November 2025
156 posts: 13 entries, 39 links, 21 quotes, 6 notes, 77 beats
Nov. 6, 2025
Code research projects with async coding agents like Claude Code and Codex
I’ve been experimenting with a pattern for LLM usage recently that’s working out really well: asynchronous code research tasks. Pick a research question, spin up an asynchronous coding agent and let it go and run some experiments and report back when it’s done.
[... 2,017 words]Video + notes on upgrading a Datasette plugin for the latest 1.0 alpha, with help from uv and OpenAI Codex CLI
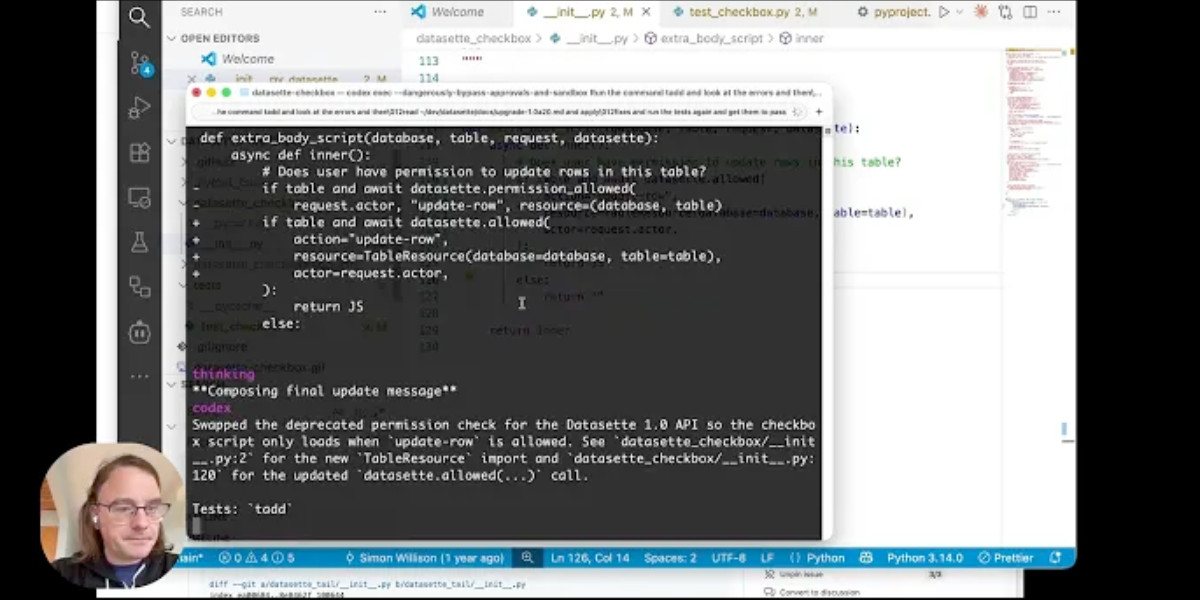
I’m upgrading various plugins for compatibility with the new Datasette 1.0a20 alpha release and I decided to record a video of the process. This post accompanies that video with detailed additional notes.
[... 1,094 words]At the start of the year, most people loosely following AI probably knew of 0 [Chinese] AI labs. Now, and towards wrapping up 2025, I’d say all of DeepSeek, Qwen, and Kimi are becoming household names. They all have seasons of their best releases and different strengths. The important thing is this’ll be a growing list. A growing share of cutting edge mindshare is shifting to China. I expect some of the likes of Z.ai, Meituan, or Ant Ling to potentially join this list next year. For some of these labs releasing top tier benchmark models, they literally started their foundation model effort after DeepSeek. It took many Chinese companies only 6 months to catch up to the open frontier in ballpark of performance, now the question is if they can offer something in a niche of the frontier that has real demand for users.
— Nathan Lambert, 5 Thoughts on Kimi K2 Thinking
Kimi K2 Thinking. Chinese AI lab Moonshot's Kimi K2 established itself as one of the largest open weight models - 1 trillion parameters - back in July. They've now released the Thinking version, also a trillion parameters (MoE, 32B active) and also under their custom modified (so not quite open source) MIT license.
Starting with Kimi K2, we built it as a thinking agent that reasons step-by-step while dynamically invoking tools. It sets a new state-of-the-art on Humanity's Last Exam (HLE), BrowseComp, and other benchmarks by dramatically scaling multi-step reasoning depth and maintaining stable tool-use across 200–300 sequential calls. At the same time, K2 Thinking is a native INT4 quantization model with 256k context window, achieving lossless reductions in inference latency and GPU memory usage.
