Posts tagged sqlite, performance
Filters: sqlite × performance × Sorted by date
Optimizing Datasette (and other weeknotes)
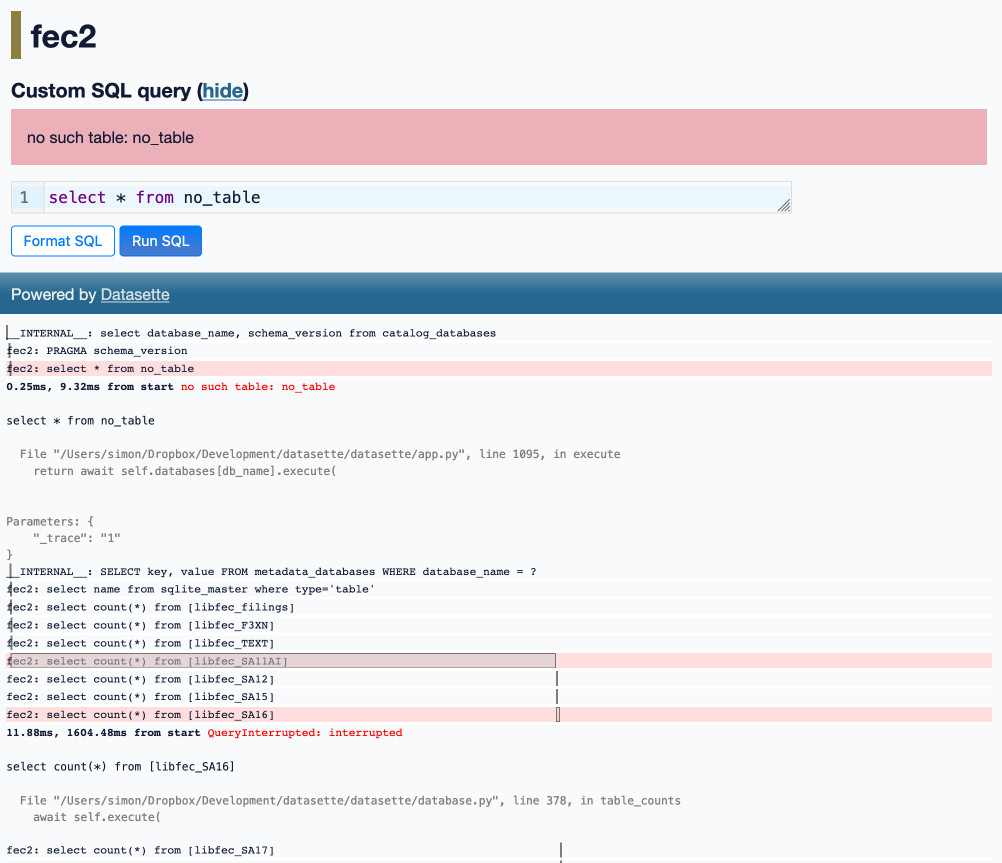
I’ve been working with Alex Garcia on an experiment involving using Datasette to explore FEC contributions. We currently have a 11GB SQLite database—trivial for SQLite to handle, but at the upper end of what I’ve comfortably explored with Datasette in the past.
[... 2,069 words]My architecture is a monolith written in Go (this is intentional, I sacrificed scalability to improve my shipping speed), and this is where SQLite shines. With a DB located on the local NVMe disk, a 5$ VPS can deliver a whopping 60K reads and 20K writes per second.
Performance analysis indicates that SQLite spends very little time doing bytecode decoding and dispatch. Most CPU cycles are consumed in walking B-Trees, doing value comparisons, and decoding records - all of which happens in compiled C code. Bytecode dispatch is using less than 3% of the total CPU time, according to my measurements.
So at least in the case of SQLite, compiling all the way down to machine code might provide a performance boost 3% or less. That's not very much, considering the size, complexity, and portability costs involved.
Optimizing SQLite for servers (via) Sylvain Kerkour's comprehensive set of lessons learned running SQLite for server-based applications.
There's a lot of useful stuff in here, including detailed coverage of the different recommended PRAGMA settings.
There was also a tip I haven't seen before about BEGIN IMMEDIATE transactions:
By default, SQLite starts transactions in
DEFERREDmode: they are considered read only. They are upgraded to a write transaction that requires a database lock in-flight, when query containing a write/update/delete statement is issued.The problem is that by upgrading a transaction after it has started, SQLite will immediately return a
SQLITE_BUSYerror without respecting thebusy_timeoutpreviously mentioned, if the database is already locked by another connection.This is why you should start your transactions with
BEGIN IMMEDIATEinstead of onlyBEGIN. If the database is locked when the transaction starts, SQLite will respectbusy_timeout.
DiskCache (via) Grant Jenks built DiskCache as an alternative caching backend for Django (also usable without Django), using a SQLite database on disk. The performance numbers are impressive—it even beats memcached in microbenchmarks, due to avoiding the need to access the network.
The source code (particularly in core.py) is a great case-study in SQLite performance optimization, after five years of iteration on making it all run as fast as possible.
Batch size one billion: SQLite insert speedups, from the useful to the absurd (via) Useful, detailed review of ways to maximize the performance of inserting a billion integers into a SQLite database table.
