18 posts tagged “nvidia”
2026
DiffusionGemma (via) Last May Google briefly released an experimental Gemini Diffusion model. I tried the preview at the time and recorded it running at 857 tokens/second. It was an exciting model, but Google made no further announcements about it.
That research has returned in the best possible way: as a new open weight (Apache 2 licensed) Gemma model, google/diffusiongemma-26B-A4B-it.
NVIDIA are currently hosting the model for free on their NIM cloud API. I used that API to generate this pelican, which took 4.4s (according to time uv run generate.py) to return 2,409 tokens - so at least 500 tokens/second.

Given how badly burned anyone who took Apple's 2024 WWDC Apple Intelligence announcements at face value was, I'm holding to a strict "I'll believe it when I see it" policy for everything they announced today.
The new Siri AI features do at least look feasible with today's technology, especially since Apple are licensing a custom Gemini-derived model that they can run on their own Private Cloud Compute.
It sounds like they'll be taking advantage of vision LLMs to extract information from the user's screen, which neatly sidesteps the need for every existing application to ship custom code in order to integrate with Apple Intelligence. Vision LLMs were a much less mature category in June 2024.
The new Core AI library looks like a good step in enabling developers to finally take full advantage of Apple's hardware for running their own models. It integrates with Meta's open source PyTorch ecosystem, using these Core AI PyTorch extensions:
Core AI PyTorch Extensions (
coreai-torch) is a Python package that bridges PyTorch and Core AI. You can use it to bring up an existing PyTorch model — exported as atorch.export.ExportedProgram— into a Core AIAIProgramready to run on Apple hardware, traversing the FX graph node-by-node and mapping ATen operators to Core AI operations.
You can install an iOS 27 Developer Beta today, which supposedly has the new features - but you then have to make it through a waiting list for access to the new Siri AI. Aaron Perris from MacRumors reports having made it off the waitlist so we may start seeing credible reports on how well Siri AI works in the very near future.
Update: These Private Cloud Compute Gemini models are running in Google Cloud, and using NVIDIA hardware. According to Expanding Private Cloud Compute on Apple's Security Research blog:
For the most demanding tasks, including agentic tool-use and complex reasoning, we worked with Google and NVIDIA to extend our PCC infrastructure to Google Cloud systems using NVIDIA GPUs, while maintaining Apple's powerful security and privacy protections. [...]
PCC on Google Cloud leverages many of the same architectural security patterns as PCC on Apple silicon to implement these layered protections: initial network data parsing for each request happens in a dedicated process within its own namespace, shared inference software is recycled with a short time-to-live duration, and attested keys are held in a separate, dedicated confidential VM isolated from external inputs. [...]
As with PCC on Apple silicon, all binaries will be published for public inspection.
2025
Inspired by this conversation on Hacker News I decided to upgrade MacWhisper to try out NVIDIA Parakeet and the new Automatic Speaker Recognition feature.
