15 posts tagged “llm-performance”
Making LLMs fast.
2026
We’ve made GPT-5.3-Codex-Spark about 30% faster. It is now serving at over 1200 tokens per second.
— Thibault Sottiaux, OpenAI
Taalas serves Llama 3.1 8B at 17,000 tokens/second (via) This new Canadian hardware startup just announced their first product - a custom hardware implementation of the Llama 3.1 8B model (from July 2024) that can run at a staggering 17,000 tokens/second.
I was going to include a video of their demo but it's so fast it would look more like a screenshot. You can try it out at chatjimmy.ai.
They describe their Silicon Llama as “aggressively quantized, combining 3-bit and 6-bit parameters.” Their next generation will use 4-bit - presumably they have quite a long lead time for baking out new models!
Introducing GPT‑5.3‑Codex‑Spark. OpenAI announced a partnership with Cerebras on January 14th. Four weeks later they're already launching the first integration, "an ultra-fast model for real-time coding in Codex".
Despite being named GPT-5.3-Codex-Spark it's not purely an accelerated alternative to GPT-5.3-Codex - the blog post calls it "a smaller version of GPT‑5.3-Codex" and clarifies that "at launch, Codex-Spark has a 128k context window and is text-only."
I had some preview access to this model and I can confirm that it's significantly faster than their other models.
Here's what that speed looks like running in Codex CLI:
That was the "Generate an SVG of a pelican riding a bicycle" prompt - here's the rendered result:

Compare that to the speed of regular GPT-5.3 Codex medium:
Significantly slower, but the pelican is a lot better:

What's interesting about this model isn't the quality though, it's the speed. When a model responds this fast you can stay in flow state and iterate with the model much more productively.
I showed a demo of Cerebras running Llama 3.1 70 B at 2,000 tokens/second against Val Town back in October 2024. OpenAI claim 1,000 tokens/second for their new model, and I expect it will prove to be a ferociously useful partner for hands-on iterative coding sessions.
It's not yet clear what the pricing will look like for this new model.
Claude: Speed up responses with fast mode.
New "research preview" from Anthropic today: you can now access a faster version of their frontier model Claude Opus 4.6 by typing /fast in Claude Code... but at a cost that's 6x the normal price.
Opus is usually $5/million input and $25/million output. The new fast mode is $30/million input and $150/million output!
There's a 50% discount until the end of February 16th, so only a 3x multiple (!) before then.
How much faster is it? The linked documentation doesn't say, but on Twitter Claude say:
Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
We’re now making it available as an early experiment via Claude Code and our API.
Claude Opus 4.5 had a context limit of 200,000 tokens. 4.6 has an option to increase that to 1,000,000 at 2x the input price ($10/m) and 1.5x the output price ($37.50/m) once your input exceeds 200,000 tokens. These multiples hold for fast mode too, so after Feb 16th you'll be able to pay a hefty $60/m input and $225/m output for Anthropic's fastest best model.
2025
Introducing SWE-1.5: Our Fast Agent Model (via) Here's the second fast coding model released by a coding agent IDE in the same day - the first was Composer-1 by Cursor. This time it's Windsurf releasing SWE-1.5:
Today we’re releasing SWE-1.5, the latest in our family of models optimized for software engineering. It is a frontier-size model with hundreds of billions of parameters that achieves near-SOTA coding performance. It also sets a new standard for speed: we partnered with Cerebras to serve it at up to 950 tok/s – 6x faster than Haiku 4.5 and 13x faster than Sonnet 4.5.
Like Composer-1 it's only available via their editor, no separate API yet. Also like Composer-1 they don't appear willing to share details of the "leading open-source base model" they based their new model on.
I asked it to generate an SVG of a pelican riding a bicycle and got this:

This one felt really fast. Partnering with Cerebras for inference is a very smart move.
They share a lot of details about their training process in the post:
SWE-1.5 is trained on our state-of-the-art cluster of thousands of GB200 NVL72 chips. We believe SWE-1.5 may be the first public production model trained on the new GB200 generation. [...]
Our RL rollouts require high-fidelity environments with code execution and even web browsing. To achieve this, we leveraged our VM hypervisor
otterlinkthat allows us to scale Devin to tens of thousands of concurrent machines (learn more about blockdiff). This enabled us to smoothly support very high concurrency and ensure the training environment is aligned with our Devin production environments.
That's another similarity to Cursor's Composer-1! Cursor talked about how they ran "hundreds of thousands of concurrent sandboxed coding environments in the cloud" in their description of their RL training as well.
This is a notable trend: if you want to build a really great agentic coding tool there's clearly a lot to be said for using reinforcement learning to fine-tune a model against your own custom set of tools using large numbers of sandboxed simulated coding environments as part of that process.