This one is only 594GB on Hugging Face - Kimi K2 was 1.03TB - which I think is due to the new INT4 quantization. This makes the model both cheaper and faster to host.
So far the only people hosting it are Moonshot themselves. I tried it out both via their own API and via the OpenRouter proxy to it, via the llm-moonshot plugin (by NickMystic) and my llm-openrouter plugin respectively.
The buzz around this model so far is very positive. Could this be the first open weight model that's competitive with the latest from OpenAI and Anthropic, especially for long-running agentic tool call sequences?
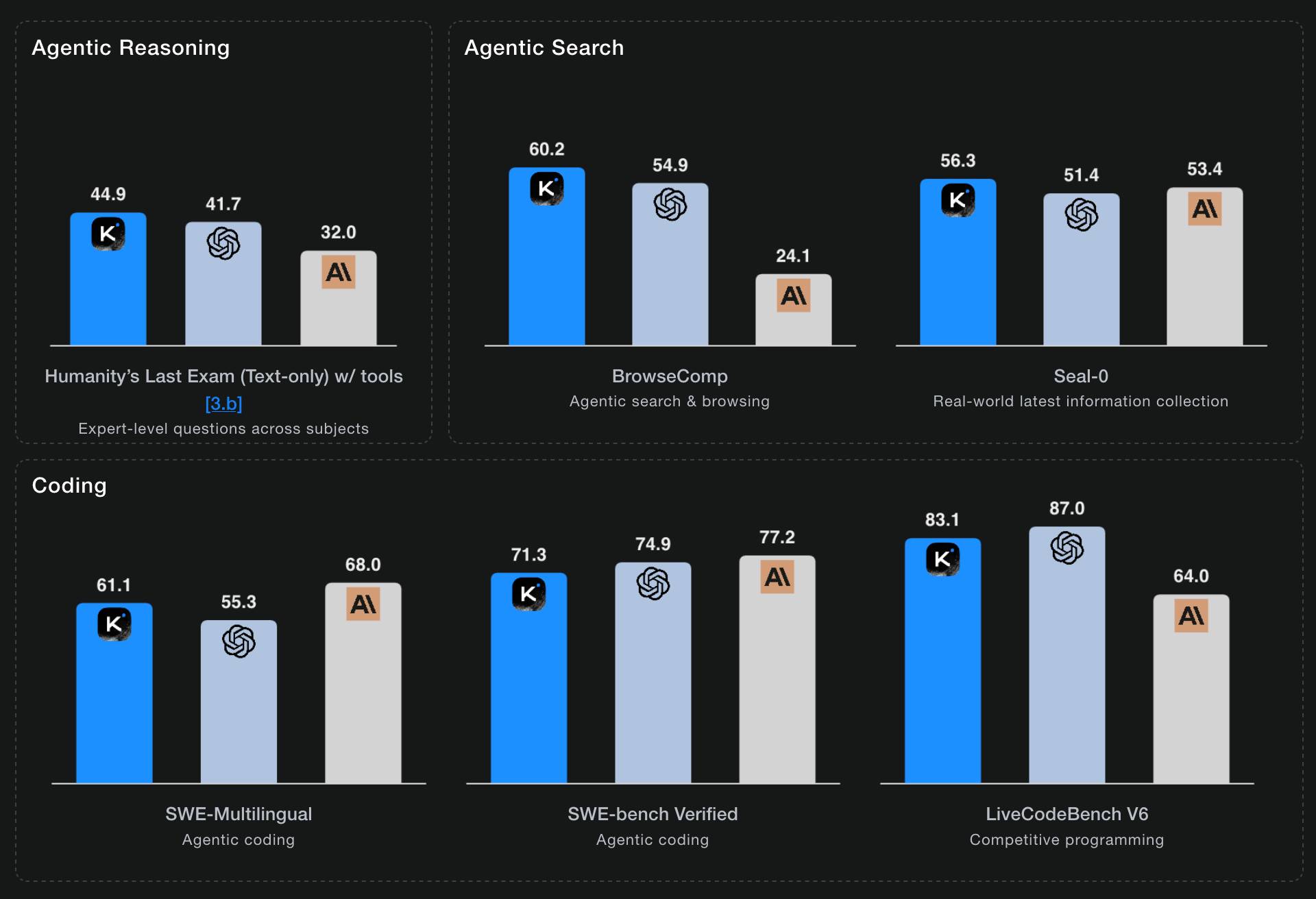
Moonshot AI's self-reported benchmark scores show K2 Thinking beating the top OpenAI and Anthropic models (GPT-5 and Sonnet 4.5 Thinking) at "Agentic Reasoning" and "Agentic Search" but not quite top for "Coding":
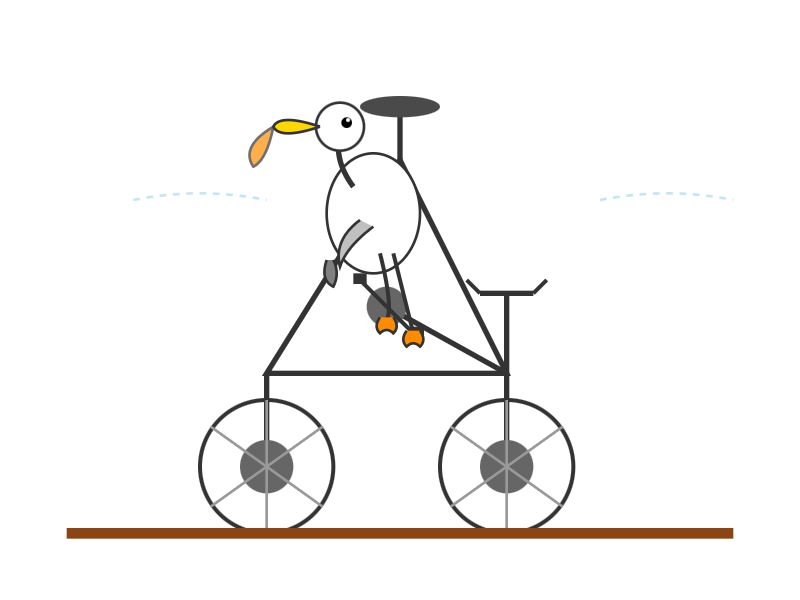
I ran a couple of pelican tests:
llm install llm-moonshot
llm keys set moonshot # paste key
llm -m moonshot/kimi-k2-thinking 'Generate an SVG of a pelican riding a bicycle'

llm install llm-openrouter
llm keys set openrouter # paste key
llm -m openrouter/moonshotai/kimi-k2-thinking \
'Generate an SVG of a pelican riding a bicycle'
Artificial Analysis said:
Kimi K2 Thinking achieves 93% in 𝜏²-Bench Telecom, an agentic tool use benchmark where the model acts as a customer service agent. This is the highest score we have independently measured. Tool use in long horizon agentic contexts was a strength of Kimi K2 Instruct and it appears this new Thinking variant makes substantial gains
CNBC quoted a source who provided the training price for the model:
The Kimi K2 Thinking model cost $4.6 million to train, according to a source familiar with the matter. [...] CNBC was unable to independently verify the DeepSeek or Kimi figures.
MLX developer Awni Hannun got it working on two 512GB M3 Ultra Mac Studios:
The new 1 Trillion parameter Kimi K2 Thinking model runs well on 2 M3 Ultras in its native format - no loss in quality!
The model was quantization aware trained (qat) at int4.
