Wednesday, 25th September 2024
DJP: A plugin system for Django
DJP is a new plugin mechanism for Django, built on top of Pluggy. I announced the first version of DJP during my talk yesterday at DjangoCon US 2024, How to design and implement extensible software with plugins. I’ll post a full write-up of that talk once the video becomes available—this post describes DJP and how to use what I’ve built so far.
[... 1,664 words]The Pragmatic Engineer Podcast: AI tools for software engineers, but without the hype – with Simon Willison. Gergely Orosz has a brand new podcast, and I was the guest for the first episode. We covered a bunch of ground, but my favorite topic was an exploration of the (very legitimate) reasons that many engineers are resistant to taking advantage of AI-assisted programming tools.
We used this model [periodically transmitting configuration to different hosts] to distribute translations, feature flags, configuration, search indexes, etc at Airbnb. But instead of SQLite we used Sparkey, a KV file format developed by Spotify. In early years there was a Cron job on every box that pulled that service’s thingies; then once we switched to Kubernetes we used a daemonset & host tagging (taints?) to pull a variety of thingies to each host and then ensure the services that use the thingies only ran on the hosts that had the thingies.
Solving a bug with o1-preview, files-to-prompt and LLM.
I added a new feature to DJP this morning: you can now have plugins specify their middleware in terms of how it should be positioned relative to other middleware - inserted directly before or directly after django.middleware.common.CommonMiddleware for example.
At one point I got stuck with a weird test failure, and after ten minutes of head scratching I decided to pipe the entire thing into OpenAI's o1-preview to see if it could spot the problem. I used files-to-prompt to gather the code and LLM to run the prompt:
files-to-prompt **/*.py -c | llm -m o1-preview "
The middleware test is failing showing all of these - why is MiddlewareAfter repeated so many times?
['MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware4', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware', 'MiddlewareBefore']"The model whirled away for a few seconds and spat out an explanation of the problem - one of my middleware classes was accidentally calling self.get_response(request) in two different places.
I did enjoy how o1 attempted to reference the relevant Django documentation and then half-repeated, half-hallucinated a quote from it:

This took 2,538 input tokens and 4,354 output tokens - by my calculations at $15/million input and $60/million output that prompt cost just under 30 cents.
Llama 3.2. In further evidence that AI labs are terrible at naming things, Llama 3.2 is a huge upgrade to the Llama 3 series - they've released their first multi-modal vision models!
Today, we’re releasing Llama 3.2, which includes small and medium-sized vision LLMs (11B and 90B), and lightweight, text-only models (1B and 3B) that fit onto edge and mobile devices, including pre-trained and instruction-tuned versions.
The 1B and 3B text-only models are exciting too, with a 128,000 token context length and optimized for edge devices (Qualcomm and MediaTek hardware get called out specifically).
Meta partnered directly with Ollama to help with distribution, here's the Ollama blog post. They only support the two smaller text-only models at the moment - this command will get the 3B model (2GB):
ollama run llama3.2
And for the 1B model (a 1.3GB download):
ollama run llama3.2:1b
I had to first upgrade my Ollama by clicking on the icon in my macOS task tray and selecting "Restart to update".
The two vision models are coming to Ollama "very soon".
Once you have fetched the Ollama model you can access it from my LLM command-line tool like this:
pipx install llm
llm install llm-ollama
llm chat -m llama3.2:1b
I tried running my djp codebase through that tiny 1B model just now and got a surprisingly good result - by no means comprehensive, but way better than I would ever expect from a model of that size:
files-to-prompt **/*.py -c | llm -m llama3.2:1b --system 'describe this code'
Here's a portion of the output:
The first section defines several test functions using the
@djp.hookimpldecorator from the djp library. These hook implementations allow you to intercept and manipulate Django's behavior.
test_middleware_order: This function checks that the middleware order is correct by comparing theMIDDLEWAREsetting with a predefined list.test_middleware: This function tests various aspects of middleware:- It retrieves the response from the URL
/from-plugin/using theClientobject, which simulates a request to this view.- It checks that certain values are present in the response:
X-DJP-Middleware-AfterX-DJP-MiddlewareX-DJP-Middleware-Before[...]