Update: I think it's built on GLM.
Composer: Building a fast frontier model with RL (via) Cursor released Cursor 2.0 today, with a refreshed UI focused on agentic coding (and running agents in parallel) and a new model that's unique to Cursor called Composer 1.
As far as I can tell there's no way to call the model directly via an API, so I fired up "Ask" mode in Cursor's chat side panel and asked it to "Generate an SVG of a pelican riding a bicycle":
Here's the result:

The notable thing about Composer-1 is that it is designed to be fast. The pelican certainly came back quickly, and in their announcement they describe it as being "4x faster than similarly intelligent models".
It's interesting to see Cursor investing resources in training their own code-specific model - similar to GPT-5-Codex or Qwen3-Coder. From their post:
Composer is a mixture-of-experts (MoE) language model supporting long-context generation and understanding. It is specialized for software engineering through reinforcement learning (RL) in a diverse range of development environments. [...]
Efficient training of large MoE models requires significant investment into building infrastructure and systems research. We built custom training infrastructure leveraging PyTorch and Ray to power asynchronous reinforcement learning at scale. We natively train our models at low precision by combining our MXFP8 MoE kernels with expert parallelism and hybrid sharded data parallelism, allowing us to scale training to thousands of NVIDIA GPUs with minimal communication cost. [...]
During RL, we want our model to be able to call any tool in the Cursor Agent harness. These tools allow editing code, using semantic search, grepping strings, and running terminal commands. At our scale, teaching the model to effectively call these tools requires running hundreds of thousands of concurrent sandboxed coding environments in the cloud.
One detail that's notably absent from their description: did they train the model from scratch, or did they start with an existing open-weights model such as something from Qwen or GLM?
Cursor researcher Sasha Rush has been answering questions on Hacker News, but has so far been evasive in answering questions about the base model. When directly asked "is Composer a fine tune of an existing open source base model?" they replied:
Our primary focus is on RL post-training. We think that is the best way to get the model to be a strong interactive agent.
Sasha did confirm that rumors of an earlier Cursor preview model, Cheetah, being based on a model by xAI's Grok were "Straight up untrue."
Open weight LLMs exhibit inconsistent performance across providers
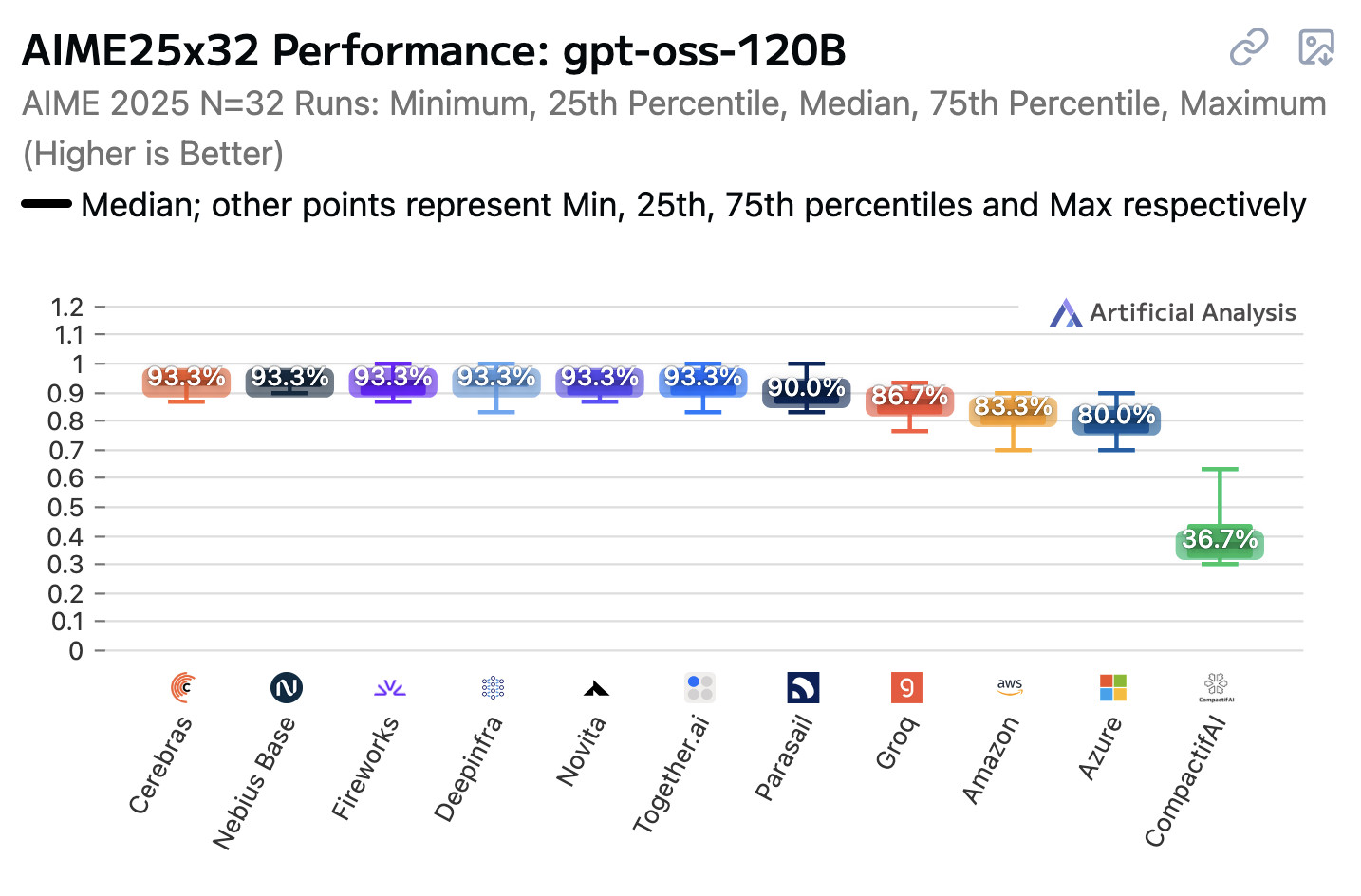
Artificial Analysis published a new benchmark the other day, this time focusing on how an individual model—OpenAI’s gpt-oss-120b—performs across different hosted providers.
[... 847 words]Two interesting examples of inference speed as a flagship feature of LLM services today.