Here it generated ~3500 tokens at 15 toks/sec using pipeline-parallelism in mlx-lm
Here's the 658GB mlx-community model.
Nov. 7, 2025
My trepidation extends to complex literature searches. I use LLMs as secondary librarians when I’m doing research. They reliably find primary sources (articles, papers, etc.) that I miss in my initial searches.
But these searches are dangerous. I distrust LLM librarians. There is so much data in the world: you can (in good faith!) find evidence to support almost any position or conclusion. ChatGPT is not a human, and, unlike teachers & librarians & scholars, ChatGPT does not have a consistent, legible worldview. In my experience, it readily agrees with any premise you hand it — and brings citations. It may have read every article that can be read, but it has no real opinion — so it is not a credible expert.
— Ben Stolovitz, How I use AI
You should write an agent (via) Thomas Ptacek on the Fly blog:
Agents are the most surprising programming experience I’ve had in my career. Not because I’m awed by the magnitude of their powers — I like them, but I don’t like-like them. It’s because of how easy it was to get one up on its legs, and how much I learned doing that.
I think he's right: hooking up a simple agentic loop that prompts an LLM and runs a tool for it any time it request one really is the new "hello world" of AI engineering.
Game design is simple, actually (via) Game design legend Raph Koster (Ultima Online, Star Wars Galaxies and many more) provides a deeply informative and delightfully illustrated "twelve-step program for understanding game design."
You know it's going to be good when the first section starts by defining "fun".
Using Codex CLI with gpt-oss:120b on an NVIDIA DGX Spark via Tailscale. Inspired by a YouTube comment I wrote up how I run OpenAI's Codex CLI coding agent against the gpt-oss:120b model running in Ollama on my NVIDIA DGX Spark via a Tailscale network.
It takes a little bit of work to configure but the result is I can now use Codex CLI on my laptop anywhere in the world against a self-hosted model.
