Tuesday, 8th April 2025
llm-hacker-news. I built this new plugin to exercise the new register_fragment_loaders() plugin hook I added to LLM 0.24. It's the plugin equivalent of the Bash script I've been using to summarize Hacker News conversations for the past 18 months.
You can use it like this:
llm install llm-hacker-news
llm -f hn:43615912 'summary with illustrative direct quotes'
You can see the output in this issue.
The plugin registers a hn: prefix - combine that with the ID of a Hacker News conversation to pull that conversation into the context.
It uses the Algolia Hacker News API which returns JSON like this. Rather than feed the JSON directly to the LLM it instead converts it to a hopefully more LLM-friendly format that looks like this example from the plugin's test:
[1] BeakMaster: Fish Spotting Techniques
[1.1] CoastalFlyer: The dive technique works best when hunting in shallow waters.
[1.1.1] PouchBill: Agreed. Have you tried the hover method near the pier?
[1.1.2] WingSpan22: My bill gets too wet with that approach.
[1.1.2.1] CoastalFlyer: Try tilting at a 40° angle like our Australian cousins.
[1.2] BrownFeathers: Anyone spotted those "silver fish" near the rocks?
[1.2.1] GulfGlider: Yes! They're best caught at dawn.
Just remember: swoop > grab > lift
That format was suggested by Claude, which then wrote most of the plugin implementation for me. Here's that Claude transcript.
We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. [...]
In addition, we're also adding the HF version of Llama-4-Maverick to Arena, with leaderboard results published shortly. Meta’s interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference. As a result of that we are updating our leaderboard policies to reinforce our commitment to fair, reproducible evaluations so this confusion doesn’t occur in the future.
Imagine if Ford published a paper saying it was thinking about long term issues of the automobiles it made and one of those issues included “misalignment “Car as an adversary”” and when you asked Ford for clarification the company said “yes, we believe as we make our cars faster and more capable, they may sometimes take actions harmful to human well being” and you say “oh, wow, thanks Ford, but… what do you mean precisely?” and Ford says “well, we cannot rule out the possibility that the car might decide to just start running over crowds of people” and then Ford looks at you and says “this is a long-term research challenge”.
— Jack Clark, DeepMind gazes into the AGI future
Stop syncing everything. In which Carl Sverre announces Graft, a fascinating new open source Rust data synchronization engine he's been working on for the past year.
Carl's recent talk at the Vancouver Systems meetup explains Graft in detail, including this slide which helped everything click into place for me:

Graft manages a volume, which is a collection of pages (currently at a fixed 4KB size). A full history of that volume is maintained using snapshots. Clients can read and write from particular snapshot versions for particular pages, and are constantly updated on which of those pages have changed (while not needing to synchronize the actual changed data until they need it).
This is a great fit for B-tree databases like SQLite.
The Graft project includes a SQLite VFS extension that implements multi-leader read-write replication on top of a Graft volume. You can see a demo of that running at 36m15s in the video, or consult the libgraft extension documentation and try it yourself.
The section at the end on What can you build with Graft? has some very useful illustrative examples:
Offline-first apps: Note-taking, task management, or CRUD apps that operate partially offline. Graft takes care of syncing, allowing the application to forget the network even exists. When combined with a conflict handler, Graft can also enable multiplayer on top of arbitrary data.
Cross-platform data: Eliminate vendor lock-in and allow your users to seamlessly access their data across mobile platforms, devices, and the web. Graft is architected to be embedded anywhere
Stateless read replicas: Due to Graft's unique approach to replication, a database replica can be spun up with no local state, retrieve the latest snapshot metadata, and immediately start running queries. No need to download all the data and replay the log.
Replicate anything: Graft is just focused on consistent page replication. It doesn't care about what's inside those pages. So go crazy! Use Graft to sync AI models, Parquet or Lance files, Geospatial tilesets, or just photos of your cats. The sky's the limit with Graft.
Writing C for curl
(via)
Daniel Stenberg maintains curl - a library that deals with the most hostile of environments, parsing content from the open internet - as 180,000 lines of C89 code.
He enforces a strict 80 character line width for readability, zero compiler warnings, avoids "bad" functions like gets, sprintf, strcat, strtok and localtime (CI fails if it spots them, I found that script here) and curl has their own custom dynamic buffer and parsing functions.
They take particular care around error handling:
In curl we always check for errors and we bail out without leaking any memory if (when!) they happen.
