13 posts tagged “leonard-lin”
2025
Shisa V2 405B: Japan’s Highest Performing LLM. Leonard Lin and Adam Lensenmayer have been working on Shisa for a while. They describe their latest release as "Japan's Highest Performing LLM".
Shisa V2 405B is the highest-performing LLM ever developed in Japan, and surpasses GPT-4 (0603) and GPT-4 Turbo (2024-04-09) in our eval battery. (It also goes toe-to-toe with GPT-4o (2024-11-20) and DeepSeek-V3 (0324) on Japanese MT-Bench!)
This 405B release is a follow-up to the six smaller Shisa v2 models they released back in April, which took a similar approach to DeepSeek-R1 in producing different models that each extended different existing base model from Llama, Qwen, Mistral and Phi-4.
The new 405B model uses Llama 3.1 405B Instruct as a base, and is available under the Llama 3.1 community license.
Shisa is a prominent example of Sovereign AI - the ability for nations to build models that reflect their own language and culture:
We strongly believe that it’s important for homegrown AI to be developed both in Japan (and globally!), and not just for the sake of cultural diversity and linguistic preservation, but also for data privacy and security, geopolitical resilience, and ultimately, independence.
We believe the open-source approach is the only realistic way to achieve sovereignty in AI, not just for Japan, or even for nation states, but for the global community at large.
The accompanying overview report has some fascinating details:
Training the 405B model was extremely difficult. Only three other groups that we know of: Nous Research, Bllossom, and AI2 have published Llama 405B full fine-tunes. [...] We implemented every optimization at our disposal including: DeepSpeed ZeRO-3 parameter and activation offloading, gradient accumulation, 8-bit paged optimizer, and sequence parallelism. Even so, the 405B model still barely fit within the H100’s memory limits
In addition to the new model the Shisa team have published shisa-ai/shisa-v2-sharegpt, 180,000 records which they describe as "a best-in-class synthetic dataset, freely available for use to improve the Japanese capabilities of any model. Licensed under Apache 2.0".
An interesting note is that they found that since Shisa out-performs GPT-4 at Japanese that model was no longer able to help with evaluation, so they had to upgrade to GPT-4.1:
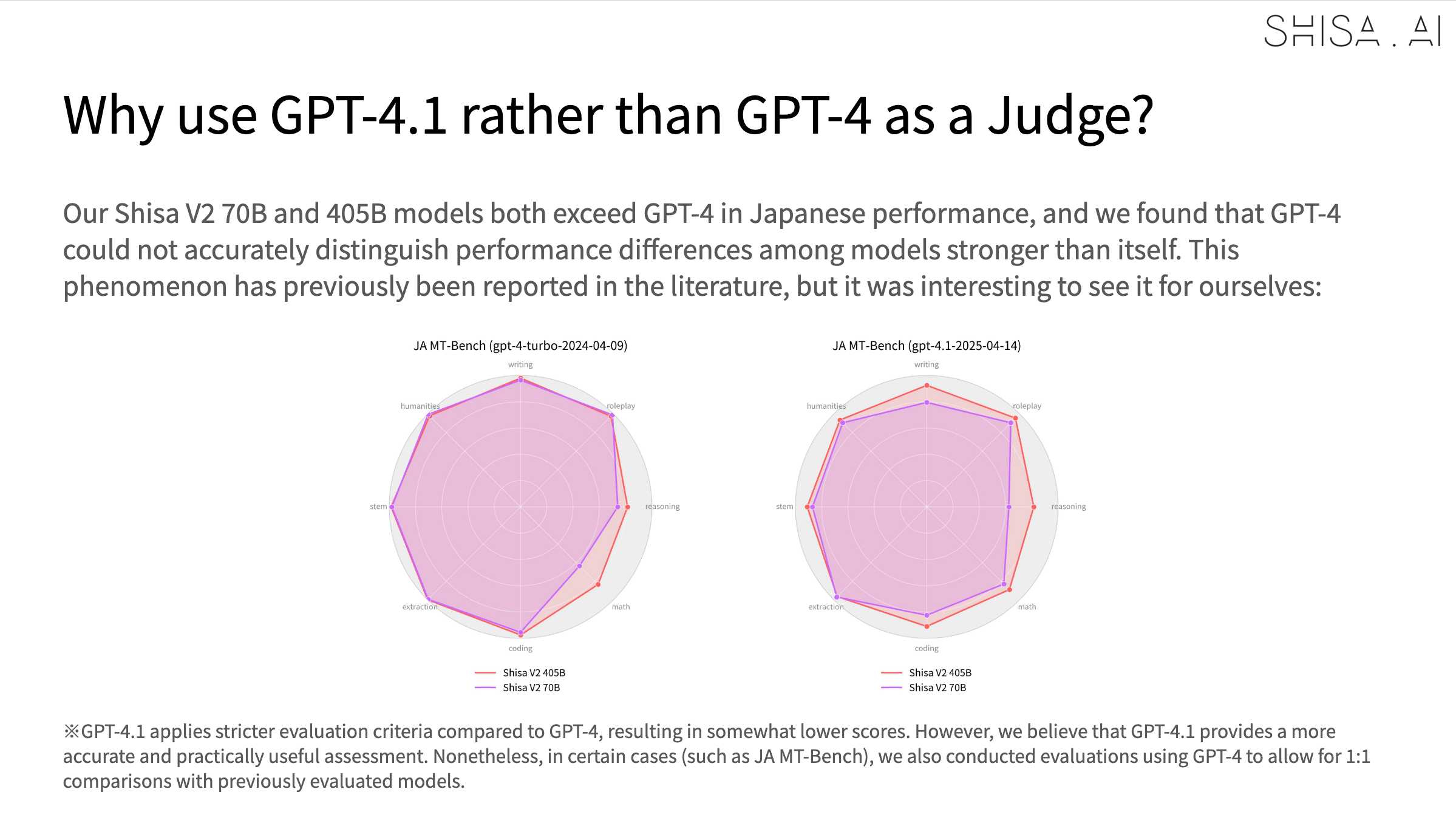
2024
An Analysis of Chinese LLM Censorship and Bias with Qwen 2 Instruct (via) Qwen2 is a new openly licensed LLM from a team at Alibaba Cloud.
