Tuesday, 26th March 2024
Semgrep: AutoFixes using LLMs (via) semgrep is a really neat tool for semantic grep against source code—you can give it a pattern like “log.$A(...)” to match all forms of log.warning(...) / log.error(...) etc.
Ilia Choly built semgrepx— xargs for semgrep—and here shows how it can be used along with my llm CLI tool to execute code replacements against matches by passing them through an LLM such as Claude 3 Opus.
My binary vector search is better than your FP32 vectors. I’m still trying to get my head around this, but here’s what I understand so far.
Embedding vectors as calculated by models such as OpenAI text-embedding-3-small are arrays of floating point values, which look something like this:
[0.0051681744, 0.017187592, -0.018685209, -0.01855924, -0.04725188...]—1356 elements long
Different embedding models have different lengths, but they tend to be hundreds up to low thousands of numbers. If each float is 32 bits that’s 4 bytes per float, which can add up to a lot of memory if you have millions of embedding vectors to compare.
If you look at those numbers you’ll note that they are all pretty small positive or negative numbers, close to 0.
Binary vector search is a trick where you take that sequence of floating point numbers and turn it into a binary vector—just a list of 1s and 0s, where you store a 1 if the corresponding float was greater than 0 and a 0 otherwise.
For the above example, this would start [1, 1, 0, 0, 0...]
Incredibly, it looks like the cosine distance between these 0 and 1 vectors captures much of the semantic relevant meaning present in the distance between the much more accurate vectors. This means you can use 1/32nd of the space and still get useful results!
Ce Gao here suggests a further optimization: use the binary vectors for a fast brute-force lookup of the top 200 matches, then run a more expensive re-ranking against those filtered values using the full floating point vectors.
Cohere int8 & binary Embeddings—Scale Your Vector Database to Large Datasets (via) Jo Kristian Bergum told me “The accuracy retention [of binary embedding vectors] is sensitive to whether the model has been using this binarization as part of the loss function.”
Cohere provide an API for embeddings, and last week added support for returning binary vectors specifically tuned in this way.
250M embeddings (Cohere provide a downloadable dataset of 250M embedded documents from Wikipedia) at float32 (4 bytes) is 954GB.
Cohere claim that reducing to 1 bit per dimension knocks that down to 30 GB (954/32) while keeping “90-98% of the original search quality”.
GGML GGUF File Format Vulnerabilities. The GGML and GGUF formats are used by llama.cpp to package and distribute model weights.
Neil Archibald: “The GGML library performs insufficient validation on the input file and, therefore, contains a selection of potentially exploitable memory corruption vulnerabilities during parsing.”
These vulnerabilities were shared with the library authors on 23rd January and patches landed on the 29th.
If you have a llama.cpp or llama-cpp-python installation that’s more than a month old you should upgrade ASAP.
llm cmd undo last git commit—a new plugin for LLM
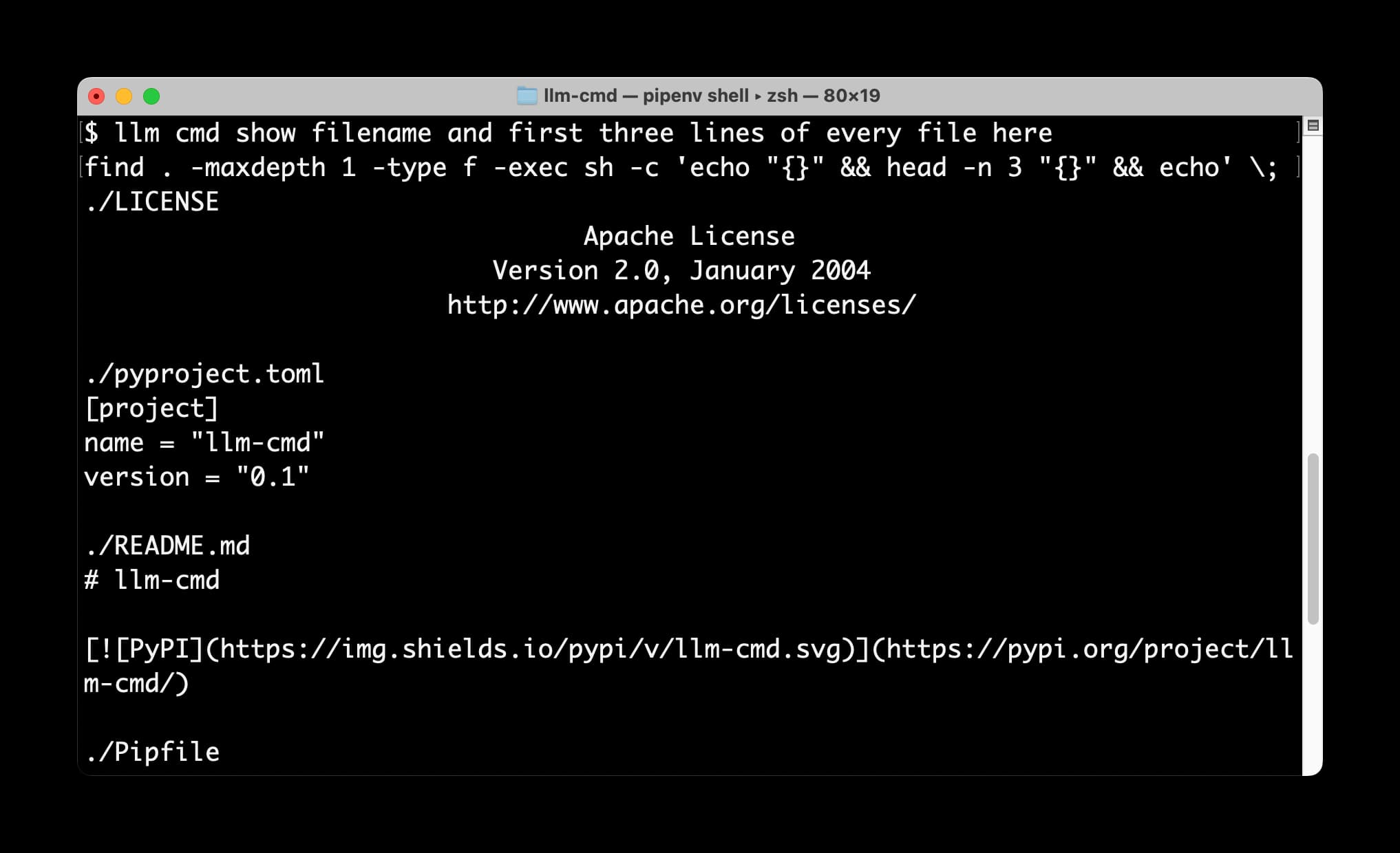
I just released a neat new plugin for my LLM command-line tool: llm-cmd. It lets you run a command to to generate a further terminal command, review and edit that command, then hit <enter> to execute it or <ctrl-c> to cancel.
gchq.github.io/CyberChef (via) CyberChef is “the Cyber Swiss Army Knife—a web app for encryption, encoding, compression and data analysis”—entirely client-side JavaScript with dozens of useful tools for working with different formats and encodings.
It’s maintained and released by GCHQ—the UK government’s signals intelligence security agency.
I didn’t know GCHQ had a presence on GitHub, and I find the URL to this tool absolutely delightful. They first released it back in 2016 and it has over 3,700 commits.
The top maintainers also have suitably anonymous usernames—great work, n1474335, j433866, d98762625 and n1073645.