20 posts tagged “algorithms”
2026
Sorting algorithms. Today in animated explanations built using Claude: I've always been a fan of animated demonstrations of sorting algorithms so I decided to spin some up on my phone using Claude Artifacts, then added Python's timsort algorithm, then a feature to run them all at once. Here's the full sequence of prompts:
Interactive animated demos of the most common sorting algorithms
This gave me bubble sort, selection sort, insertion sort, merge sort, quick sort, and heap sort.
Add timsort, look up details in a clone of python/cpython from GitHub
Let's add Python's Timsort! Regular Claude chat can clone repos from GitHub these days. In the transcript you can see it clone the repo and then consult Objects/listsort.txt and Objects/listobject.c. (I should note that when I asked GPT-5.4 Thinking to review Claude's implementation it picked holes in it and said the code "is a simplified, Timsort-inspired adaptive mergesort".)
I don't like the dark color scheme on the buttons, do better
Also add a "run all" button which shows smaller animated charts for every algorithm at once in a grid and runs them all at the same time
It came up with a color scheme I liked better, "do better" is a fun prompt, and now the "Run all" button produces this effect:
Unicode Explorer using binary search over fetch() HTTP range requests. Here's a little prototype I built this morning from my phone as an experiment in HTTP range requests, and a general example of using LLMs to satisfy curiosity.
