6 posts tagged “ffmpeg”
2025
Feed a video to a vision LLM as a sequence of JPEG frames on the CLI (also LLM 0.25)

The new llm-video-frames plugin can turn a video file into a sequence of JPEG frames and feed them directly into a long context vision LLM such as GPT-4.1, even when that LLM doesn’t directly support video input. It depends on a plugin feature I added to LLM 0.25, which I released last night.
[... 1,600 words]2024
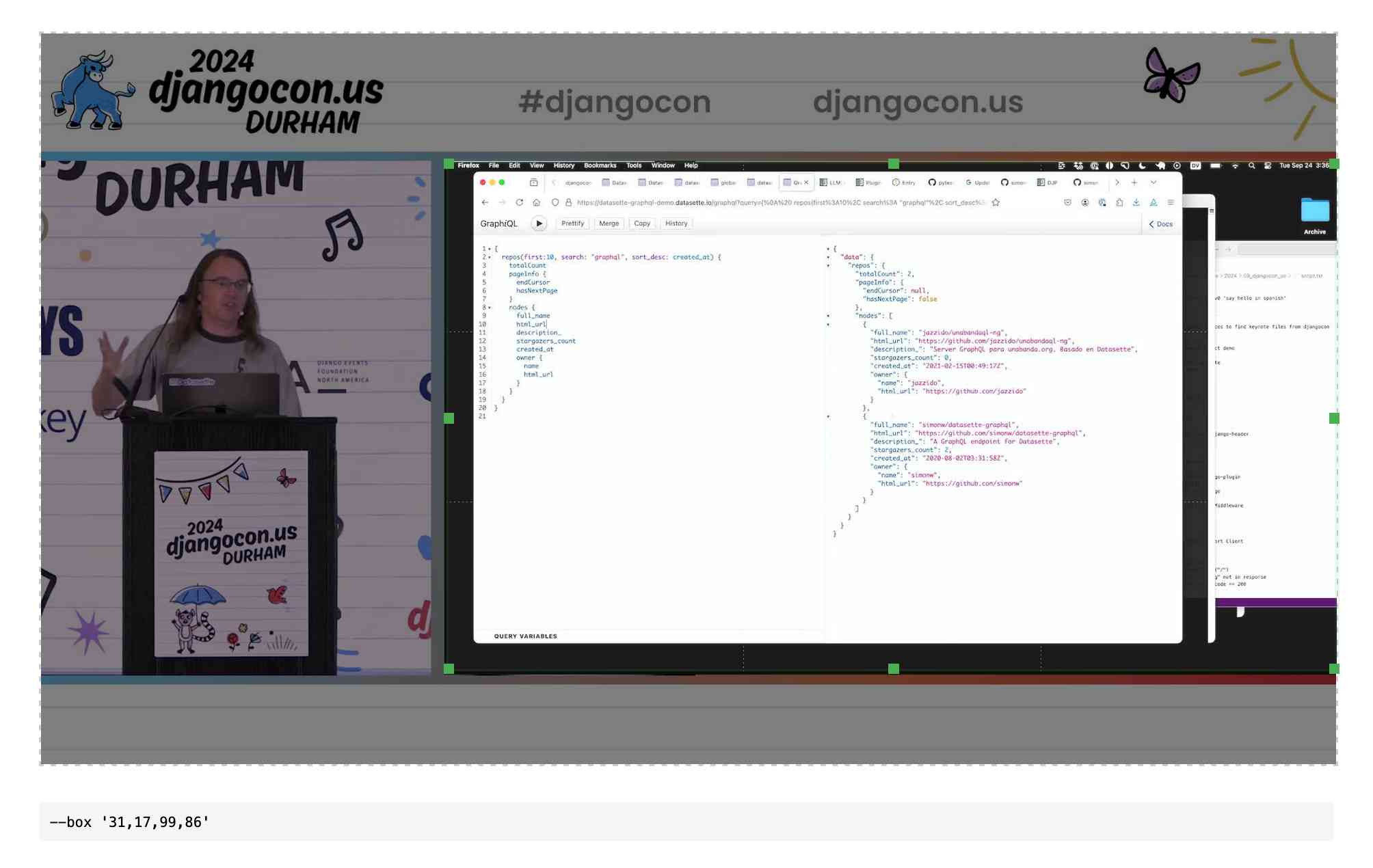
QuickTime video script to capture frames and bounding boxes. An update to an older TIL. I'm working on the write-up for my DjangoCon US talk on plugins and I found myself wanting to capture individual frames from the video in two formats: a full frame capture, and another that captured just the portion of the screen shared from my laptop.
