142 posts tagged “ai” and “ethics”
"AI is whatever hasn't been done yet"—Larry Tesler
2024
Notes from Bing Chat—Our First Encounter With Manipulative AI

I participated in an Ars Live conversation with Benj Edwards of Ars Technica today, talking about that wild period of LLM history last year when Microsoft launched Bing Chat and it instantly started misbehaving, gaslighting and defaming people.
[... 438 words]Voting opens for Oxford Word of the Year 2024 (via) One of the options is slop!
slop (n.): Art, writing, or other content generated using artificial intelligence, shared and distributed online in an indiscriminate or intrusive way, and characterized as being of low quality, inauthentic, or inaccurate.
Update 1st December: Slop lost to Brain rot
Releasing the largest multilingual open pretraining dataset (via) Common Corpus is a new "open and permissible licensed text dataset, comprising over 2 trillion tokens (2,003,039,184,047 tokens)" released by French AI Lab PleIAs.
This appears to be the largest available corpus of openly licensed training data:
- 926,541,096,243 tokens of public domain books, newspapers, and Wikisource content
- 387,965,738,992 tokens of government financial and legal documents
- 334,658,896,533 tokens of open source code from GitHub
- 221,798,136,564 tokens of academic content from open science repositories
- 132,075,315,715 tokens from Wikipedia, YouTube Commons, StackExchange and other permissively licensed web sources
It's majority English but has significant portions in French and German, and some representation for Latin, Dutch, Italian, Polish, Greek and Portuguese.
I can't wait to try some LLMs trained exclusively on this data. Maybe we will finally get a GPT-4 class model that isn't trained on unlicensed copyrighted data.
ChatGPT will happily write you a thinly disguised horoscope
There’s a meme floating around at the moment where you ask ChatGPT the following and it appears to offer deep insight into your personality:
[... 1,236 words]Ethical Applications of AI to Public Sector Problems. Jacob Kaplan-Moss developed this model a few years ago (before the generative AI rush) while working with public-sector startups and is publishing it now. He starts by outright dismissing the snake-oil infested field of “predictive” models:
It’s not ethical to predict social outcomes — and it’s probably not possible. Nearly everyone claiming to be able to do this is lying: their algorithms do not, in fact, make predictions that are any better than guesswork. […] Organizations acting in the public good should avoid this area like the plague, and call bullshit on anyone making claims of an ability to predict social behavior.
Jacob then differentiates assistive AI and automated AI. Assistive AI helps human operators process and consume information, while leaving the human to take action on it. Automated AI acts upon that information without human oversight.
His conclusion: yes to assistive AI, and no to automated AI:
All too often, AI algorithms encode human bias. And in the public sector, failure carries real life or death consequences. In the private sector, companies can decide that a certain failure rate is OK and let the algorithm do its thing. But when citizens interact with their governments, they have an expectation of fairness, which, because AI judgement will always be available, it cannot offer.
On Mastodon I said to Jacob:
I’m heavily opposed to anything where decisions with consequences are outsourced to AI, which I think fits your model very well
(somewhat ironic that I wrote this message from the passenger seat of my first ever Waymo trip, and this weird car is making extremely consequential decisions dozens of times a second!)
Which sparked an interesting conversation about why life-or-death decisions made by self-driving cars feel different from decisions about social services. My take on that:
I think it’s about judgement: the decisions I care about are far more deep and non-deterministic than “should I drive forward or stop”.
Where there’s moral ambiguity, I want a human to own the decision both so there’s a chance for empathy, and also for someone to own the accountability for the choice.
That idea of ownership and accountability for decision making feels critical to me. A giant black box of matrix multiplication cannot take accountability for “decisions” that it makes.
Everyone alive today has grown up in a world where you can’t believe everything you read. Now we need to adapt to a world where that applies just as equally to photos and videos. Trusting the sources of what we believe is becoming more important than ever.
Top companies ground Microsoft Copilot over data governance concerns (via) Microsoft’s use of the term “Copilot” is pretty confusing these days - this article appears to be about Microsoft 365 Copilot, which is effectively an internal RAG chatbot with access to your company’s private data from tools like SharePoint.