It appears to work really well! Here's the result against this 39.7MB m4a file from my Gemini 3 Pro write-up this morning:
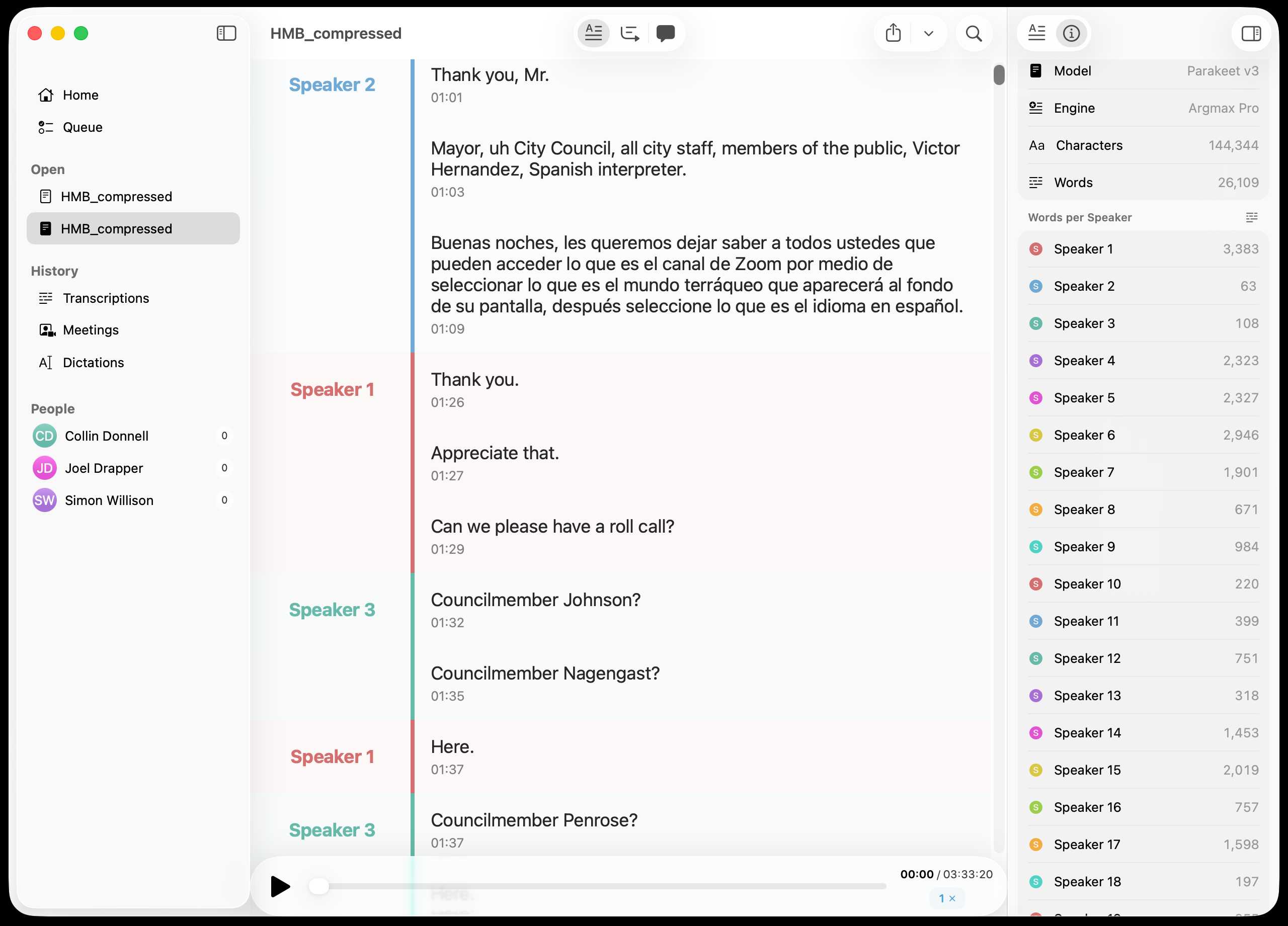
You can export the transcript with both timestamps and speaker names using the Share -> Segments > .json menu item:
Here's the resulting JSON.
parakeet-mlx. Neat MLX project by Senstella bringing NVIDIA's Parakeet ASR (Automatic Speech Recognition, like Whisper) model to to Apple's MLX framework.
It's packaged as a Python CLI tool, so you can run it like this:
uvx parakeet-mlx default_tc.mp3
The first time I ran this it downloaded a 2.5GB model file.
Once that was fetched it took 53 seconds to transcribe a 65MB 1hr 1m 28s podcast episode (this one) and produced this default_tc.srt file with a timestamped transcript of the audio I fed into it. The quality appears to be very high.
Using Codex CLI with gpt-oss:120b on an NVIDIA DGX Spark via Tailscale. Inspired by a YouTube comment I wrote up how I run OpenAI's Codex CLI coding agent against the gpt-oss:120b model running in Ollama on my NVIDIA DGX Spark via a Tailscale network.