I have a script for the former, so I got Claude to update my script to add support for one or more --box options, like this:
capture-bbox.sh ../output.mp4 --box '31,17,100,87' --box '0,0,50,50'
Open output.mp4 in QuickTime Player, run that script and then every time you hit a key in the terminal app it will capture three JPEGs from the current position in QuickTime Player - one for the whole screen and one each for the specified bounding box regions.
Those bounding box regions are percentages of the width and height of the image. I also got Claude to build me this interactive tool on top of cropperjs to help figure out those boxes:
llamafile v0.8.13 (and whisperfile)
(via)
The latest release of llamafile (previously) adds support for Gemma 2B (pre-bundled llamafiles available here), significant performance improvements and new support for the Whisper speech-to-text model, based on whisper.cpp, Georgi Gerganov's C++ implementation of Whisper that pre-dates his work on llama.cpp.
I got whisperfile working locally by first downloading the cross-platform executable attached to the GitHub release and then grabbing a whisper-tiny.en-q5_1.bin model from Hugging Face:
wget -O whisper-tiny.en-q5_1.bin \
https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-tiny.en-q5_1.bin
Then I ran chmod 755 whisperfile-0.8.13 and then executed it against an example .wav file like this:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f raven_poe_64kb.wav --no-prints
The --no-prints option suppresses the debug output, so you just get text that looks like this:
[00:00:00.000 --> 00:00:12.000] This is a LibraVox recording. All LibraVox recordings are in the public domain. For more information please visit LibraVox.org.
[00:00:12.000 --> 00:00:20.000] Today's reading The Raven by Edgar Allan Poe, read by Chris Scurringe.
[00:00:20.000 --> 00:00:40.000] Once upon a midnight dreary, while I pondered weak and weary, over many a quaint and curious volume of forgotten lore. While I nodded nearly napping, suddenly there came a tapping as of someone gently rapping, rapping at my chamber door.
There are quite a few undocumented options - to write out JSON to a file called transcript.json (example output):
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/raven_poe_64kb.wav --no-prints --output-json --output-file transcript
I had to convert my own audio recordings to 16kHz .wav files in order to use them with whisperfile. I used ffmpeg to do this:
ffmpeg -i runthrough-26-oct-2023.wav -ar 16000 /tmp/out.wav
Then I could transcribe that like so:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/out.wav --no-prints
Update: Justine says:
I've just uploaded new whisperfiles to Hugging Face which use miniaudio.h to automatically resample and convert your mp3/ogg/flac/wav files to the appropriate format.
With that whisper-tiny model this took just 11s to transcribe a 10m41s audio file!
I also tried the much larger Whisper Medium model - I chose to use the 539MB ggml-medium-q5_0.bin quantized version of that from huggingface.co/ggerganov/whisper.cpp:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints
This time it took 1m49s, using 761% of CPU according to Activity Monitor.
I tried adding --gpu auto to exercise the GPU on my M2 Max MacBook Pro:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints --gpu auto
That used just 16.9% of CPU and 93% of GPU according to Activity Monitor, and finished in 1m08s.
I tried this with the tiny model too but the performance difference there was imperceptible.
Tracking Fireworks Impact on Fourth of July AQI
(via)
Danny Page ran shot-scraper once per minute (using cron) against this Purple Air map of the Bay Area and turned the captured screenshots into an animation using ffmpeg. The result shows the impact of 4th of July fireworks on air quality between 7pm and 7am.
Announcing the Ladybird Browser Initiative (via) Andreas Kling's Ladybird is a really exciting project: a from-scratch implementation of a web browser, initially built as part of the Serenity OS project, which aims to provide a completely independent, open source and fully standards compliant browser.
Last month Andreas forked Ladybird away from Serenity, recognizing that the potential impact of the browser project on its own was greater than as a component of that project. Crucially, Serenity OS avoids any outside code - splitting out Ladybird allows Ladybird to add dependencies like libjpeg and ffmpeg. The Ladybird June update video talks through some of the dependencies they've been able to add since making that decision.
The new Ladybird Browser Initiative puts some financial weight behind the project: it's a US 501(c)(3) non-profit initially funded with $1m from GitHub co-founder Chris Chris Wanstrath. The money is going on engineers: Andreas says:
We are 4 full-time engineers today, and we'll be adding another 3 in the near future
Here's a 2m28s video from Chris introducing the new foundation and talking about why this project is worth supporting.
2007
Mass Video Conversion Using AWS. How to use S3, SQS, EC2, ffmpeg and some Python to bulk convert videos with Amazon Web Services.