I've been collecting HTTP range tricks for a while now, and I decided it would be fun to build something with them myself that used binary search against a large file to do something useful.
So I brainstormed with Claude. The challenge was coming up with a use case for binary search where the data could be naturally sorted in a way that would benefit from binary search.
One of Claude's suggestions was looking up information about unicode codepoints, which means searching through many MBs of metadata.
I had Claude write me a spec to feed to Claude Code - visible here - then kicked off an asynchronous research project with Claude Code for web against my simonw/research repo to turn that into working code.
Here's the resulting report and code. One interesting thing I learned is that Range request tricks aren't compatible with HTTP compression because they mess with the byte offset calculations. I added 'Accept-Encoding': 'identity' to the fetch() calls but this isn't actually necessary because Cloudflare and other CDNs automatically skip compression if a content-range header is present.
I deployed the result to my tools.simonwillison.net site, after first tweaking it to query the data via range requests against a CORS-enabled 76.6MB file in an S3 bucket fronted by Cloudflare.
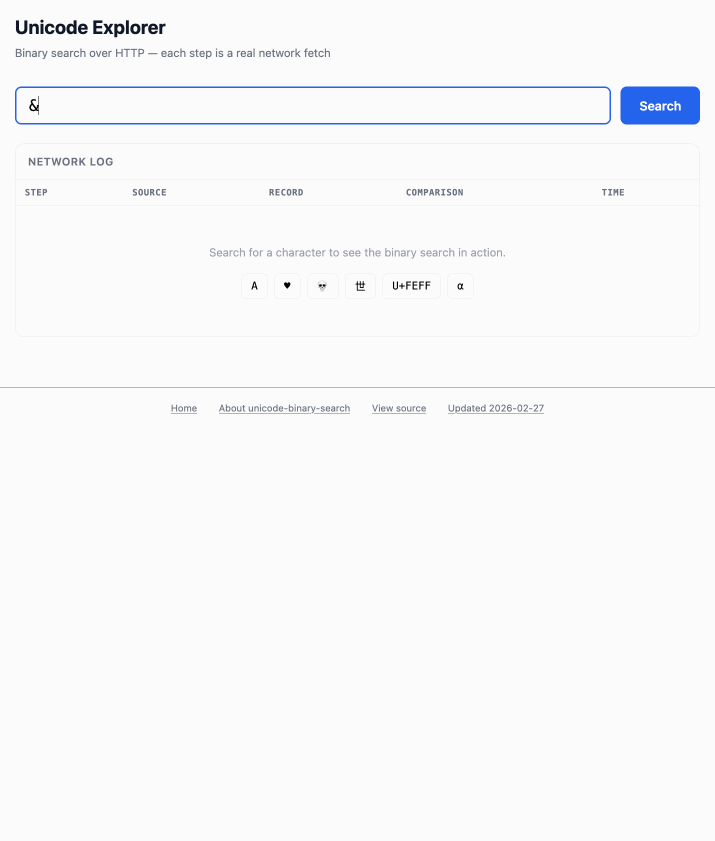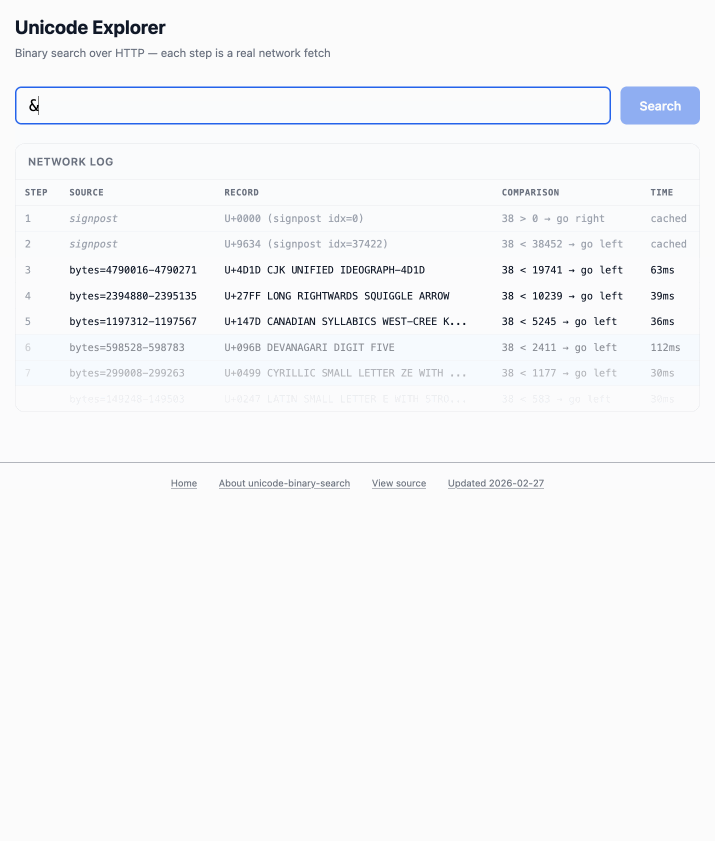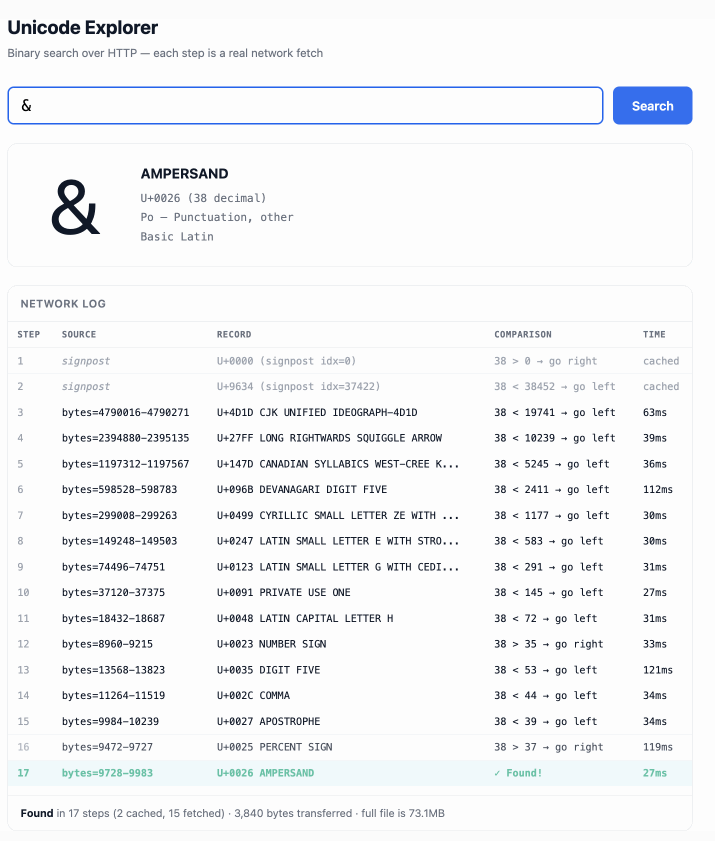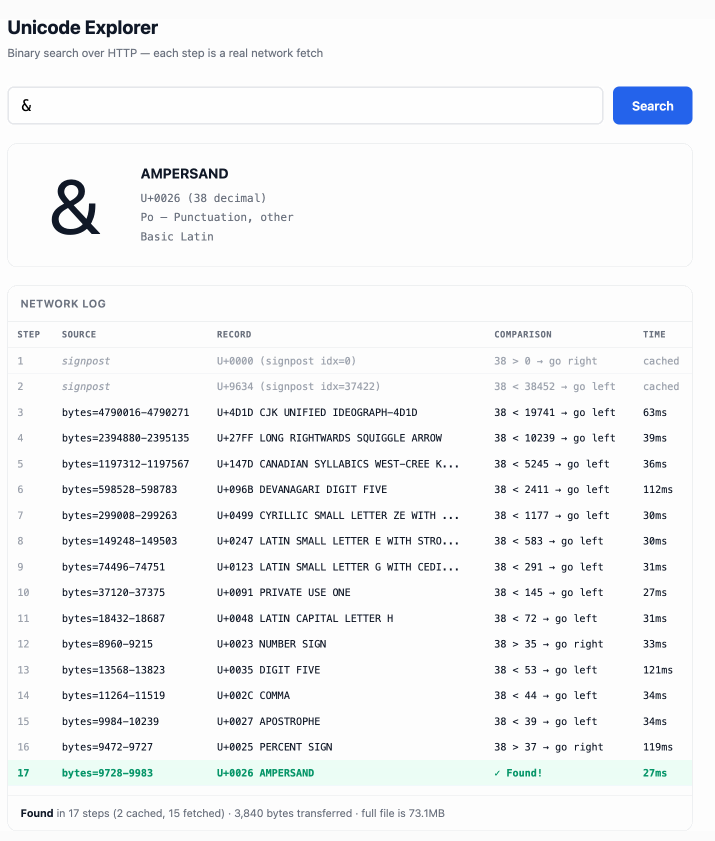
The demo is fun to play with - type in a single character like ø or a hexadecimal codepoint indicator like 1F99C and it will binary search its way through the large file and show you the steps it takes along the way:
2025
Scaling HNSWs (via) Salvatore Sanfilippo spent much of this year working on vector sets for Redis, which first shipped in Redis 8 in May.
A big part of that work involved implementing HNSW - Hierarchical Navigable Small World - an indexing technique first introduced in this 2016 paper by Yu. A. Malkov and D. A. Yashunin.
Salvatore's detailed notes on the Redis implementation here offer an immersive trip through a fascinating modern field of computer science. He describes several new contributions he's made to the HNSW algorithm, mainly around efficient deletion and updating of existing indexes.
Since embedding vectors are notoriously memory-hungry I particularly appreciated this note about how you can scale a large HNSW vector set across many different nodes and run parallel queries against them for both reads and writes:
[...] if you have different vectors about the same use case split in different instances / keys, you can ask VSIM for the same query vector into all the instances, and add the WITHSCORES option (that returns the cosine distance) and merge the results client-side, and you have magically scaled your hundred of millions of vectors into multiple instances, splitting your dataset N times [One interesting thing about such a use case is that you can query the N instances in parallel using multiplexing, if your client library is smart enough].