Apply conversion functions to data in SQLite columns with the sqlite-utils CLI tool
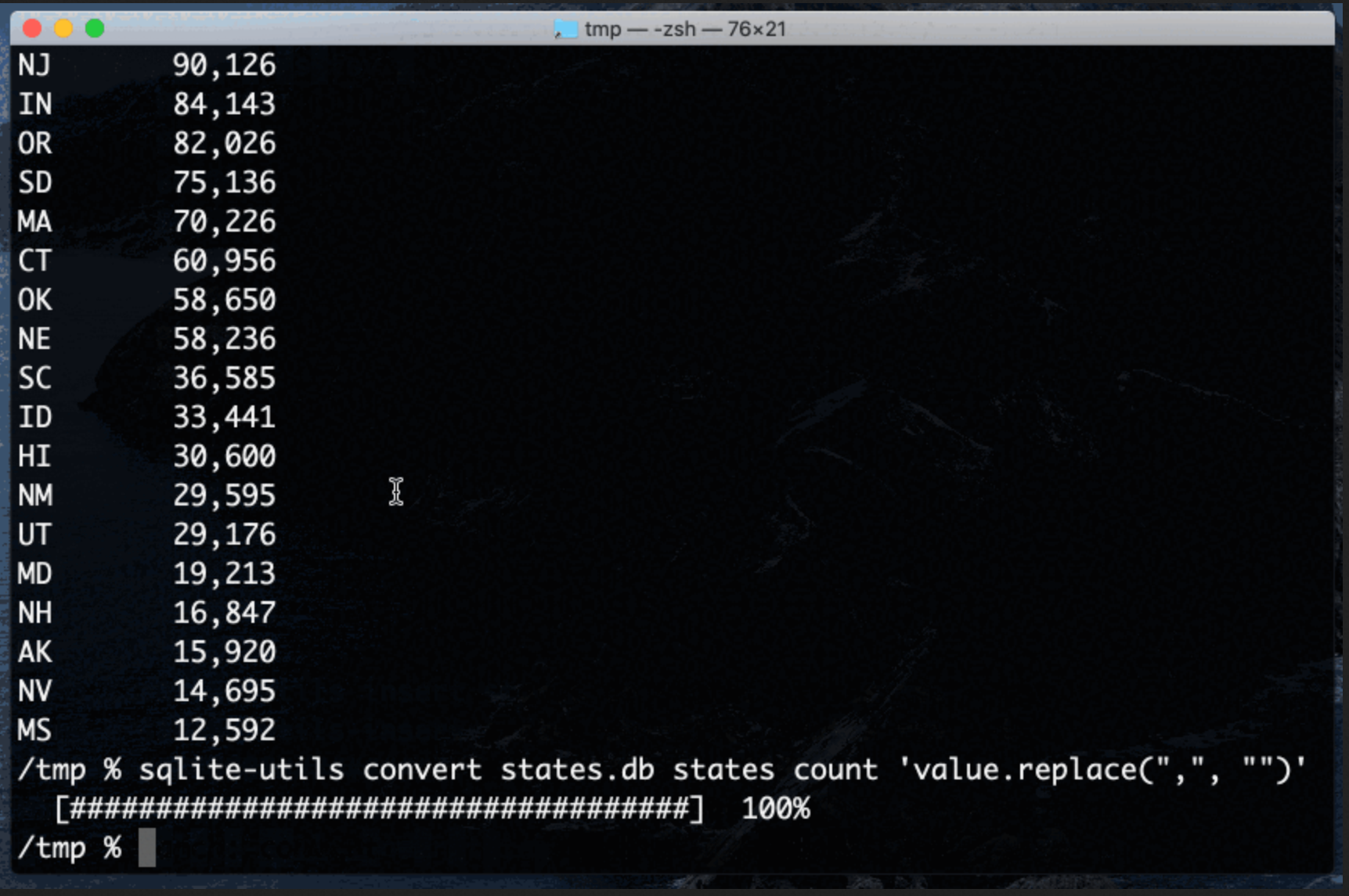
Earlier this week I released sqlite-utils 3.14 with a powerful new command-line tool: sqlite-utils convert, which applies a conversion function to data stored in a SQLite column.
The latest SQLite 3.8.7 alpha version is 50% faster than the 3.7.17 release from 16 months ago. That is to say, it does 50% more work using the same number of CPU cycles. [...] The 50% faster number above is not about better query plans. This is 50% faster at the low-level grunt work of moving bits on and off disk and search b-trees. We have achieved this by incorporating hundreds of micro-optimizations. Each micro-optimization might improve the performance by as little as 0.05%. If we get one that improves performance by 0.25%, that is considered a huge win. Each of these optimizations is unmeasurable on a real-world system (we have to use cachegrind to get repeatable run-times) but if you do enough of them, they add up.
Many Small Queries Are Efficient In SQLite. Since SQLite runs in-process rather than being accessed over a network it avoids the per-query overhead of network round trips. This means that while MySQL or PostgreSQL applications need to avoid N+1 query patterns that create 100s of queries per request, SQLite apps can be designed differently: provided you hit indexes or small tables, 200 queries just means 200 extra cheap function calls.