It takes a little bit of work to configure but the result is I can now use Codex CLI on my laptop anywhere in the world against a self-hosted model.
I used it to build this space invaders clone.
Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code

DeepSeek released a new model yesterday: DeepSeek-OCR, a 6.6GB model fine-tuned specifically for OCR. They released it as model weights that run using PyTorch and CUDA. I got it running on the NVIDIA Spark by having Claude Code effectively brute force the challenge of getting it working on that particular hardware.
[... 1,971 words]NVIDIA DGX Spark + Apple Mac Studio = 4x Faster LLM Inference with EXO 1.0 (via) EXO Labs wired a 256GB M3 Ultra Mac Studio up to an NVIDIA DGX Spark and got a 2.8x performance boost serving Llama-3.1 8B (FP16) with an 8,192 token prompt.
Their detailed explanation taught me a lot about LLM performance.
There are two key steps in executing a prompt. The first is the prefill phase that reads the incoming prompt and builds a KV cache for each of the transformer layers in the model. This is compute-bound as it needs to process every token in the input and perform large matrix multiplications across all of the layers to initialize the model's internal state.
Performance in the prefill stage influences TTFT - time‑to‑first‑token.
The second step is the decode phase, which generates the output one token at a time. This part is limited by memory bandwidth - there's less arithmetic, but each token needs to consider the entire KV cache.
Decode performance influences TPS - tokens per second.
EXO noted that the Spark has 100 TFLOPS but only 273GB/s of memory bandwidth, making it a better fit for prefill. The M3 Ultra has 26 TFLOPS but 819GB/s of memory bandwidth, making it ideal for the decode phase.
They run prefill on the Spark, streaming the KV cache to the Mac over 10Gb Ethernet. They can start streaming earlier layers while the later layers are still being calculated. Then the Mac runs the decode phase, returning tokens faster than if the Spark had run the full process end-to-end.
NVIDIA DGX Spark: great hardware, early days for the ecosystem

NVIDIA sent me a preview unit of their new DGX Spark desktop “AI supercomputer”. I’ve never had hardware to review before! You can consider this my first ever sponsored post if you like, but they did not pay me any cash and aside from an embargo date they did not request (nor would I grant) any editorial input into what I write about the device.
[... 1,846 words]One analyst recently speculated (via Ed Conard) that, based on Nvidia's latest datacenter sales figures, AI capex may be ~2% of US GDP in 2025, given a standard multiplier. [...]
Capital expenditures on AI data centers is likely around 20% of the peak spending on railroads, as a percentage of GDP, and it is still rising quickly. [...]
Regardless of what one thinks about the merits of AI or explosive datacenter expansion, the scale and pace of capital deployment into a rapidly depreciating technology is remarkable. These are not railroads—we aren’t building century-long infrastructure. AI datacenters are short-lived, asset-intensive facilities riding declining-cost technology curves, requiring frequent hardware replacement to preserve margins.
— Paul Kedrosky, Honey, AI Capex is Eating the Economy
H100s were prohibited by the chip ban, but not H800s. Everyone assumed that training leading edge models required more interchip memory bandwidth, but that is exactly what DeepSeek optimized both their model structure and infrastructure around.
Again, just to emphasize this point, all of the decisions DeepSeek made in the design of this model only make sense if you are constrained to the H800; if DeepSeek had access to H100s, they probably would have used a larger training cluster with much fewer optimizations specifically focused on overcoming the lack of bandwidth.
— Ben Thompson, DeepSeek FAQ
The impact of competition and DeepSeek on Nvidia (via) Long, excellent piece by Jeffrey Emanuel capturing the current state of the AI/LLM industry. The original title is "The Short Case for Nvidia Stock" - I'm using the Hacker News alternative title here, but even that I feel under-sells this essay.
