16 posts tagged “internet-archive”
2026
What I had not realized is that extremely short exposures to a relatively simple computer program could induce powerful delusional thinking in quite normal people.
— Joseph Weizenbaum, creator of ELIZA, in 1976 (via)
Spotlighting The World Factbook as We Bid a Fond Farewell (via) Somewhat devastating news today from CIA:
One of CIA’s oldest and most recognizable intelligence publications, The World Factbook, has sunset.
There's not even a hint as to why they decided to stop maintaining this publication, which has been their most useful public-facing initiative since 1971 and a cornerstone of the public internet since 1997.
In a bizarre act of cultural vandalism they've not just removed the entire site (including the archives of previous versions) but they've also set every single page to be a 302 redirect to their closure announcement.
The Factbook has been released into the public domain since the start. There's no reason not to continue to serve archived versions - a banner at the top of the page saying it's no longer maintained would be much better than removing all of that valuable content entirely.
Up until 2020 the CIA published annual zip file archives of the entire site. Those are available (along with the rest of the Factbook) on the Internet Archive.
I downloaded the 384MB .zip file for the year 2020 and extracted it into a new GitHub repository, simonw/cia-world-factbook-2020. I've enabled GitHub Pages for that repository so you can browse the archived copy at simonw.github.io/cia-world-factbook-2020/.
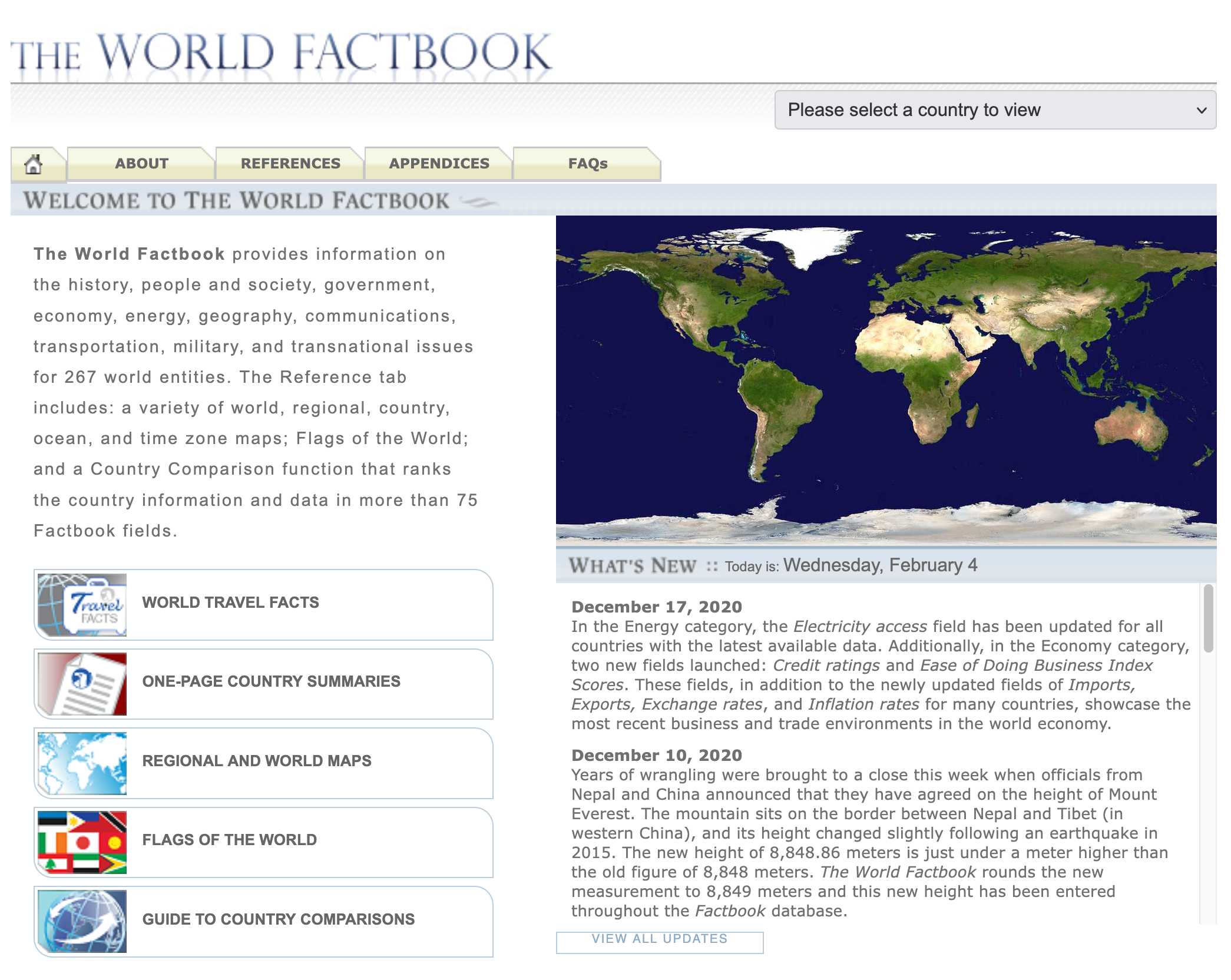
Here's a neat example of the editorial voice of the Factbook from the What's New page, dated December 10th 2020:
Years of wrangling were brought to a close this week when officials from Nepal and China announced that they have agreed on the height of Mount Everest. The mountain sits on the border between Nepal and Tibet (in western China), and its height changed slightly following an earthquake in 2015. The new height of 8,848.86 meters is just under a meter higher than the old figure of 8,848 meters. The World Factbook rounds the new measurement to 8,849 meters and this new height has been entered throughout the Factbook database.