I like their commitment to API/ABI robustness:
Every function and interface that is publicly accessible must never be changed in a way that risks breaking the API or ABI. For this reason and to make it easy to spot the functions that need this extra precautions, we have a strict rule: public functions are prefixed with “curl_” and no other functions use that prefix.
Mistral Small 3.1 on Ollama. Mistral Small 3.1 (previously) is now available through Ollama, providing an easy way to run this multi-modal (vision) model on a Mac (and other platforms, though I haven't tried those myself).
I had to upgrade Ollama to the most recent version to get it to work - prior to that I got a Error: unable to load model message. Upgrades can be accessed through the Ollama macOS system tray icon.
I fetched the 15GB model by running:
ollama pull mistral-small3.1
Then used llm-ollama to run prompts through it, including one to describe this image:
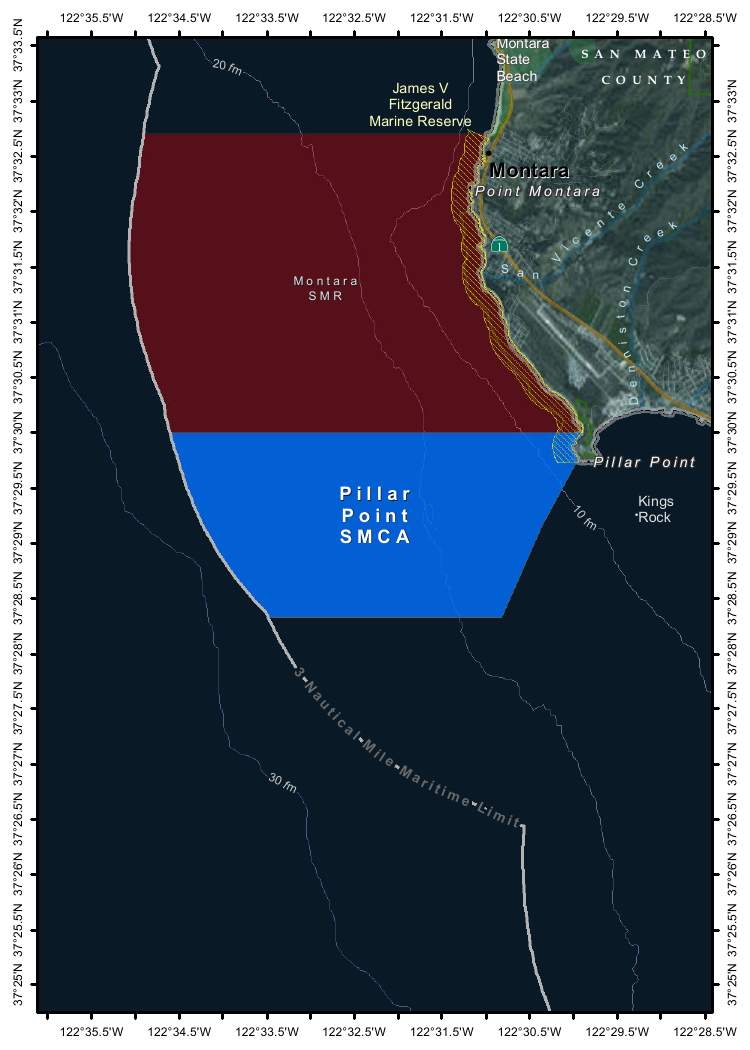{kind=link}
llm install llm-ollama
llm -m mistral-small3.1 'describe this image' -a https://static.simonwillison.net/static/2025/Mpaboundrycdfw-1.png
Here's the output. It's good, though not quite as impressive as the description I got from the slightly larger Qwen2.5-VL-32B.
I also tried it on a scanned (private) PDF of hand-written text with very good results, though it did misread one of the hand-written numbers.
Political Email Extraction Leaderboard (via) Derek Willis collects "political fundraising emails from just about every committee" - 3,000-12,000 a month - and has created an LLM benchmark from 1,000 of them that he collected last November.
He explains the leaderboard in this blog post. The goal is to have an LLM correctly identify the the committee name from the disclaimer text included in the email.
Here's the code he uses to run prompts using Ollama. It uses this system prompt:
Produce a JSON object with the following keys: 'committee', which is the name of the committee in the disclaimer that begins with Paid for by but does not include 'Paid for by', the committee address or the treasurer name. If no committee is present, the value of 'committee' should be None. Also add a key called 'sender', which is the name of the person, if any, mentioned as the author of the email. If there is no person named, the value is None. Do not include any other text, no yapping.