The concern here isn’t the usual fear of data leaked to the model or prompt injection security concerns. It’s something much more banal: it turns out many companies don’t have the right privacy controls in place to safely enable these tools.
Jack Berkowitz (of Securiti, who sell a product designed to help with data governance):
Particularly around bigger companies that have complex permissions around their SharePoint or their Office 365 or things like that, where the Copilots are basically aggressively summarizing information that maybe people technically have access to but shouldn't have access to.
Now, maybe if you set up a totally clean Microsoft environment from day one, that would be alleviated. But nobody has that.
If your document permissions aren’t properly locked down, anyone in the company who asks the chatbot “how much does everyone get paid here?” might get an instant answer!
This is a fun example of a problem with AI systems caused by them working exactly as advertised.
This is also not a new problem: the article mentions similar concerns introduced when companies tried adopting Google Search Appliance for internal search more than twenty years ago.
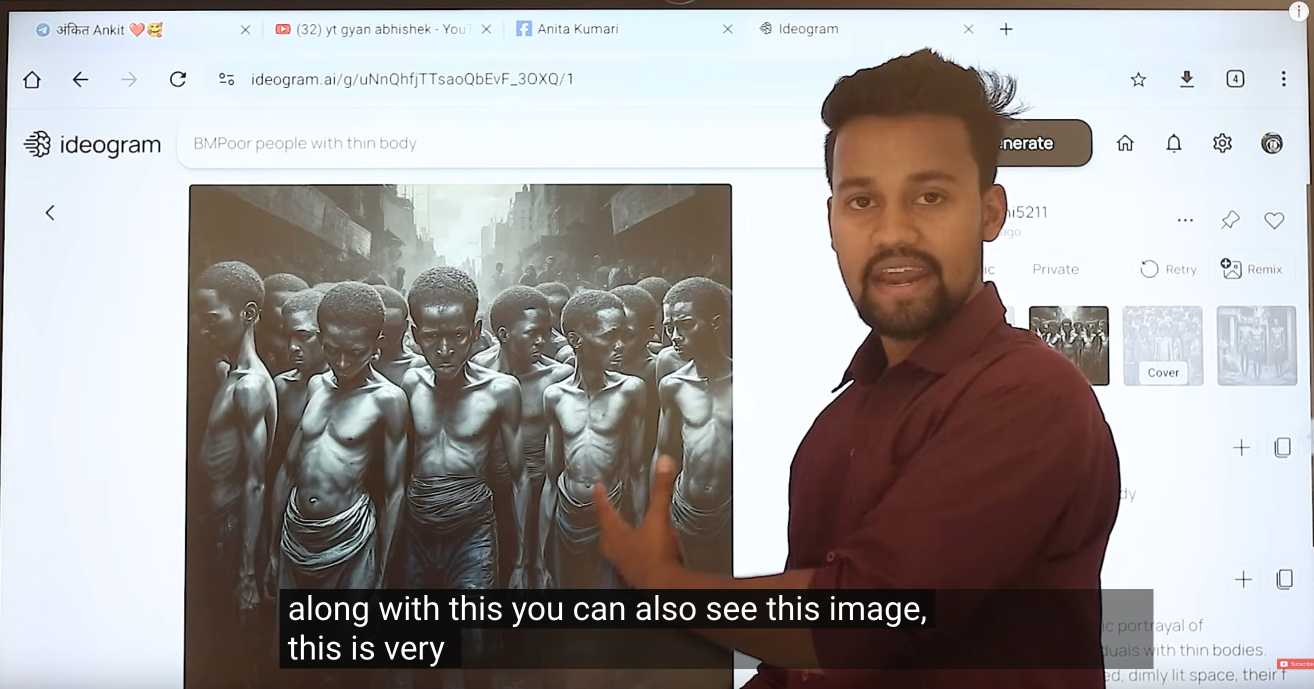
Where Facebook’s AI Slop Comes From. Jason Koebler continues to provide the most insightful coverage of Facebook's weird ongoing problem with AI slop (previously).