2025
Reddit will block the Internet Archive. Well this sucks. Jay Peters for the Verge:
Reddit says that it has caught AI companies scraping its data from the Internet Archive’s Wayback Machine, so it’s going to start blocking the Internet Archive from indexing the vast majority of Reddit. The Wayback Machine will no longer be able to crawl post detail pages, comments, or profiles; instead, it will only be able to index the Reddit.com homepage, which effectively means Internet Archive will only be able to archive insights into which news headlines and posts were most popular on a given day.
2024
TextSynth Server (via) I'd missed this: Fabrice Bellard (yes, that Fabrice Bellard) has a project called TextSynth Server which he describes like this:
ts_server is a web server proposing a REST API to large language models. They can be used for example for text completion, question answering, classification, chat, translation, image generation, ...
It has the following characteristics:
- All is included in a single binary. Very few external dependencies (Python is not needed) so installation is easy.
- Supports many Transformer variants (GPT-J, GPT-NeoX, GPT-Neo, OPT, Fairseq GPT, M2M100, CodeGen, GPT2, T5, RWKV, LLAMA, Falcon, MPT, Llama 3.2, Mistral, Mixtral, Qwen2, Phi3, Whisper) and Stable Diffusion.
- [...]
Unlike many of his other notable projects (such as FFmpeg, QEMU, QuickJS) this isn't open source - in fact it's not even source available, you instead can download compiled binaries for Linux or Windows that are available for non-commercial use only.
Commercial terms are available, or you can visit textsynth.com and pre-pay for API credits which can then be used with the hosted REST API there.
This is not a new project: the earliest evidence I could find of it was this July 2019 page in the Internet Archive, which said:
Text Synth is build using the GPT-2 language model released by OpenAI. [...] This implementation is original because instead of using a GPU, it runs using only 4 cores of a Xeon E5-2640 v3 CPU at 2.60GHz. With a single user, it generates 40 words per second. It is programmed in plain C using the LibNC library.