Jeffrey has a rare combination of experience in both computer science and investment analysis. He combines both worlds here, evaluating NVIDIA's challenges by providing deep insight into a whole host of relevant and interesting topics.
As Jeffrey describes it, NVIDA's moat has four components: high-quality Linux drivers, CUDA as an industry standard, the fast GPU interconnect technology they acquired from Mellanox in 2019 and the flywheel effect where they can invest their enormous profits (75-90% margin in some cases!) into more R&D.
Each of these is under threat.
Technologies like MLX, Triton and JAX are undermining the CUDA advantage by making it easier for ML developers to target multiple backends - plus LLMs themselves are getting capable enough to help port things to alternative architectures.
GPU interconnect helps multiple GPUs work together on tasks like model training. Companies like Cerebras are developing enormous chips that can get way more done on a single chip.
Those 75-90% margins provide a huge incentive for other companies to catch up - including the customers who spend the most on NVIDIA at the moment - Microsoft, Amazon, Meta, Google, Apple - all of whom have their own internal silicon projects:
Now, it's no secret that there is a strong power law distribution of Nvidia's hyper-scaler customer base, with the top handful of customers representing the lion's share of high-margin revenue. How should one think about the future of this business when literally every single one of these VIP customers is building their own custom chips specifically for AI training and inference?
The real joy of this article is the way it describes technical details of modern LLMs in a relatively accessible manner. I love this description of the inference-scaling tricks used by O1 and R1, compared to traditional transformers:
Basically, the way Transformers work in terms of predicting the next token at each step is that, if they start out on a bad "path" in their initial response, they become almost like a prevaricating child who tries to spin a yarn about why they are actually correct, even if they should have realized mid-stream using common sense that what they are saying couldn't possibly be correct.
Because the models are always seeking to be internally consistent and to have each successive generated token flow naturally from the preceding tokens and context, it's very hard for them to course-correct and backtrack. By breaking the inference process into what is effectively many intermediate stages, they can try lots of different things and see what's working and keep trying to course-correct and try other approaches until they can reach a fairly high threshold of confidence that they aren't talking nonsense.
The last quarter of the article talks about the seismic waves rocking the industry right now caused by DeepSeek v3 and R1. v3 remains the top-ranked open weights model, despite being around 45x more efficient in training than its competition: bad news if you are selling GPUs! R1 represents another huge breakthrough in efficiency both for training and for inference - the DeepSeek R1 API is currently 27x cheaper than OpenAI's o1, for a similar level of quality.
Jeffrey summarized some of the key ideas from the v3 paper like this:
A major innovation is their sophisticated mixed-precision training framework that lets them use 8-bit floating point numbers (FP8) throughout the entire training process. [...]
DeepSeek cracked this problem by developing a clever system that breaks numbers into small tiles for activations and blocks for weights, and strategically uses high-precision calculations at key points in the network. Unlike other labs that train in high precision and then compress later (losing some quality in the process), DeepSeek's native FP8 approach means they get the massive memory savings without compromising performance. When you're training across thousands of GPUs, this dramatic reduction in memory requirements per GPU translates into needing far fewer GPUs overall.
Then for R1:
With R1, DeepSeek essentially cracked one of the holy grails of AI: getting models to reason step-by-step without relying on massive supervised datasets. Their DeepSeek-R1-Zero experiment showed something remarkable: using pure reinforcement learning with carefully crafted reward functions, they managed to get models to develop sophisticated reasoning capabilities completely autonomously. This wasn't just about solving problems— the model organically learned to generate long chains of thought, self-verify its work, and allocate more computation time to harder problems.
The technical breakthrough here was their novel approach to reward modeling. Rather than using complex neural reward models that can lead to "reward hacking" (where the model finds bogus ways to boost their rewards that don't actually lead to better real-world model performance), they developed a clever rule-based system that combines accuracy rewards (verifying final answers) with format rewards (encouraging structured thinking). This simpler approach turned out to be more robust and scalable than the process-based reward models that others have tried.