Gemini 2.5 Pro tops the leaderboard at the moment with 95.40%, but the new Mistral Small 3.1 manages 5th place with 85.70%, pretty good for a local model!
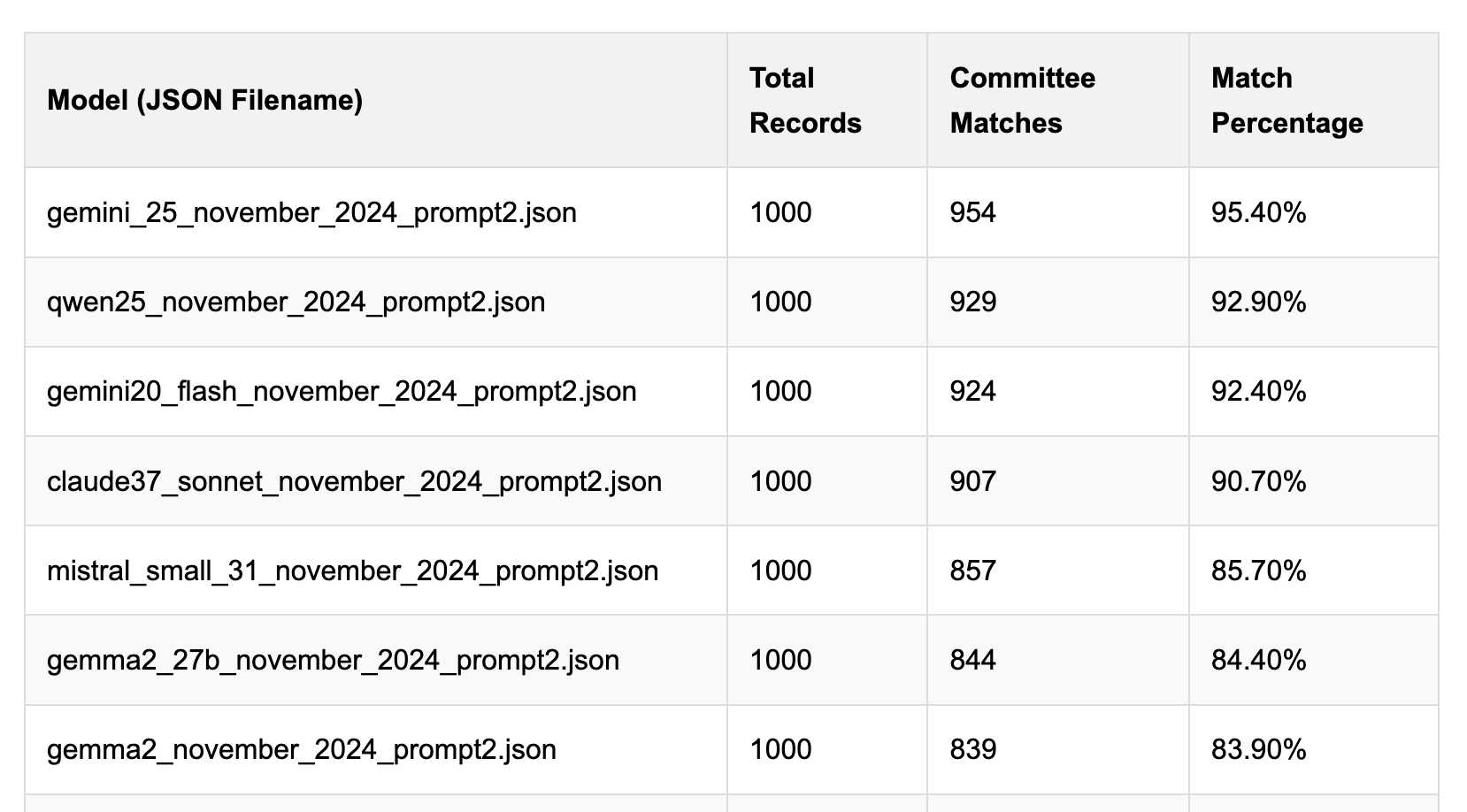
I said we need our own evals in my talk at the NICAR Data Journalism conference last month, without realizing Derek has been running one since January.
{kind=link}