11 posts tagged “tokenization”
How Large Language Models split text up into tokens.
2025
Sam Rose explains how LLMs work with a visual essay. Sam Rose is one of my favorite authors of explorable interactive explanations - here's his previous collection.
Sam joined ngrok in September as a developer educator. Here's his first big visual explainer for them, ostensibly about how prompt caching works but it quickly expands to cover tokenization, embeddings, and the basics of the transformer architecture.
The result is one of the clearest and most accessible introductions to LLM internals I've seen anywhere.

Dummy’s Guide to Modern LLM Sampling (via) This is an extremely useful, detailed set of explanations by @AlpinDale covering the various different sampling strategies used by modern LLMs. LLMs return a set of next-token probabilities for every token in their corpus - a layer above the LLM can then use sampling strategies to decide which one to use.
I finally feel like I understand the difference between Top-K and Top-P! Top-K is when you narrow down to e.g. the 20 most likely candidates for next token and then pick one of those. Top-P instead "the smallest set of words whose combined probability exceeds threshold P" - so if you set it to 0.5 you'll filter out tokens in the lower half of the probability distribution.
There are a bunch more sampling strategies in here that I'd never heard of before - Top-A, Top-N-Sigma, Epsilon-Cutoff and more.
Reading the descriptions here of Repetition Penalty and Don't Repeat Yourself made me realize that I need to be a little careful with those for some of my own uses of LLMs.
I frequently feed larger volumes of text (or code) into an LLM and ask it to output subsets of that text as direct quotes, to answer questions like "which bit of this code handles authentication tokens" or "show me direct quotes that illustrate the main themes in this conversation".
Careless use of frequency penalty strategies might go against what I'm trying to achieve with those prompts.
2024
SQL injection-like attack on LLMs with special tokens. Andrej Karpathy explains something that's been confusing me for the best part of a year:
The decision by LLM tokenizers to parse special tokens in the input string (
<s>,<|endoftext|>, etc.), while convenient looking, leads to footguns at best and LLM security vulnerabilities at worst, equivalent to SQL injection attacks.
LLMs frequently expect you to feed them text that is templated like this:
<|user|>\nCan you introduce yourself<|end|>\n<|assistant|>
But what happens if the text you are processing includes one of those weird sequences of characters, like <|assistant|>? Stuff can definitely break in very unexpected ways.
LLMs generally reserve special token integer identifiers for these, which means that it should be possible to avoid this scenario by encoding the special token as that ID (for example 32001 for <|assistant|> in the Phi-3-mini-4k-instruct vocabulary) while that same sequence of characters in untrusted text is encoded as a longer sequence of smaller tokens.
Many implementations fail to do this! Thanks to Andrej I've learned that modern releases of Hugging Face transformers have a split_special_tokens=True parameter (added in 4.32.0 in August 2023) that can handle it. Here's an example:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
>>> tokenizer.encode("<|assistant|>")
[32001]
>>> tokenizer.encode("<|assistant|>", split_special_tokens=True)
[529, 29989, 465, 22137, 29989, 29958]A better option is to use the apply_chat_template() method, which should correctly handle this for you (though I'd like to see confirmation of that).
A Picture is Worth 170 Tokens: How Does GPT-4o Encode Images? (via) Oran Looney dives into the question of how GPT-4o tokenizes images - an image "costs" just 170 tokens, despite being able to include more text than could be encoded in that many tokens by the standard tokenizer.
There are some really neat tricks in here. I particularly like the experimental validation section where Oran creates 5x5 (and larger) grids of coloured icons and asks GPT-4o to return a JSON matrix of icon descriptions. This works perfectly at 5x5, gets 38/49 for 7x7 and completely fails at 13x13.
I'm not convinced by the idea that GPT-4o runs standard OCR such as Tesseract to enhance its ability to interpret text, but I would love to understand more about how this all works. I imagine a lot can be learned from looking at how openly licensed vision models such as LLaVA work, but I've not tried to understand that myself yet.
mistralai/mistral-common. New from Mistral: mistral-common, an open source Python library providing "a set of tools to help you work with Mistral models".
So far that means a tokenizer! This is similar to OpenAI's tiktoken library in that it lets you run tokenization in your own code, which crucially means you can count the number of tokens that you are about to use - useful for cost estimates but also for cramming the maximum allowed tokens in the context window for things like RAG.