First, Cerebras announced two new monthly plans for their extremely high speed hosted model service: Cerebras Code Pro ($50/month, 1,000 messages a day) and Cerebras Code Max ($200/month, 5,000/day). The model they are selling here is Qwen's Qwen3-Coder-480B-A35B-Instruct, likely the best available open weights coding model right now and one that was released just ten days ago. Ten days from model release to third-party subscription service feels like some kind of record.
Cerebras claim they can serve the model at an astonishing 2,000 tokens per second - four times the speed of Claude Sonnet 4 in their demo video.
Also today, Moonshot announced a new hosted version of their trillion parameter Kimi K2 model called kimi-k2-turbo-preview:
🆕 Say hello to kimi-k2-turbo-preview Same model. Same context. NOW 4× FASTER.
⚡️ From 10 tok/s to 40 tok/s.
💰 Limited-Time Launch Price (50% off until Sept 1)
- $0.30 / million input tokens (cache hit)
- $1.20 / million input tokens (cache miss)
- $5.00 / million output tokens
👉 Explore more: platform.moonshot.ai
This is twice the price of their regular model for 4x the speed (increasing to 4x the price in September). No details yet on how they achieved the speed-up.
I am interested to see how much market demand there is for faster performance like this. I've experimented with Cerebras in the past and found that the speed really does make iterating on code with live previews feel a whole lot more interactive.
Gemini Diffusion. Another of the announcements from Google I/O yesterday was Gemini Diffusion, Google's first LLM to use diffusion (similar to image models like Imagen and Stable Diffusion) in place of transformers.
Google describe it like this:
Traditional autoregressive language models generate text one word – or token – at a time. This sequential process can be slow, and limit the quality and coherence of the output.
Diffusion models work differently. Instead of predicting text directly, they learn to generate outputs by refining noise, step-by-step. This means they can iterate on a solution very quickly and error correct during the generation process. This helps them excel at tasks like editing, including in the context of math and code.
The key feature then is speed. I made it through the waitlist and tried it out just now and wow, they are not kidding about it being fast.
In this video I prompt it with "Build a simulated chat app" and it responds at 857 tokens/second, resulting in an interactive HTML+JavaScript page (embedded in the chat tool, Claude Artifacts style) within single digit seconds.
The performance feels similar to the Cerebras Coder tool, which used Cerebras to run Llama3.1-70b at around 2,000 tokens/second.
How good is the model? I've not seen any independent benchmarks yet, but Google's landing page for it promises "the performance of Gemini 2.0 Flash-Lite at 5x the speed" so presumably they think it's comparable to Gemini 2.0 Flash-Lite, one of their least expensive models.
Prior to this the only commercial grade diffusion model I've encountered is Inception Mercury back in February this year.