Another very notable thing about HNSWs exposed in this raw way, is that you can finally scale writes very easily. Just hash your element modulo N, and target the resulting Redis key/instance. Multiple instances can absorb the (slow, but still fast for HNSW standards) writes at the same time, parallelizing an otherwise very slow process.
It's always exciting to see new implementations of fundamental algorithms and data structures like this make it into Redis because Salvatore's C code is so clearly commented and pleasant to read - here's vector-sets/hnsw.c and vector-sets/vset.c.
Reservoir Sampling (via) Yet another outstanding interactive essay by Sam Rose (previously), this time explaining how reservoir sampling can be used to select a "fair" random sample when you don't know how many options there are and don't want to accumulate them before making a selection.
Reservoir sampling is one of my favourite algorithms, and I've been wanting to write about it for years now. It allows you to solve a problem that at first seems impossible, in a way that is both elegant and efficient.
I appreciate that Sam starts the article with "No math notation, I promise." Lots of delightful widgets to interact with here, all of which help build an intuitive understanding of the underlying algorithm.
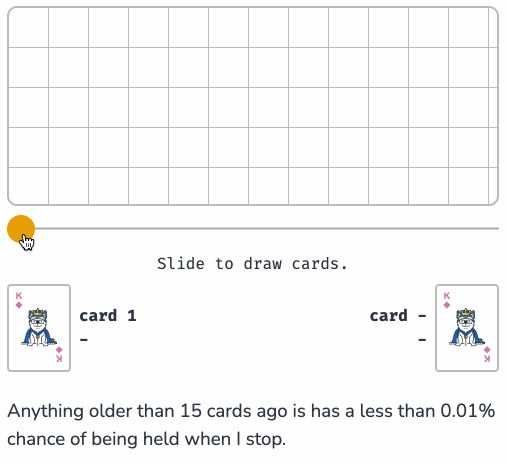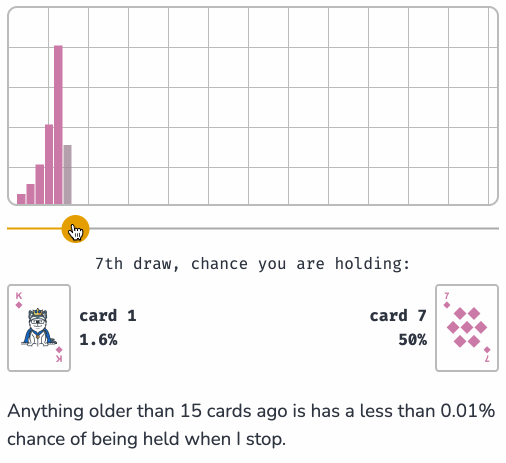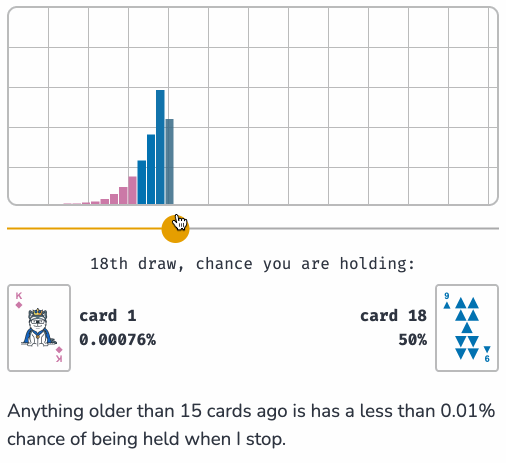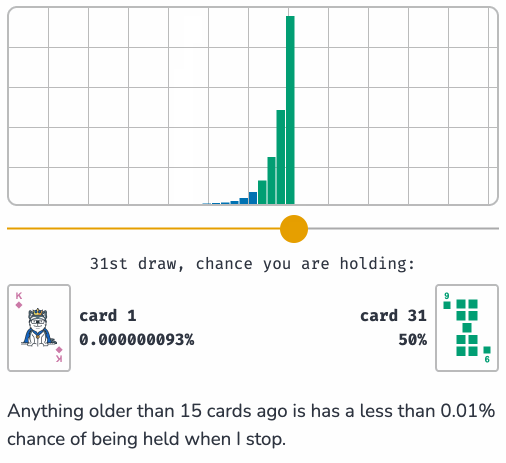
Sam shows how this algorithm can be applied to the real-world problem of sampling log files when incoming logs threaten to overwhelm a log aggregator.