Mistral's library is better than tiktoken though, in that it also includes logic for correctly calculating the tokens needed for conversation construction and tool definition. With OpenAI's APIs you're currently left guessing how many tokens are taken up by these advanced features.
Anthropic haven't published any form of tokenizer at all - it's the feature I'd most like to see from them next.
Here's how to explore the vocabulary of the tokenizer:
MistralTokenizer.from_model(
"open-mixtral-8x22b"
).instruct_tokenizer.tokenizer.vocab()[:12]
['<unk>', '<s>', '</s>', '[INST]', '[/INST]', '[TOOL_CALLS]', '[AVAILABLE_TOOLS]', '[/AVAILABLE_TOOLS]', '[TOOL_RESULTS]', '[/TOOL_RESULTS]']
The Tokenizer Playground (via) I built a tool like this a while ago, but this one is much better: it provides an interface for experimenting with tokenizers from a wide range of model architectures, including Llama, Claude, Mistral and Grok-1—all running in the browser using Transformers.js.
Let’s build the GPT Tokenizer. When Andrej Karpathy left OpenAI last week a lot of people expressed hope that he would be increasing his output of educational YouTube videos.
Here’s an in-depth 2 hour dive into how tokenizers work and how to build one from scratch, published this morning.
The section towards the end, “revisiting and explaining the quirks of LLM tokenization”, helps explain a number of different LLM weaknesses—inability to reverse strings, confusion over arithmetic and even a note on why YAML can work better than JSON when providing data to LLMs (the same data can be represented in less tokens).