I used it to build this space invaders clone.
My hunch is that existing LLMs make it easier to build a new programming language in a way that captures new developers.
Most programming languages are similar enough to existing languages that you only need to know a small number of details to use them: what's the core syntax for variables, loops, conditionals and functions? How does memory management work? What's the concurrency model?
For many languages you can fit all of that, including illustrative examples, in a few thousand tokens of text.
So ship your new programming language with a Claude Skills style document and give your early adopters the ability to write it with LLMs. The LLMs should handle that very well, especially if they get to run an agentic loop against a compiler or even a linter that you provide.
This post started as a comment.
I have AiDHD
It has never been easier to build an MVP and in turn, it has never been harder to keep focus. When new features always feel like they're just a prompt away, feature creep feels like a never ending battle. Being disciplined is more important than ever.
AI still doesn't change one very important thing: you still need to make something people want. I think that getting users (even free ones) will become significantly harder as the bar for user's time will only get higher as their options increase.
Being quicker to get to the point of failure is actually incredibly valuable. Even just over a year ago, many of these projects would have taken months to build.
— Josh Cohenzadeh, AiDHD
Nov. 8, 2025
Mastodon 4.5 (via) This new release of Mastodon adds two of my most desired features!
The first is support for quote posts. This had already become an unofficial feature in the client apps I was using (phanpy.social on the web and Ivory on iOS) but now it's officially part of Mastodon's core platform.
Much more notably though:
Fetch All Replies: Completing the Conversation Flow
Users on servers running 4.4 and earlier versions have likely experienced the confusion of seeing replies appearing on other servers but not their own. Mastodon 4.5 automatically checks for missing replies upon page load and again every 15 minutes, enhancing continuity of conversations across the Fediverse.
The absolute worst thing about Mastodon - especially if you run on your own independent server - is that the nature of the platform means you can't be guaranteed to see every reply to a post your are viewing that originated on another instance (previously).
This leads to an unpleasant reply-guy effect where you find yourself replying to a post saying the exact same thing that everyone else said... because you didn't see any of the other replies before you posted!
Mastodon 4.5 finally solves this problem!
I went looking for the GitHub issue about this and found this one that quoted my complaint about this from December 2022, which is marked as a duplicate of this Fetch whole conversation threads issue from 2018.
So happy to see this finally resolved.
The big advantage of MCP over OpenAPI is that it is very clear about auth. [...]
Maybe an agent could read the docs and write code to auth. But we don't actually want that, because it implies the agent gets access to the API token! We want the agent's harness to handle that and never reveal the key to the agent. [...]
OAuth has always assumed that the client knows what API it's talking to, and so the client's developer can register the client with that API in advance to get a client_id/client_secret pair. Agents, though, don't know what MCPs they'll talk to in advance.
So MCP requires OAuth dynamic client registration (RFC 7591), which practically nobody actually implemented prior to MCP. DCR might as well have been introduced by MCP, and may actually be the most important unlock in the whole spec.
Nov. 9, 2025
Reverse engineering Codex CLI to get GPT-5-Codex-Mini to draw me a pelican

OpenAI partially released a new model yesterday called GPT-5-Codex-Mini, which they describe as "a more compact and cost-efficient version of GPT-5-Codex". It’s currently only available via their Codex CLI tool and VS Code extension, with proper API access "coming soon". I decided to use Codex to reverse engineer the Codex CLI tool and give me the ability to prompt the new model directly.
[... 1,774 words]Pelican on a Bike—Raytracer Edition (via) beetle_b ran this prompt against a bunch of recent LLMs:
Write a POV-Ray file that shows a pelican riding on a bicycle.
This turns out to be a harder challenge than SVG, presumably because there are less examples of POV-Ray in the training data:
Most produced a script that failed to parse. I would paste the error back into the chat and let it attempt a fix.
The results are really fun though! A lot of them end up accompanied by a weird floating egg for some reason - here's Claude Opus 4:

I think the best result came from GPT-5 - again with the floating egg though!

I decided to try this on the new gpt-5-codex-mini, using the trick I described yesterday. Here's the code it wrote.
./target/debug/codex prompt -m gpt-5-codex-mini \
"Write a POV-Ray file that shows a pelican riding on a bicycle."
It turns out you can render POV files on macOS like this:
brew install povray
povray demo.pov # produces demo.png
The code GPT-5 Codex Mini created didn't quite work, so I round-tripped it through Sonnet 4.5 via Claude Code a couple of times - transcript here. Once it had fixed the errors I got this:

That's significantly worse than the one beetle_b got from GPT-5 Mini!