Update: a correction from synapsomorphy on Hacker News:
Diffusion isn't in place of transformers, it's in place of autoregression. Prior diffusion LLMs like Mercury still use a transformer, but there's no causal masking, so the entire input is processed all at once and the output generation is obviously different. I very strongly suspect this is also using a transformer.
nvtop provided this explanation:
Despite the name, diffusion LMs have little to do with image diffusion and are much closer to BERT and old good masked language modeling. Recall how BERT is trained:
- Take a full sentence ("the cat sat on the mat")
- Replace 15% of tokens with a [MASK] token ("the cat [MASK] on [MASK] mat")
- Make the Transformer predict tokens at masked positions. It does it in parallel, via a single inference step.
Now, diffusion LMs take this idea further. BERT can recover 15% of masked tokens ("noise"), but why stop here. Let's train a model to recover texts with 30%, 50%, 90%, 100% of masked tokens.
Once you've trained that, in order to generate something from scratch, you start by feeding the model all [MASK]s. It will generate you mostly gibberish, but you can take some tokens (let's say, 10%) at random positions and assume that these tokens are generated ("final"). Next, you run another iteration of inference, this time input having 90% of masks and 10% of "final" tokens. Again, you mark 10% of new tokens as final. Continue, and in 10 steps you'll have generated a whole sequence. This is a core idea behind diffusion language models. [...]
Cerebras brings instant inference to Mistral Le Chat. Mistral announced a major upgrade to their Le Chat web UI (their version of ChatGPT) a few days ago, and one of the signature features was performance.
It turns out that performance boost comes from hosting their model on Cerebras:
We are excited to bring our technology to Mistral – specifically the flagship 123B parameter Mistral Large 2 model. Using our Wafer Scale Engine technology, we achieve over 1,100 tokens per second on text queries.
Given Cerebras's so far unrivaled inference performance I'm surprised that no other AI lab has formed a partnership like this already.
2024
Cerebras Coder (via) Val Town founder Steve Krouse has been building demos on top of the Cerebras API that runs Llama3.1-70b at 2,000 tokens/second.
Having a capable LLM with that kind of performance turns out to be really interesting. Cerebras Coder is a demo that implements Claude Artifact-style on-demand JavaScript apps, and having it run at that speed means changes you request are visible within less than a second:
Steve's implementation (created with the help of Townie, the Val Town code assistant) demonstrates the simplest possible version of an iframe sandbox:
<iframe
srcDoc={code}
sandbox="allow-scripts allow-modals allow-forms allow-popups allow-same-origin allow-top-navigation allow-downloads allow-presentation allow-pointer-lock"
/>
Where code is populated by a setCode(...) call inside a React component.
The most interesting applications of LLMs continue to be where they operate in a tight loop with a human - this can make those review loops potentially much faster and more productive.
llm-cerebras. Cerebras (previously) provides Llama LLMs hosted on custom hardware at ferociously high speeds.
GitHub user irthomasthomas built an LLM plugin that works against their API - which is currently free, albeit with a rate limit of 30 requests per minute for their two models.
llm install llm-cerebras
llm keys set cerebras
# paste key here
llm -m cerebras-llama3.1-70b 'an epic tail of a walrus pirate'
Here's a video showing the speed of that prompt:
The other model is cerebras-llama3.1-8b.
Cerebras Inference: AI at Instant Speed (via) New hosted API for Llama running at absurdly high speeds: "1,800 tokens per second for Llama3.1 8B and 450 tokens per second for Llama3.1 70B".
How are they running so fast? Custom hardware. Their WSE-3 is 57x physically larger than an NVIDIA H100, and has 4 trillion transistors, 900,000 cores and 44GB of memory all on one enormous chip.
Their live chat demo just returned me a response at 1,833 tokens/second. Their API currently has a waitlist.
Introducing Llama-3-Groq-Tool-Use Models (via) New from Groq: two custom fine-tuned Llama 3 models specifically designed for tool use. Hugging Face model links:
Groq's own internal benchmarks put their 70B model at the top of the Berkeley Function-Calling Leaderboard with a score of 90.76 (and 89.06 for their 8B model, which would put it at #3). For comparison, Claude 3.5 Sonnet scores 90.18 and GPT-4-0124 scores 88.29.
The two new Groq models are also available through their screamingly-fast (fastest in the business?) API, running at 330 tokens/s and 1050 tokens/s respectively.
Here's the documentation on how to use tools through their API.
Fast groq-hosted LLMs vs browser jank (via) Groq is now serving LLMs such as Llama 3 so quickly that JavaScript which attempts to render Markdown strings on every new token can cause performance issues in browsers.
Taras Glek's solution was to move the rendering to a requestAnimationFrame() callback, effectively buffering the rendering to the fastest rate the browser can support.