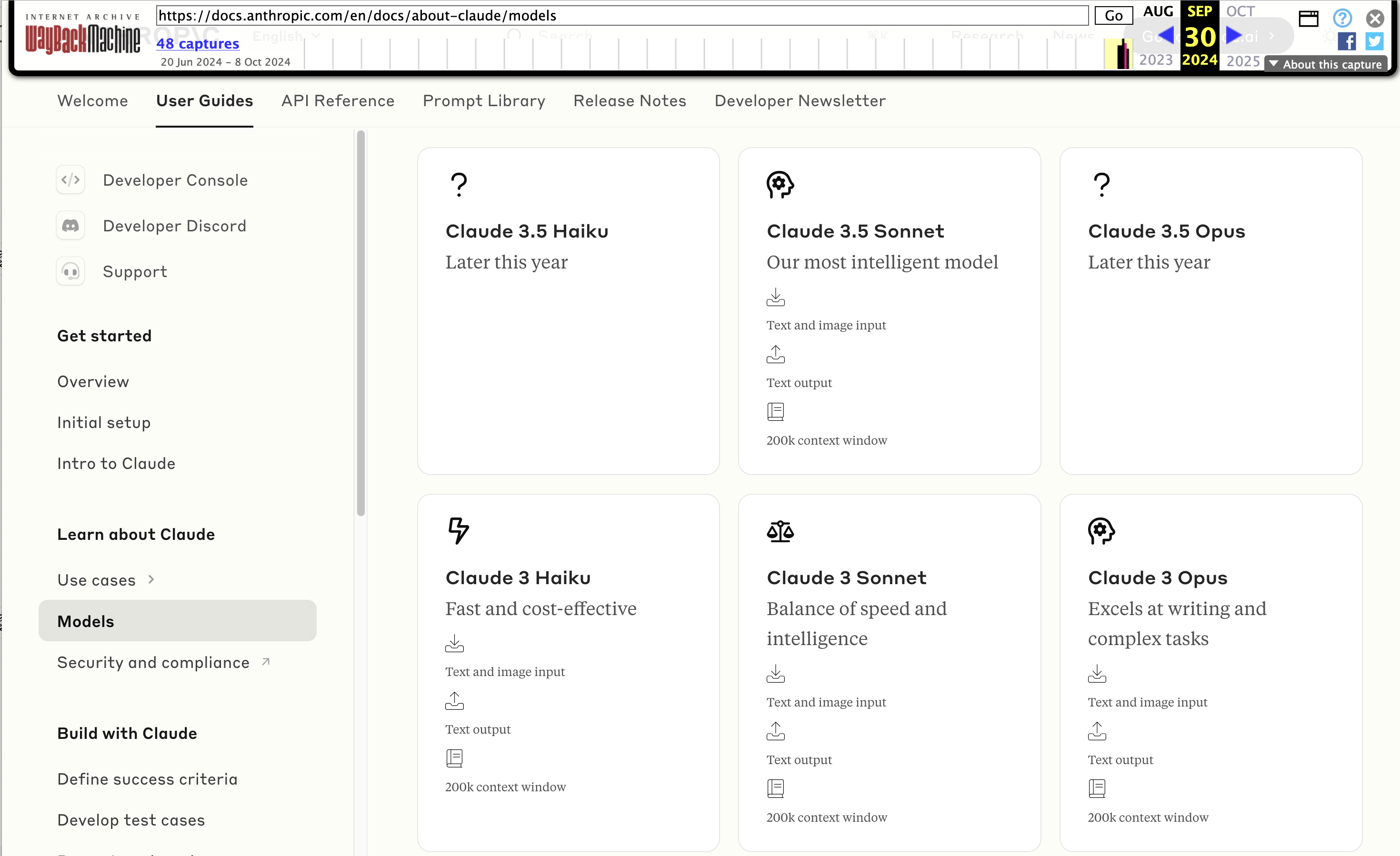
Wayback Machine: Models—Anthropic (8th October 2024). The Internet Archive is only intermittently available at the moment, but the Wayback Machine just came back long enough for me to confirm that the Anthropic Models documentation page listed Claude 3.5 Opus as coming “Later this year” at least as recently as the 8th of October, but today makes no mention of that model at all.