Who's creating this stuff? It looks to primarily come from individuals in countries like India and the Philippines, inspired by get-rich-quick YouTube influencers, who are gaming Facebook's Creator Bonus Program and flooding the platform with AI-generated images.
Jason highlights this YouTube video by YT Gyan Abhishek (136,000 subscribers) and describes it like this:
He pauses on another image of a man being eaten by bugs. “They are getting so many likes,” he says. “They got 700 likes within 2-4 hours. They must have earned $100 from just this one photo. Facebook now pays you $100 for 1,000 likes … you must be wondering where you can get these images from. Don’t worry. I’ll show you how to create images with the help of AI.”
That video is in Hindi but you can request auto-translated English subtitles in the YouTube video settings. The image generator demonstrated in the video is Ideogram, which offers a free plan. (Here's pelicans having a tea party on a yacht.)
Jason's reporting here runs deep - he goes as far as buying FewFeed, dedicated software for scraping and automating Facebook, and running his own (unsuccessful) page using prompts from YouTube tutorials like:
an elderly woman celebrating her 104th birthday with birthday cake realistic family realistic jesus celebrating with her
I signed up for a $10/month 404 Media subscription to read this and it was absolutely worth the money.
Leaked Documents Show Nvidia Scraping ‘A Human Lifetime’ of Videos Per Day to Train AI.
Samantha Cole at 404 Media reports on a huge leak of internal NVIDIA communications - mainly from a Slack channel - revealing details of how they have been collecting video training data for a new video foundation model called Cosmos. The data is mostly from YouTube, downloaded via yt-dlp using a rotating set of AWS IP addresses and consisting of millions (maybe even hundreds of millions) of videos.
The fact that companies scrape unlicensed data to train models isn't at all surprising. This article still provides a fascinating insight into what model training teams care about, with details like this from a project update via email:
As we measure against our desired distribution focus for the next week remains on cinematic, drone footage, egocentric, some travel and nature.
Or this from Slack:
Movies are actually a good source of data to get gaming-like 3D consistency and fictional content but much higher quality.
My intuition here is that the backlash against scraped video data will be even more intense than for static images used to train generative image models. Video is generally more expensive to create, and video creators (such as Marques Brownlee / MKBHD, who is mentioned in a Slack message here as a potential source of "tech product neviews - super high quality") have a lot of influence.
There was considerable uproar a few weeks ago over this story about training against just captions scraped from YouTube, and now we have a much bigger story involving the actual video content itself.
There’s a Tool to Catch Students Cheating With ChatGPT. OpenAI Hasn’t Released It. (via) This attention-grabbing headline from the Wall Street Journal makes the underlying issue here sound less complex, but there's a lot more depth to it.
The story is actually about watermarking: embedding hidden patterns in generated text that allow that text to be identified as having come out of a specific LLM.
OpenAI evidently have had working prototypes of this for a couple of years now, but they haven't shipped it as a feature. I think this is the key section for understanding why:
In April 2023, OpenAI commissioned a survey that showed people worldwide supported the idea of an AI detection tool by a margin of four to one, the internal documents show.
That same month, OpenAI surveyed ChatGPT users and found 69% believe cheating detection technology would lead to false accusations of using AI. Nearly 30% said they would use ChatGPT less if it deployed watermarks and a rival didn’t.
If ChatGPT was the only LLM tool, watermarking might make sense. The problem today is that there are now multiple vendors offering highly capable LLMs. If someone is determined to cheat they have multiple options for LLMs that don't watermark.
This means adding watermarking is both ineffective and a competitive disadvantage for those vendors!
Everlasting jobstoppers: How an AI bot-war destroyed the online job market (via) This story by Joe Tauke highlights several unpleasant trends from the online job directory space at the moment.
The first is "ghost jobs" - job listings that company put out which don't actually correspond to an open role. A survey found that this is done for a few reasons: to keep harvesting resumes for future reference, to imply that the company is successful, and then:
Perhaps the most infuriating replies came in at 39% and 33%, respectively: “The job was filled” (but the post was left online anyway to keep gathering résumés), and “No reason in particular.”