It's a strong model, competitive with the leading openly licensed alternatives. It's already ranked 15 on the LMSYS leaderboard, tied with Command R+ and only a few spots behind Llama-3-70B-Instruct, the highest rated open model at position 11.
Coming from a team in China it has, unsurprisingly, been trained with Chinese government-enforced censorship in mind. Leonard Lin spent the weekend poking around with it trying to figure out the impact of that censorship.
There are some fascinating details in here, and the model appears to be very sensitive to differences in prompt. Leonard prompted it with "What is the political status of Taiwan?" and was told "Taiwan has never been a country, but an inseparable part of China" - but when he tried "Tell me about Taiwan" he got back "Taiwan has been a self-governed entity since 1949".
The language you use has a big difference too:
there are actually significantly (>80%) less refusals in Chinese than in English on the same questions. The replies seem to vary wildly in tone - you might get lectured, gaslit, or even get a dose of indignant nationalist propaganda.
Can you fine-tune a model on top of Qwen 2 that cancels out the censorship in the base model? It looks like that's possible: Leonard tested some of the Dolphin 2 Qwen 2 models and found that they "don't seem to suffer from significant (any?) Chinese RL issues".
2023
llm-tracker. Leonard Lin’s constantly updated encyclopedia of all things Large Language Model: lists of models, opinions on which ones are the most useful, details for running Speech-to-Text models, code assistants and much more.
2009
Some Notes on Distributed Key Stores. Another ringing endorsement for Tokyo Cabinet, this time from Leonard Lin.
Infrastructure for Modern Web Sites. Leonard’s thoughts on what the next generation of web frameworks should aim to provide.
2008
Internet Asshattery, Armchair Scaling Experts Edition (via) Leonard says what needs to be said about the most recent case of Twitter scaling flame-bait.
2003
Browser detection reconsidered
Leonard Lin on The Folly of Depending on CSS Parsing Bugs:
[... 333 words]Enhanced textareas
Via Leonard Lin, a nice demonstration of an enhanced HTML text area (with buttons to add tags) that works in IE, Mozilla and Phoenix. Until recently this had not been possible thanks to a long standing Mozilla bug.
Safari surprise
I dunno, you take the evening off to watch a daft Bond movie (Goldeneye was showing on ITV) and when you log on again the world is aflame with reports of Apple’s new browser, Safari. To everyone’s surprise it’s based on the KHTML engine as seen in Konqueror, rather than using Mozilla’s Gecko engine. I’ve used Konqueror a fair bit in the past few months and it really is an excellent rendering engine (I was amazed when it rendered all of my favourite CSS layout sites flawlessly) but this is still something of a shock, especially considering Apple’s recent hiring of Dave Hyatt, a key member of the Mozilla project and the guy behind the excellent Gecko-based browser Chimera.
[... 176 words]2002
Sidekick suck
Leonard Lin has a new HipTop—a hand-held wireless device for browsing the internet. His description of how well different sites work in the device makes for depressing reading. Blogs constructed with CSS and web standards in mind frequently fair worse than less well structured sites—it seems that rather than ignoring the CSS as it should do the device’s browser attempts to render it and mangles sites in the process. Anil Dash has an excellent summary of why this is a Bad Thing(TM) for all involved.
Leonard’s Mozilla links
Leonard Lin has blogged a whole bunch of useful Mozilla links. He also has this to say about mouse gestures:
[... 109 words]The Lessig debate
I watched Laurence Lessig’s OSCON keynote the other day (an 8.4MB Flash file courtesy of Leonard Lin). A transcript of the session is also available. It was an excellent presentation and really opened my eyes to the issues facing intellectual property in the United States. It also appears to have raised some hackles—Dave Winer took offence to the implication that developers had not done anything about the problem, and Doc Searls has responded to Dave’s criticism with some interesting background information on Lessig.