October 8th 2024
October 22nd 2024
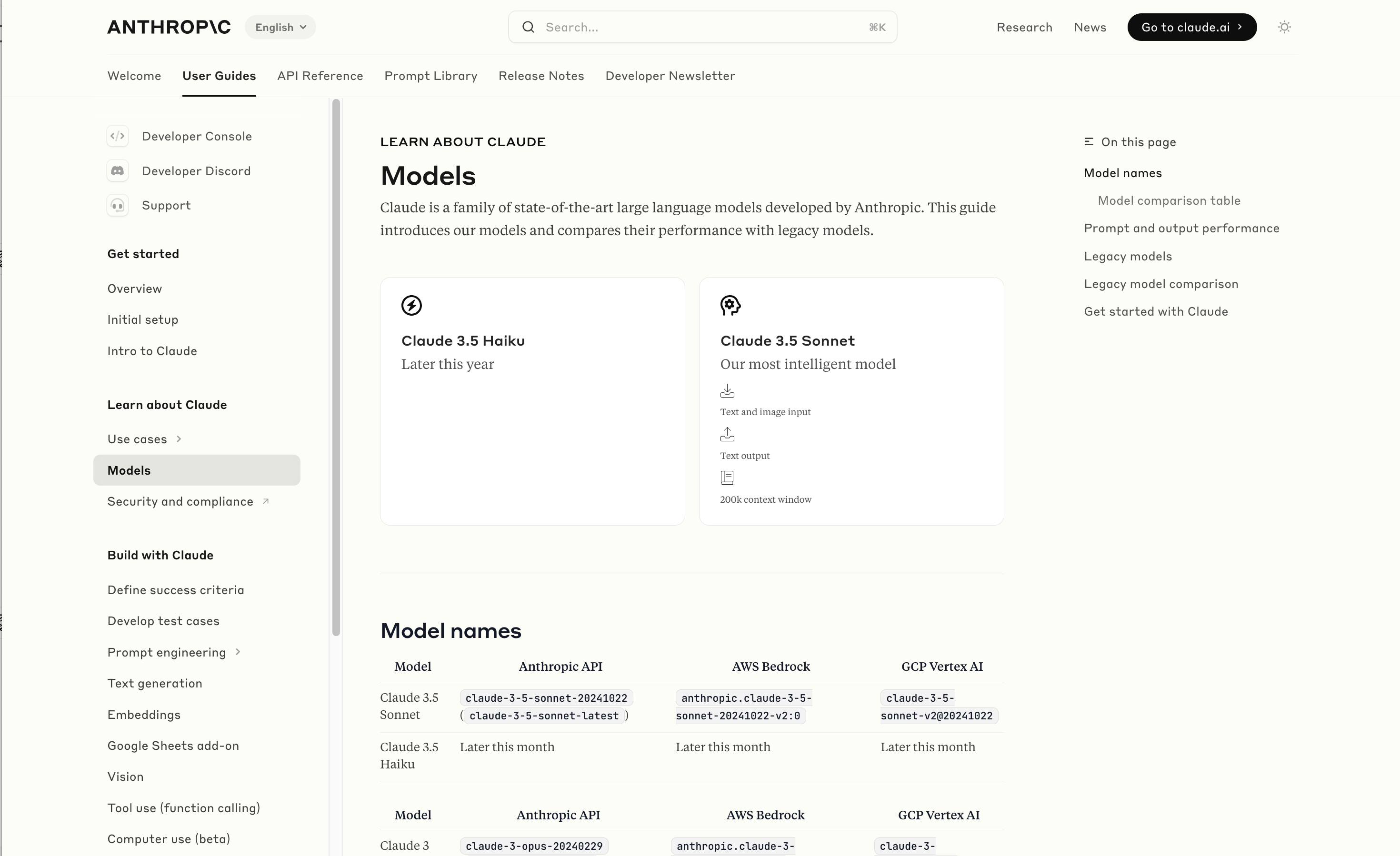
Claude 3 came in three flavors: Haiku (fast and cheap), Sonnet (mid-range) and Opus (best). We were expecting 3.5 to have the same three levels, and both 3.5 Haiku and 3.5 Sonnet fitted those expectations, matching their prices to the Claude 3 equivalents.
It looks like 3.5 Opus may have been entirely cancelled, or at least delayed for an unpredictable amount of time. I guess that means the new 3.5 Sonnet will be Anthropic's best overall model for a while, maybe until Claude 4.
Today’s research challenge: why is August 1st “World Wide Web Day”? Here's a fun mystery. A bunch of publications will tell you that today, August 1st, is "World Wide Web Day"... but where did that idea come from?
It's not an official day marked by any national or international organization. It's not celebrated by CERN or the W3C.
The date August 1st doesn't appear to hold any specific significance in the history of the web. The first website was launched on August 6th 1991.
I posed the following three questions this morning on Mastodon:
- Who first decided that August 1st should be "World Wide Web Day"?
- Why did they pick that date?
- When was the first World Wide Web Day celebrated?