The dog illustration is commissioned art and the MIT-licensed code is available on GitHub.
2024
Understanding the BM25 full text search algorithm (via) Evan Schwartz provides a deep dive explanation of how the classic BM25 search relevance scoring function works, including a very useful breakdown of the mathematics it uses.
Load Balancing. Sam Rose built this interactive essay explaining how different load balancing strategies work. It's part of a series that includes memory allocation, bloom filters and more.
2022
SQLite Internals: Pages & B-trees (via) Ben Johnson provides a delightfully clear introduction to SQLite internals, describing the binary format used to store rows on disk and how SQLite uses 4KB pages for both row storage and for the b-trees used to look up records.
Sha256 Algorithm Explained (via) Absolutely beautiful interactive animated explanation by Domingo Martin of the SHA256 hashing algorithm.
2021
The humble hash aggregate (via) Today I learned that “hash aggregate” is the name for the algorithm where you split a list of tuples on a common key, run an aggregation against each resulting group and combine the results back together again—I’d previously thought if this in terms of map/reduce but hash aggregate is a much older term used widely by SQL engines—I’ve seen it come up in PostgreSQL explain query output (for GROUP BY) before but didn’t know what it meant.
2020
I was wrong. CRDTs are the future (via) Joseph Gentle has been working on collaborative editors since being a developer on Google Wave back in 2010, later building ShareJS. He’s used Operational Transforms throughout, due to their performance and memory benefits over CRDTs (Conflict-free replicated data types)—but the latest work in that space from Martin Kleppmann and other researchers has seen him finally switch allegiance to these newer algorithms. As a long-time fan of collaborative editing (ever since the Hydra/SubEthaEdit days) I thoroughly enjoyed this as an update on how things have evolved over the past decade.
2010
Creating Shazam in Java. Using a Fast Fourier Transformation.
2009
OpenStreetMap: QuadTiles. Fascinating explanation of a proposal for replacing lat, lon pairs in the OpenStreetMap database with a QuadTile-based addressing system.
How to Build a Popularity Algorithm You can be Proud of. Filed for future reference.
Visualising Sorting Algorithms. Aldo Cortesi dislikes animations of sorting algorithms, so he designed a beautiful technique for statically visualising them instead (using Python and Cairo to generate the images).
Neil Fraser: Differential Synchronization. Paper describing a robust method for “keeping two or more copies of the same document synchronized with each other in real-time”, over a variable network connection using clever diff algorithms.
2008
Animated Sorting Algorithms (via) JavaScript animations of various sorting algorithms, running against four different initial conditions (random, nearly ordered, reversed and few unique). I wish I’d had this during my computer science degree.
Core Techniques and Algorithms in Game Programming. Scarily detailed online book on games programming, including 2D and 3D graphics, AI, multiplayer network code, indoor and outdoor rendering, character animation and much more. UPDATE: Removed the original link, which appeared to be a pirated copy.
2007
gefingerpoken. Michal Migurski shows how to implement the algorithm for two-finger deforming drag using affine transformation matrices in Flash.
Google Maps API gets clickable polylines and polygons. Interesting explanation of how they optimised calculating the distance to the nearest point on a polyline.
2006
python-cluster. Fantastic interface design—pass a list and a function and you’re done.