This article is packed with insights like that - it's worth spending the time absorbing the whole thing.
Generative AI – The Power and the Glory (via) Michael Liebreich's epic report for BloombergNEF on the current state of play with regards to generative AI, energy usage and data center growth.
I learned so much from reading this. If you're at all interested in the energy impact of the latest wave of AI tools I recommend spending some time with this article.
Just a few of the points that stood out to me:
- This isn't the first time a leap in data center power use has been predicted. In 2007 the EPA predicted data center energy usage would double: it didn't, thanks to efficiency gains from better servers and the shift from in-house to cloud hosting. In 2017 the WEF predicted cryptocurrency could consume all the world's electric power by 2020, which was cut short by the first crypto bubble burst. Is this time different? Maybe.
- Michael re-iterates (Sequoia) David Cahn's $600B question, pointing out that if the anticipated infrastructure spend on AI requires $600bn in annual revenue that means 1 billion people will need to spend $600/year or 100 million intensive users will need to spend $6,000/year.
- Existing data centers often have a power capacity of less than 10MW, but new AI-training focused data centers tend to be in the 75-150MW range, due to the need to colocate vast numbers of GPUs for efficient communication between them - these can at least be located anywhere in the world. Inference is a lot less demanding as the GPUs don't need to collaborate in the same way, but it needs to be close to human population centers to provide low latency responses.
- NVIDIA are claiming huge efficiency gains. "Nvidia claims to have delivered a 45,000 improvement in energy efficiency per token (a unit of data processed by AI models) over the past eight years" - and that "training a 1.8 trillion-parameter model using Blackwell GPUs, which only required 4MW, versus 15MW using the previous Hopper architecture".
- Michael's own global estimate is "45GW of additional demand by 2030", which he points out is "equivalent to one third of the power demand from the world’s aluminum smelters". But much of this demand needs to be local, which makes things a lot more challenging, especially given the need to integrate with the existing grid.
- Google, Microsoft, Meta and Amazon all have net-zero emission targets which they take very seriously, making them "some of the most significant corporate purchasers of renewable energy in the world". This helps explain why they're taking very real interest in nuclear power.
-
Elon's 100,000-GPU data center in Memphis currently runs on gas:
When Elon Musk rushed to get x.AI's Memphis Supercluster up and running in record time, he brought in 14 mobile natural gas-powered generators, each of them generating 2.5MW. It seems they do not require an air quality permit, as long as they do not remain in the same location for more than 364 days.
-
Here's a reassuring statistic: "91% of all new power capacity added worldwide in 2023 was wind and solar".
There's so much more in there, I feel like I'm doing the article a disservice by attempting to extract just the points above.
Michael's conclusion is somewhat optimistic:
In the end, the tech titans will find out that the best way to power AI data centers is in the traditional way, by building the same generating technologies as are proving most cost effective for other users, connecting them to a robust and resilient grid, and working with local communities. [...]
When it comes to new technologies – be it SMRs, fusion, novel renewables or superconducting transmission lines – it is a blessing to have some cash-rich, technologically advanced, risk-tolerant players creating demand, which has for decades been missing in low-growth developed world power markets.
(BloombergNEF is an energy research group acquired by Bloomberg in 2009, originally founded by Michael as New Energy Finance in 2004.)
2024
Leaked Documents Show Nvidia Scraping ‘A Human Lifetime’ of Videos Per Day to Train AI.
Samantha Cole at 404 Media reports on a huge leak of internal NVIDIA communications - mainly from a Slack channel - revealing details of how they have been collecting video training data for a new video foundation model called Cosmos. The data is mostly from YouTube, downloaded via yt-dlp using a rotating set of AWS IP addresses and consisting of millions (maybe even hundreds of millions) of videos.
The fact that companies scrape unlicensed data to train models isn't at all surprising. This article still provides a fascinating insight into what model training teams care about, with details like this from a project update via email:
As we measure against our desired distribution focus for the next week remains on cinematic, drone footage, egocentric, some travel and nature.