I found the GGUF file that had been downloaded by Ollama in my ~/.ollama/models/blobs directory. The following command let me run that model directly in LLM using the llm-gguf plugin:
llm install llm-gguf
llm gguf register-model ~/.ollama/models/blobs/sha256-74701a8c35f6c8d9a4b91f3f3497643001d63e0c7a84e085bed452548fa88d45 -a llama321b
llm chat -m llama321b
Meta themselves claim impressive performance against other existing models:
Our evaluation suggests that the Llama 3.2 vision models are competitive with leading foundation models, Claude 3 Haiku and GPT4o-mini on image recognition and a range of visual understanding tasks. The 3B model outperforms the Gemma 2 2.6B and Phi 3.5-mini models on tasks such as following instructions, summarization, prompt rewriting, and tool-use, while the 1B is competitive with Gemma.
Here's the Llama 3.2 collection on Hugging Face. You need to accept the new Llama 3.2 Community License Agreement there in order to download those models.
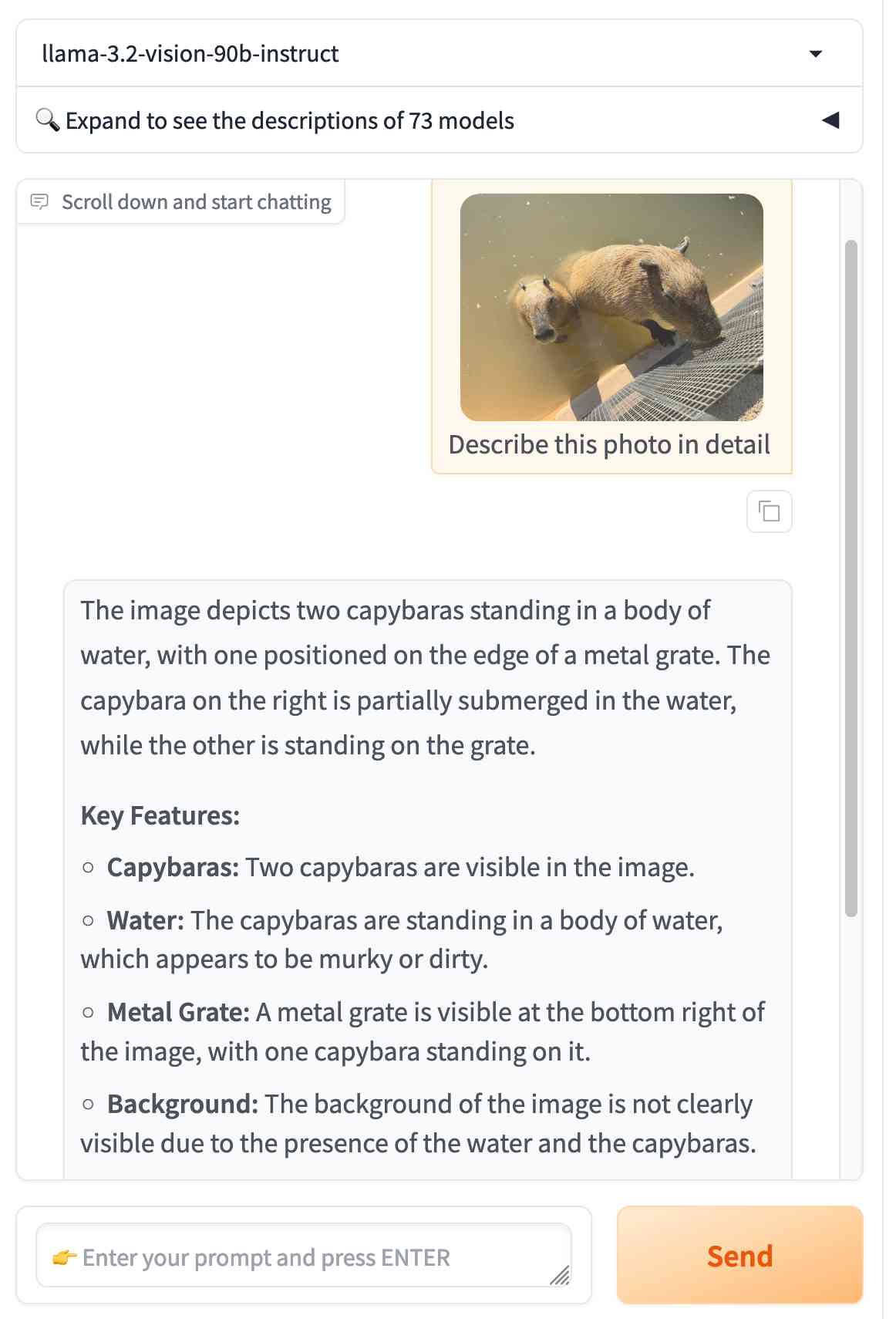
You can try the four new models out via the Chatbot Arena - navigate to "Direct Chat" there and select them from the dropdown menu. You can upload images directly to the chat there to try out the vision features.