Friday, 17th March 2023
The surprising ease and effectiveness of AI in a loop (via) Matt Webb on the langchain Python library and the ReAct design pattern, where you plug additional tools into a language model by teaching it to work in a “Thought... Act... Observation” loop where the Act specifies an action it wishes to take (like searching Wikipedia) and an extra layer of software than carries out that action and feeds back the result as the Observation. Matt points out that the ChatGPT 1/10th price drop makes this kind of model usage enormously more cost effective than it was before.
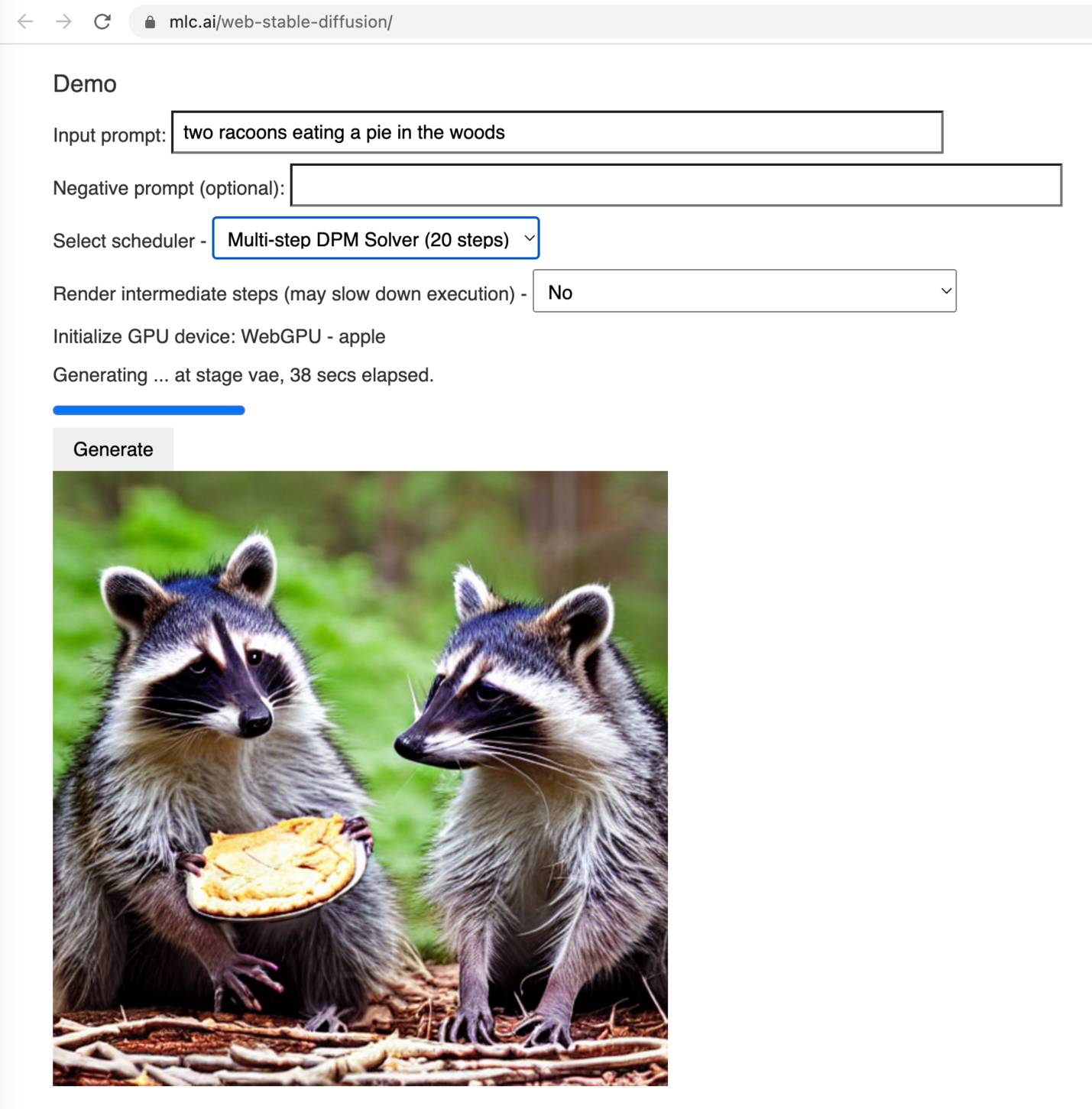
Web Stable Diffusion (via) I just ran the full Stable Diffusion image generation model entirely in my browser, and used it to generate an image of two raccoons eating pie in the woods. I had to use Google Chrome Canary since this depends on WebGPU which still isn't fully rolled out, but it worked perfectly.
A simple Python implementation of the ReAct pattern for LLMs. I implemented the ReAct pattern (for Reason+Act) described in this paper. It's a pattern where you implement additional actions that an LLM can take - searching Wikipedia or running calculations for example - and then teach it how to request that those actions are run, then feed their results back into the LLM.

Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
I think it’s now possible to train a large language model with similar functionality to GPT-3 for $85,000. And I think we might soon be able to run the resulting model entirely in the browser, and give it capabilities that leapfrog it ahead of ChatGPT.
[... 1,751 words]The Unpredictable Abilities Emerging From Large AI Models (via) Nice write-up of the most interesting aspect of large language models: the fact that they gain emergent abilities at certain “breakthrough” size points, and no-one is entirely sure they understand why.
Fine-tune LLaMA to speak like Homer Simpson. Replicate spent 90 minutes fine-tuning LLaMA on 60,000 lines of dialog from the first 12 seasons of the Simpsons, and now it can do a good job of producing invented dialog from any of the characters from the series. This is a really interesting result: I’ve been skeptical about how much value can be had from fine-tuning large models on just a tiny amount of new data, assuming that the new data would be statistically irrelevant compared to the existing model. Clearly my mental model around this was incorrect.