Saturday, 2nd November 2024
SmolLM2 (via) New from Loubna Ben Allal and her research team at Hugging Face:
SmolLM2 is a family of compact language models available in three size: 135M, 360M, and 1.7B parameters. They are capable of solving a wide range of tasks while being lightweight enough to run on-device. [...]
It was trained on 11 trillion tokens using a diverse dataset combination: FineWeb-Edu, DCLM, The Stack, along with new mathematics and coding datasets that we curated and will release soon.
The model weights are released under an Apache 2 license. I've been trying these out using my llm-gguf plugin for LLM and my first impressions are really positive.
Here's a recipe to run a 1.7GB Q8 quantized model from lmstudio-community:
llm install llm-gguf
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-1.7B-Instruct-GGUF/resolve/main/SmolLM2-1.7B-Instruct-Q8_0.gguf -a smol17
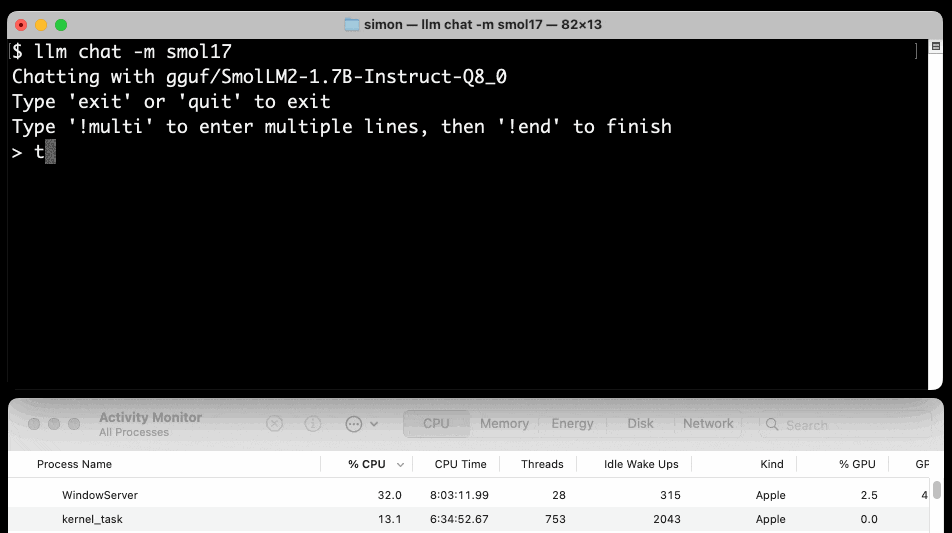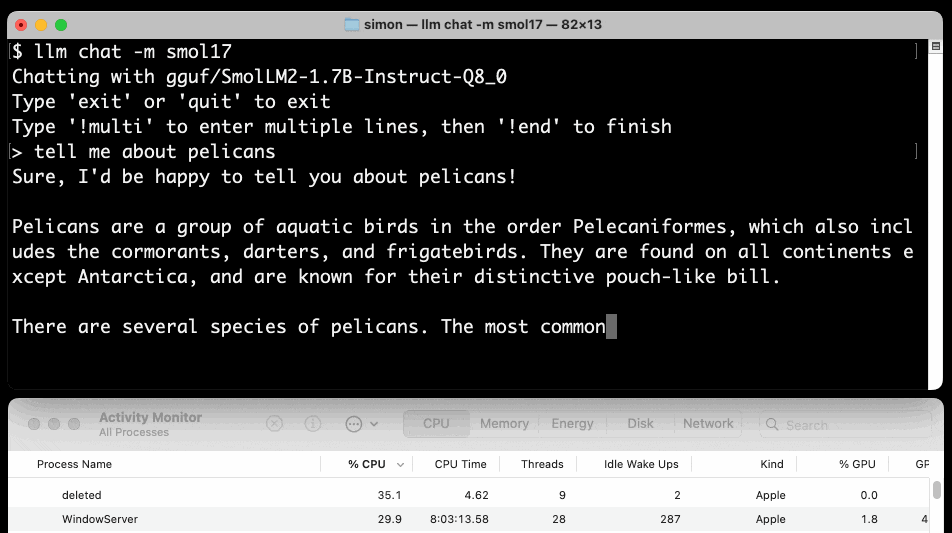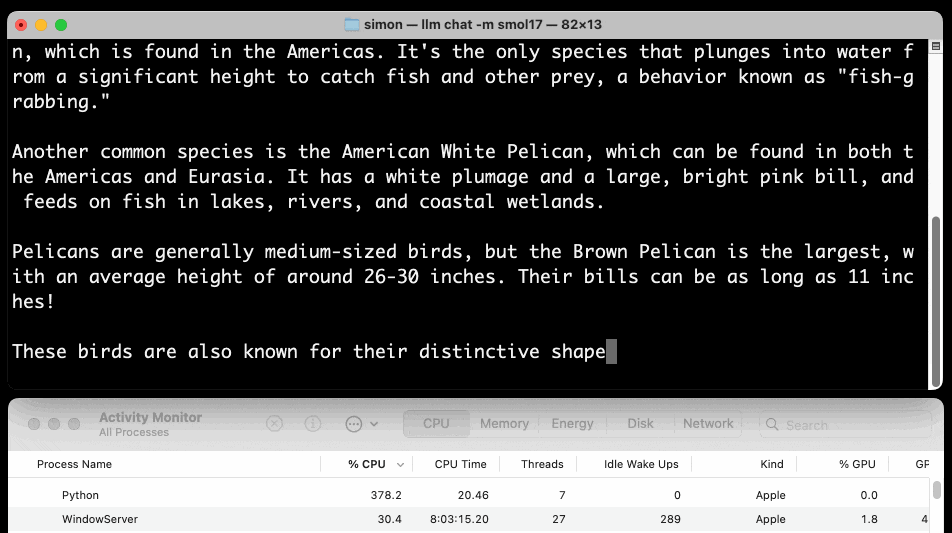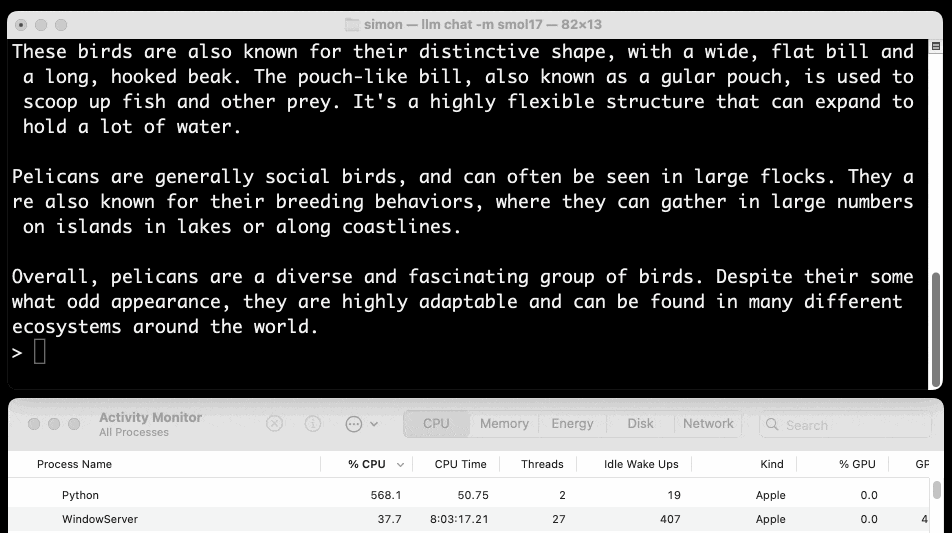
llm chat -m smol17
Or at the other end of the scale, here's how to run the 138MB Q8 quantized 135M model:
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-135M-Instruct-GGUF/resolve/main/SmolLM2-135M-Instruct-Q8_0.gguf' -a smol135m
llm chat -m smol135m
The blog entry to accompany SmolLM2 should be coming soon, but in the meantime here's the entry from July introducing the first version: SmolLM - blazingly fast and remarkably powerful .