Finding answers to these questions has proven stubbornly difficult. Searches on Google have proven futile, and illustrate the growing impact of LLM-generated slop on the web: they turn up dozens of articles celebrating the day, many from news publications playing the "write about what people might search for" game and many others that have distinctive ChatGPT vibes to them.
One early hint we've found is in the "Bylines 2010 Writer's Desk Calendar" by Snowflake Press, published in January 2009. Jessamyn West spotted that on the book's page in the Internet Archive, but it merely lists "World Wide Web Day" at the bottom of the July calendar page (clearly a printing mistake, the heading is meant to align with August 1st on the next page) without any hint as to the origin:

I found two earlier mentions from August 1st 2008 on Twitter, from @GabeMcCauley and from @iJess.
Our earliest news media reference, spotted by Hugo van Kemenade, is also from August 1st 2008: this opinion piece in the Attleboro Massachusetts Sun Chronicle, which has no byline so presumably was written by the paper's editorial board:
Today is World Wide Web Day, but who cares? We'd rather nap than surf. How about you? Better relax while you can: August presages the start of school, a new season of public meetings, worries about fuel costs, the rundown to the presidential election and local races.
So the mystery remains! Who decided that August 1st should be "World Wide Web Day", why that date and how did it spread so widely without leaving a clear origin story?
If your research skills are up to the challenge, join the challenge!
People share a lot of sensitive material on Quora - controversial political views, workplace gossip and compensation, and negative opinions held of companies. Over many years, as they change jobs or change their views, it is important that they can delete or anonymize their previously-written answers.
We opt out of the wayback machine because inclusion would allow people to discover the identity of authors who had written sensitive answers publicly and later had made them anonymous, and because it would prevent authors from being able to remove their content from the internet if they change their mind about publishing it.
2020
Internet Archive Software Library: Flash (via) A fantastic new initiative from the Internet Archive: they’re now archiving Flash (.swf) files and serving them for modern browsers using Ruffle, a Flash Player emulator written in Rust and compiled to WebAssembly. They are fully interactive and audio works too. Considering the enormous quantity of creative material released in Flash over the decades this helps fill a big hole in the Internet’s cultural memory.
2018
Usage of ARIA attributes via HTTP Archive. A neat example of a Google BigQuery query you can run against the HTTP Archive public dataset (a crawl of the “top” websites run periodically by the Internet Archive, which captures the full details of every resource fetched) to see which ARIA attributes are used the most often. Linking to this because I used it successfully today as the basis for my own custom query—I love that it’s possible to analyze a huge representative sample of the modern web in this way.
2017
Elaborate Halloween Costume Tips from a 19th-Century Guide to Fancy Dress (via) The gilded age had some ridiculous parties. Here are highlights of the most popular costume guide of the era, now available on the Internet Archive.
Recovering missing content from the Internet Archive
When I restored my blog last weekend I used the most recent SQL backup of my blog’s database from back in 2010. I thought it had all of my content from before I started my 7 year hiatus, but in watching the 404 logs I started seeing the occasional hit to something that really should have been there but wasn’t. Turns out the SQL backup I was working from was missing some content.
[... 636 words]2009
tr.im is “discontinuing service”. “However, all tr.im links will continue to redirect, and will do so until at least December 31, 2009.Your tweets with tr.im URLs in them will not be affected.”—these statements seem to contradict themselves. Will tr.im URLs in tweets stop working after December 31st or not? Any chance they could hand the domain over to the Internet Archive? At any rate, this is exactly why centralised URL shorteners are a harmful trend.
A new leaf. George Oates is now heading up the Open Library project at the Internet Archive. Sounds like a perfect match.
TinyURL—Archiveteam. Excellent: the Internet Archive are crawling TinyURL (and hopefully other URL shortening services as well). The wiki page was created back in January. UPDATE from comments: Archiveteam are a separate organisation from the Internet Archive.
The Internet Archive should actively partner with bit.ly / tinyurl.com / icanhaz.com etc. and maintain a mirror database of their redirects
— Me, on Twitter
2007
My Future of Web Apps talk as a slidecast
The team at Carson Systems have a pretty quick turnaround on their podcasts; they’ve had full recordings of every speaker up for a few days now. I spent a bunch of time over the weekend splicing the recording of my talk together with my slides, and the result is now available at The Future of OpenID (a slidecast).
[... 177 words]