Anthropic found that adding “Assistant: Here is the most relevant sentence in the context:” to the end of the prompt was enough to raise Claude 2.1’s score from 27% to 98% on their evaluation.