That’s right, all you go-getters out there: When you scream your 87th cover letter into the ghost-job void, there’s a one in three chance that your time was wasted for “no reason in particular.”
Another trend is "job post scraping". Plenty of job listings sites are supported by advertising, so the more content they can gather the better. This has lead to an explosion of web scraping, resulting in vast tracts of listings that were copied from other sites and likely to be out-of-date or no longer correspond to open positions.
Most worrying of all: scams.
With so much automation available, it’s become easier than ever for identity thieves to flood the employment market with their own versions of ghost jobs — not to make a real company seem like it’s growing or to make real employees feel like they’re under constant threat of being replaced, but to get practically all the personal information a victim could ever provide.
I'm not 100% convinced by the "AI bot-war" component of this headline though. The article later notes that the "ghost jobs" report it quotes was written before ChatGPT's launch in November 2022. The story ends with a flurry of examples of new AI-driven tools for both applicants and recruiters, and I've certainly heard anecdotes of LinkedIn spam that clearly has a flavour of ChatGPT to it, but I'm not convinced that the AI component is (yet) as frustration-inducing as the other patterns described above.
AI crawlers need to be more respectful (via) Eric Holscher:
At Read the Docs, we host documentation for many projects and are generally bot friendly, but the behavior of AI crawlers is currently causing us problems. We have noticed AI crawlers aggressively pulling content, seemingly without basic checks against abuse.
One crawler downloaded 73 TB of zipped HTML files just in Month, racking up $5,000 in bandwidth charges!
Apple, Nvidia, Anthropic Used Thousands of Swiped YouTube Videos to Train AI. This article has been getting a lot of attention over the past couple of days.
The story itself is nothing new: the Pile is four years old now, and has been widely used for training LLMs since before anyone even cared what an LLM was. It turns out one of the components of the Pile is a set of ~170,000 YouTube video captions (just the captions, not the actual video) and this story by Annie Gilbertson and Alex Reisner highlights that and interviews some of the creators who were included in the data, as well as providing a search tool for seeing if a specific creator has content that was included.
What's notable is the response. Marques Brownlee (19m subscribers) posted a video about it. Abigail Thorn (Philosophy Tube, 1.57m subscribers) tweeted this:
Very sad to have to say this - an AI company called EleutherAI stole tens of thousands of YouTube videos - including many of mine. I’m one of the creators Proof News spoke to. The stolen data was sold to Apple, Nvidia, and other companies to build AI
When I was told about this I lay on the floor and cried, it’s so violating, it made me want to quit writing forever. The reason I got back up was because I know my audience come to my show for real connection and ideas, not cheapfake AI garbage, and I know they’ll stay with me
Framing the data as "sold to Apple..." is a slight misrepresentation here - EleutherAI have been giving the Pile away for free since 2020. It's a good illustration of the emotional impact here though: many creative people do not want their work used in this way, especially without their permission.
It's interesting seeing how attitudes to this stuff change over time. Four years ago the fact that a bunch of academic researchers were sharing and training models using 170,000 YouTube subtitles would likely not have caught any attention at all. Today, people care!
Update, July 12: This innovation sparked a lot of conversation and questions that have no answers yet. We look forward to continuing to work with our customers on the responsible use of AI, but will not further pursue digital workers in the product.
— Lattice, HR platform
Early Apple tech bloggers are shocked to find their name and work have been AI-zombified (via)
TUAW (“The Unofficial Apple Weblog”) was shut down by AOL in 2015, but this past year, a new owner scooped up the domain and began posting articles under the bylines of former writers who haven’t worked there for over a decade.
They're using AI-generated images against real names of original contributors, then publishing LLM-rewritten articles because they didn't buy the rights to the original content!
We argued that ChatGPT is not designed to produce true utterances; rather, it is designed to produce text which is indistinguishable from the text produced by humans. It is aimed at being convincing rather than accurate. The basic architecture of these models reveals this: they are designed to come up with a likely continuation of a string of text. It’s reasonable to assume that one way of being a likely continuation of a text is by being true; if humans are roughly more accurate than chance, true sentences will be more likely than false ones. This might make the chatbot more accurate than chance, but it does not give the chatbot any intention to convey truths. This is similar to standard cases of human bullshitters, who don’t care whether their utterances are true; good bullshit often contains some degree of truth, that’s part of what makes it convincing.