2023
Llama encoder and decoder. I forked my GPT tokenizer Observable notebook to create a similar tool for exploring the tokenization scheme used by the Llama family of LLMs, using the new llama-tokenizer-js JavaScript library.
Understanding GPT tokenizers
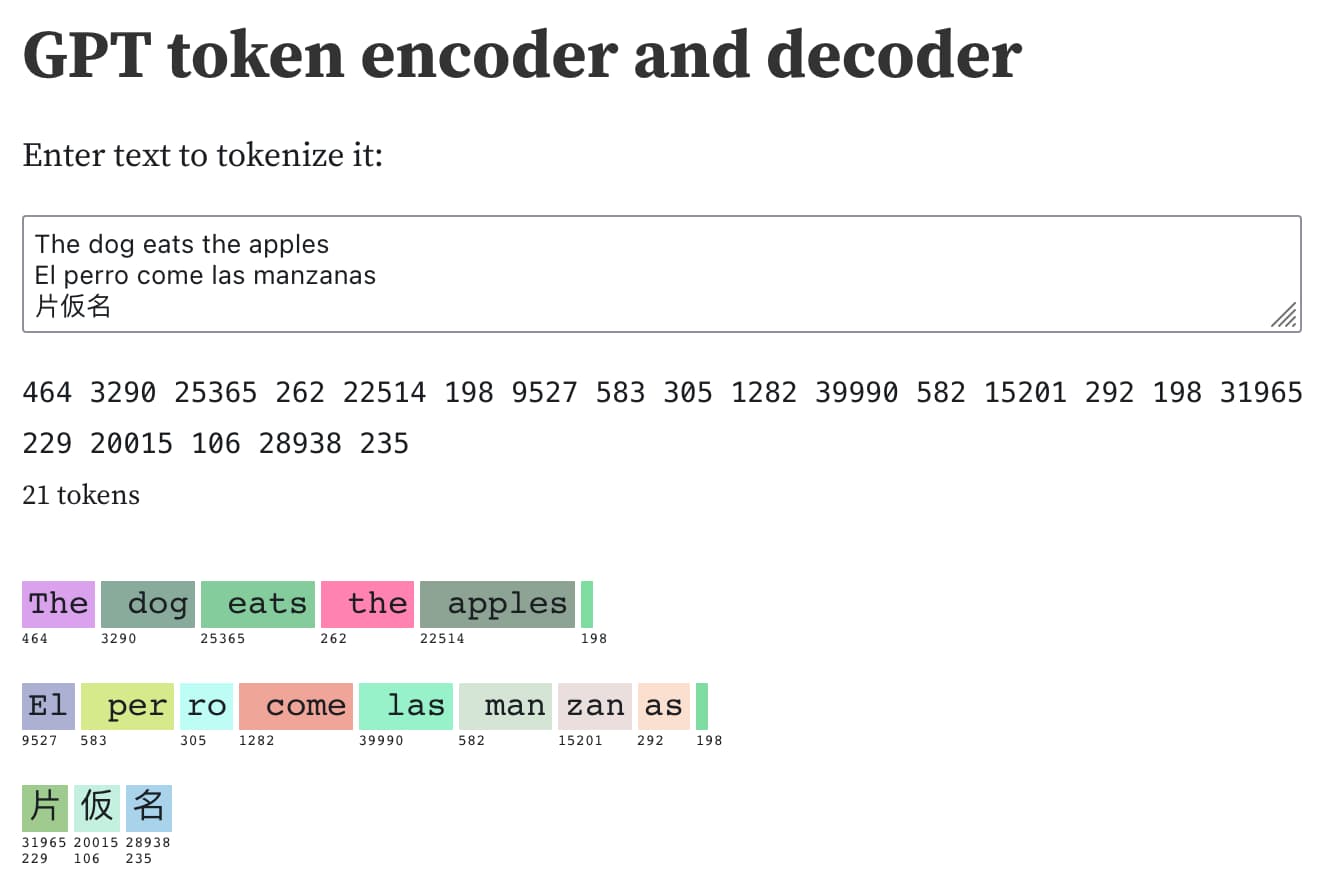
Large language models such as GPT-3/4, LLaMA and PaLM work in terms of tokens. They take text, convert it into tokens (integers), then predict which tokens should come next.
[... 1,575 words]Examples of weird GPT-4 behavior for the string “ davidjl”. GPT-4, when told to repeat or otherwise process the string “ davidjl” (note the leading space character), treats it as “jndl” or “jspb” or “JDL” instead. It turns out “ davidjl” has its own single token in the tokenizer: token ID 23282, presumably dating back to the GPT-2 days.
Riley Goodside refers to these as “glitch tokens”.
This token might refer to Reddit user davidjl123 who ranks top of the league for the old /r/counting subreddit, with 163,477 posts there which presumably ended up in older training data.
llm, ttok and strip-tags—CLI tools for working with ChatGPT and other LLMs
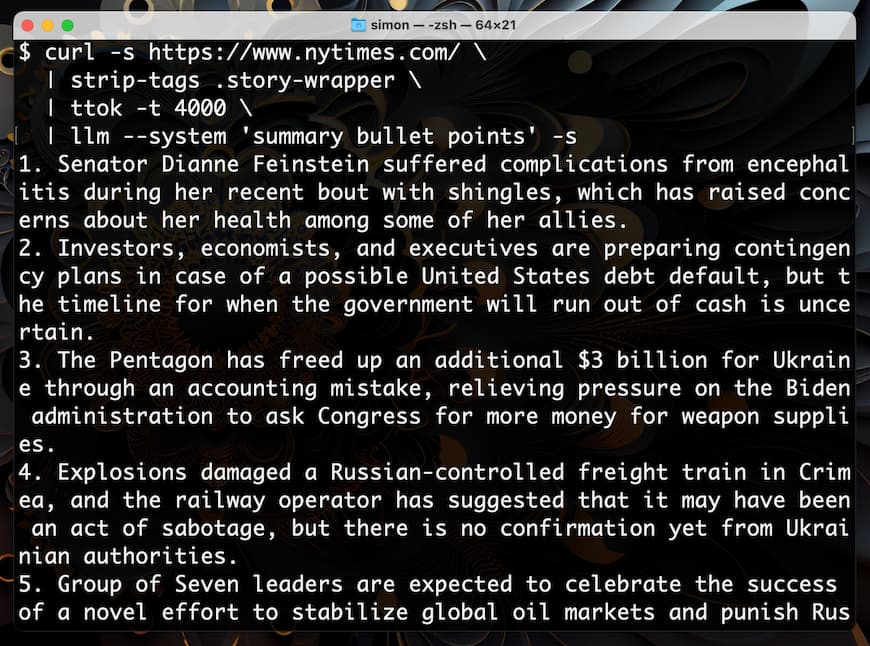
I’ve been building out a small suite of command-line tools for working with ChatGPT, GPT-4 and potentially other language models in the future.
[... 1,328 words]