Please publish and share more. 💯 to all of this by Jeff Triplett:
Friends, I encourage you to publish more, indirectly meaning you should write more and then share it. [...]
You don’t have to change the world with every post. You might publish a quick thought or two that helps encourage someone else to try something new, listen to a new song, or binge-watch a new series.
Jeff shares my opinion on conclusions: giving myself permission to hit publish even when I haven't wrapped everything up neatly was a huge productivity boost for me:
Our posts are done when you say they are. You do not have to fret about sticking to landing and having a perfect conclusion. Your posts, like this post, are done after we stop writing.
And another 💯 to this footnote:
PS: Write and publish before you write your own static site generator or perfect blogging platform. We have lost billions of good writers to this side quest because they spend all their time working on the platform instead of writing.
Claude Token Counter. Anthropic released a token counting API for Claude a few days ago.
I built this tool for running prompts, images and PDFs against that API to count the tokens in them.
The API is free (albeit rate limited), but you'll still need to provide your own API key in order to use it.
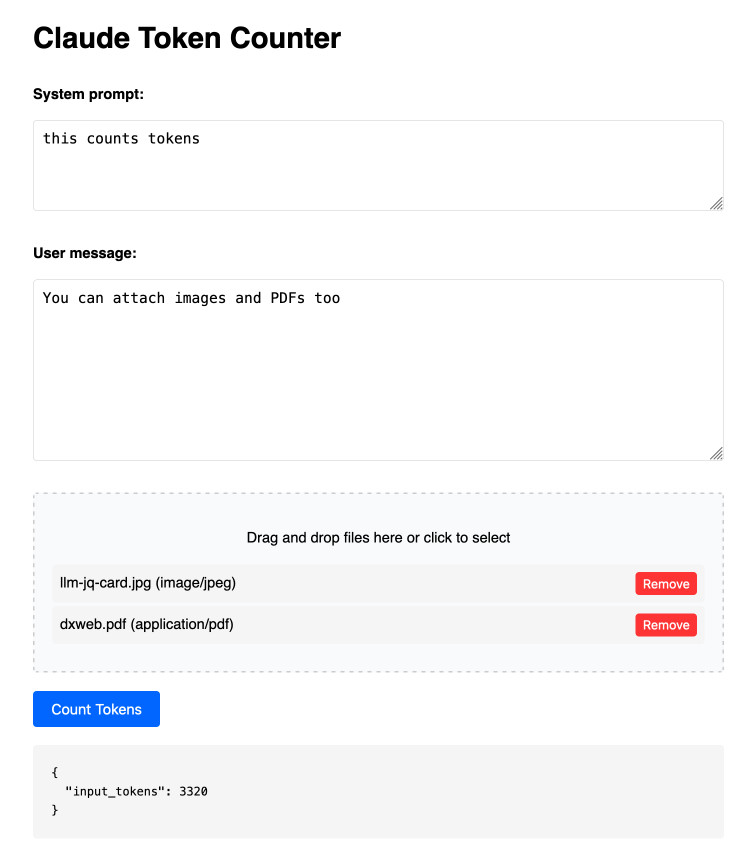
Here's the source code. I built this using two sessions with Claude - one to build the initial tool and a second to add PDF and image support. That second one is a bit of a mess - it turns out if you drop an HTML file onto a Claude conversation it converts it to Markdown for you, but I wanted it to modify the original HTML source.
The API endpoint also allows you to specify a model, but as far as I can tell from running some experiments the token count was the same for Haiku, Opus and Sonnet 3.5.