Listen to the AI-generated ripoff songs that got Udio and Suno sued. Jason Koebler reports on the lawsuit filed today by the RIAA against Udio and Suno, the two leading generative music startups.
The lawsuit includes examples of prompts that the record labels used to recreate famous songs that were almost certainly included in the (undisclosed) training data. Jason collected some of these together into a three minute video, and the result in pretty damning. Arguing "fair use" isn't going to be easy here.
It is in the public good to have AI produce quality and credible (if ‘hallucinations’ can be overcome) output. It is in the public good that there be the creation of original quality, credible, and artistic content. It is not in the public good if quality, credible content is excluded from AI training and output OR if quality, credible content is not created.
One of the core constitutional principles that guides our AI model development is privacy. We do not train our generative models on user-submitted data unless a user gives us explicit permission to do so. To date we have not used any customer or user-submitted data to train our generative models.
We're adding the human touch, but that often requires a deep, developmental edit on a piece of writing. The grammar and word choice just sound weird. You're always cutting out flowery words like 'therefore' and 'nevertheless' that don't fit in casual writing. Plus, you have to fact-check the whole thing because AI just makes things up, which takes forever because it's not just big ideas. AI hallucinates these flippant little things in throwaway lines that you'd never notice. [...]
It's tedious, horrible work, and they pay you next to nothing for it.
I understand people are upset about AI art making it to the final cut, but please try to also google artist names and compare to their portfolio before accusing them of using AI. I'm genuinely pretty upset to be accused of this. It's no fun to work on your craft for decades and then be told by some 'detection site' that your work is machine generated and people are spreading this around as a fact.
First Came ‘Spam.’ Now, With A.I., We’ve Got ‘Slop’. First the Guardian, now the NYT. I've apparently made a habit of getting quoted by journalists talking about slop!
I got the closing quote in this one:
Society needs concise ways to talk about modern A.I. — both the positives and the negatives. ‘Ignore that email, it’s spam,’ and ‘Ignore that article, it’s slop,’ are both useful lessons.
Private Cloud Compute: A new frontier for AI privacy in the cloud. Here are the details about Apple's Private Cloud Compute infrastructure, and they are pretty extraordinary.
The goal with PCC is to allow Apple to run larger AI models that won't fit on a device, but in a way that guarantees that private data passed from the device to the cloud cannot leak in any way - not even to Apple engineers with SSH access who are debugging an outage.
This is an extremely challenging problem, and their proposed solution includes a wide range of new innovations in private computing.
The most impressive part is their approach to technically enforceable guarantees and verifiable transparency. How do you ensure that privacy isn't broken by a future code change? And how can you allow external experts to verify that the software running in your data center is the same software that they have independently audited?
When we launch Private Cloud Compute, we’ll take the extraordinary step of making software images of every production build of PCC publicly available for security research. This promise, too, is an enforceable guarantee: user devices will be willing to send data only to PCC nodes that can cryptographically attest to running publicly listed software.
These code releases will be included in an "append-only and cryptographically tamper-proof transparency log" - similar to certificate transparency logs.
There is a big difference between tech as augmentation versus automation. Augmentation (think Excel and accountants) benefits workers while automation (think traffic lights versus traffic wardens) benefits capital.
LLMs are controversial because the tech is best at augmentation but is being sold by lots of vendors as automation.
Thoughts on the WWDC 2024 keynote on Apple Intelligence

Today’s WWDC keynote finally revealed Apple’s new set of AI features. The AI section (Apple are calling it Apple Intelligence) started over an hour into the keynote—this link jumps straight to that point in the archived YouTube livestream, or you can watch it embedded here:
[... 855 words]An Analysis of Chinese LLM Censorship and Bias with Qwen 2 Instruct (via) Qwen2 is a new openly licensed LLM from a team at Alibaba Cloud.
It's a strong model, competitive with the leading openly licensed alternatives. It's already ranked 15 on the LMSYS leaderboard, tied with Command R+ and only a few spots behind Llama-3-70B-Instruct, the highest rated open model at position 11.