Or this from Slack:
Movies are actually a good source of data to get gaming-like 3D consistency and fictional content but much higher quality.
My intuition here is that the backlash against scraped video data will be even more intense than for static images used to train generative image models. Video is generally more expensive to create, and video creators (such as Marques Brownlee / MKBHD, who is mentioned in a Slack message here as a potential source of "tech product neviews - super high quality") have a lot of influence.
There was considerable uproar a few weeks ago over this story about training against just captions scraped from YouTube, and now we have a much bigger story involving the actual video content itself.
Our estimate of OpenAI’s $4 billion in inference costs comes from a person with knowledge of the cluster of servers OpenAI rents from Microsoft. That cluster has the equivalent of 350,000 Nvidia A100 chips, this person said. About 290,000 of those chips, or more than 80% of the cluster, were powering ChartGPT, this person said.
Apple, Nvidia, Anthropic Used Thousands of Swiped YouTube Videos to Train AI. This article has been getting a lot of attention over the past couple of days.
The story itself is nothing new: the Pile is four years old now, and has been widely used for training LLMs since before anyone even cared what an LLM was. It turns out one of the components of the Pile is a set of ~170,000 YouTube video captions (just the captions, not the actual video) and this story by Annie Gilbertson and Alex Reisner highlights that and interviews some of the creators who were included in the data, as well as providing a search tool for seeing if a specific creator has content that was included.
What's notable is the response. Marques Brownlee (19m subscribers) posted a video about it. Abigail Thorn (Philosophy Tube, 1.57m subscribers) tweeted this:
Very sad to have to say this - an AI company called EleutherAI stole tens of thousands of YouTube videos - including many of mine. I’m one of the creators Proof News spoke to. The stolen data was sold to Apple, Nvidia, and other companies to build AI
When I was told about this I lay on the floor and cried, it’s so violating, it made me want to quit writing forever. The reason I got back up was because I know my audience come to my show for real connection and ideas, not cheapfake AI garbage, and I know they’ll stay with me
Framing the data as "sold to Apple..." is a slight misrepresentation here - EleutherAI have been giving the Pile away for free since 2020. It's a good illustration of the emotional impact here though: many creative people do not want their work used in this way, especially without their permission.
It's interesting seeing how attitudes to this stuff change over time. Four years ago the fact that a bunch of academic researchers were sharing and training models using 170,000 YouTube subtitles would likely not have caught any attention at all. Today, people care!
GPUs Go Brrr (via) Fascinating, detailed low-level notes on how to get the most out of NVIDIA's H100 GPUs (currently selling for around $40,000 a piece) from the research team at Stanford who created FlashAttention, among other things.
The swizzled memory layouts are flat-out incorrectly documented, which took considerable time for us to figure out.
GPUs on Fly.io are available to everyone! We’ve been experimenting with GPUs on Fly for a few months for Datasette Cloud. They’re well documented and quite easy to use—any example Python code you find that uses NVIDIA CUDA stuff generally Just Works. Most interestingly of all, Fly GPUs can scale to zero—so while they cost $2.50/hr for a A100 40G (VRAM) and $3.50/hr for a A100 80G you can configure them to stop running when the machine runs out of things to do.
We’ve successfully used them to run Whisper and to experiment with running various Llama 2 LLMs as well.
To look forward to: “We are working on getting some lower-cost A10 GPUs in the next few weeks”.
2023
A Hackers’ Guide to Language Models. Jeremy Howard’s new 1.5 hour YouTube introduction to language models looks like a really useful place to catch up if you’re an experienced Python programmer looking to start experimenting with LLMs. He covers what they are and how they work, then shows how to build against the OpenAI API, build a Code Interpreter clone using OpenAI functions, run models from Hugging Face on your own machine (with NVIDIA cards or on a Mac) and finishes with a demo of fine-tuning a Llama 2 model to perform text-to-SQL using an open dataset.