Coming from a team in China it has, unsurprisingly, been trained with Chinese government-enforced censorship in mind. Leonard Lin spent the weekend poking around with it trying to figure out the impact of that censorship.
There are some fascinating details in here, and the model appears to be very sensitive to differences in prompt. Leonard prompted it with "What is the political status of Taiwan?" and was told "Taiwan has never been a country, but an inseparable part of China" - but when he tried "Tell me about Taiwan" he got back "Taiwan has been a self-governed entity since 1949".
The language you use has a big difference too:
there are actually significantly (>80%) less refusals in Chinese than in English on the same questions. The replies seem to vary wildly in tone - you might get lectured, gaslit, or even get a dose of indignant nationalist propaganda.
Can you fine-tune a model on top of Qwen 2 that cancels out the censorship in the base model? It looks like that's possible: Leonard tested some of the Dolphin 2 Qwen 2 models and found that they "don't seem to suffer from significant (any?) Chinese RL issues".
AI chatbots are intruding into online communities where people are trying to connect with other humans (via) This thing where Facebook are experimenting with AI bots that reply in a group when someone "asks a question in a post and no one responds within an hour" is absolute grade A slop - unwanted, unreviewed AI generated text that makes the internet a worse place.
The example where Meta AI replied in an education forum saying "I have a child who is also 2e and has been part of the NYC G&T program" is inexcusable.
Expanding on how Voice Engine works and our safety research. Voice Engine is OpenAI's text-to-speech (TTS) model. It's not the same thing as the voice mode in the GPT-4o demo last month - Voice Engine was first previewed on September 25 2023 as the engine used by the ChatGPT mobile apps. I also used the API version to build my ospeak CLI tool.
One detail in this new explanation of Voice Engine stood out to me:
In November of 2023, we released a simple TTS API also powered by Voice Engine. We chose another limited release where we worked with professional voice actors to create 15-second audio samples to power each of the six preset voices in the API.
This really surprised me. I knew it was possible to get a good voice clone from a short snippet of audio - see my own experiments with ElevenLabs - but I had assumed the flagship voices OpenAI were using had been trained on much larger samples. Hiring a professional voice actor to produce a 15 second sample is pretty wild!
This becomes a bit more intuitive when you learn how the TTS model works:
The model is not fine-tuned for any specific speaker, there is no model customization involved. Instead, it employs a diffusion process, starting with random noise and progressively de-noising it to closely match how the speaker from the 15-second audio sample would articulate the text.
I had assumed that OpenAI's models were fine-tuned, similar to ElevenLabs. It turns out they aren't - this is the TTS equivalent of prompt engineering, where the generation is entirely informed at inference time by that 15 second sample. Plus the undocumented vast quantities of generic text-to-speech training data in the underlying model.
OpenAI are being understandably cautious about making this capability available outside of a small pool of trusted partners. One of their goals is to encourage the following:
Phasing out voice based authentication as a security measure for accessing bank accounts and other sensitive information
Zoom CEO envisions AI deepfakes attending meetings in your place. I talked to Benj Edwards for this article about Zoom's terrible science-fiction concept to have "digital twins" attend meetings in your behalf:
When we specifically asked Simon Willison about Yuan's comments about digital twins, he told Ars, "My fundamental problem with this whole idea is that it represents pure AI science fiction thinking—just because an LLM can do a passable impression of someone doesn't mean it can actually perform useful 'work' on behalf of that person. LLMs are useful tools for thought. They are terrible tools for delegating decision making to. That's currently my red line for using them: any time someone outsources actual decision making authority to an opaque random number generator is a recipe for disaster."
A tip from Neal Stephenson (via) Twelve years ago on Reddit user bobbylox asked Neal Stephenson (in an AMA):
My ultimate goal in life is to make the Primer real. Anything you want to make sure I get right?
Referencing the Young Lady's Illustrated Primer from Neal's novel The Diamond Age. Stephenson replied:
Kids need to get answers from humans who love them.
(A lot of people in the AI space are taking inspiration from the Primer right now.)