35 posts tagged “rag”
RAG stands for Retrieval Augmented Generation. It's a trick where you find additional context relevant to the user's request using other means (such as full-text or vector search) and populate that context as part of the prompt to a Large Language Model.
2023
Embeddings: What they are and why they matter
Embeddings are a really neat trick that often come wrapped in a pile of intimidating jargon.
[... 5,835 words]LLM now provides tools for working with embeddings

LLM is my Python library and command-line tool for working with language models. I just released LLM 0.9 with a new set of features that extend LLM to provide tools for working with embeddings.
[... 3,521 words]Llama 2 is about as factually accurate as GPT-4 for summaries and is 30X cheaper. Anyscale offer (cheap, fast) API access to Llama 2, so they’re not an unbiased source of information—but I really hope their claim here that Llama 2 70B provides almost equivalent summarization quality to GPT-4 holds up. Summarization is one of my favourite applications of LLMs, partly because it’s key to being able to implement Retrieval Augmented Generation against your own documents—where snippets of relevant documents are fed to the model and used to answer a user’s question. Having a really high performance openly licensed summarization model is a very big deal.
Making Large Language Models work for you

I gave an invited keynote at WordCamp 2023 in National Harbor, Maryland on Friday.
[... 14,189 words]How to implement Q&A against your documentation with GPT3, embeddings and Datasette
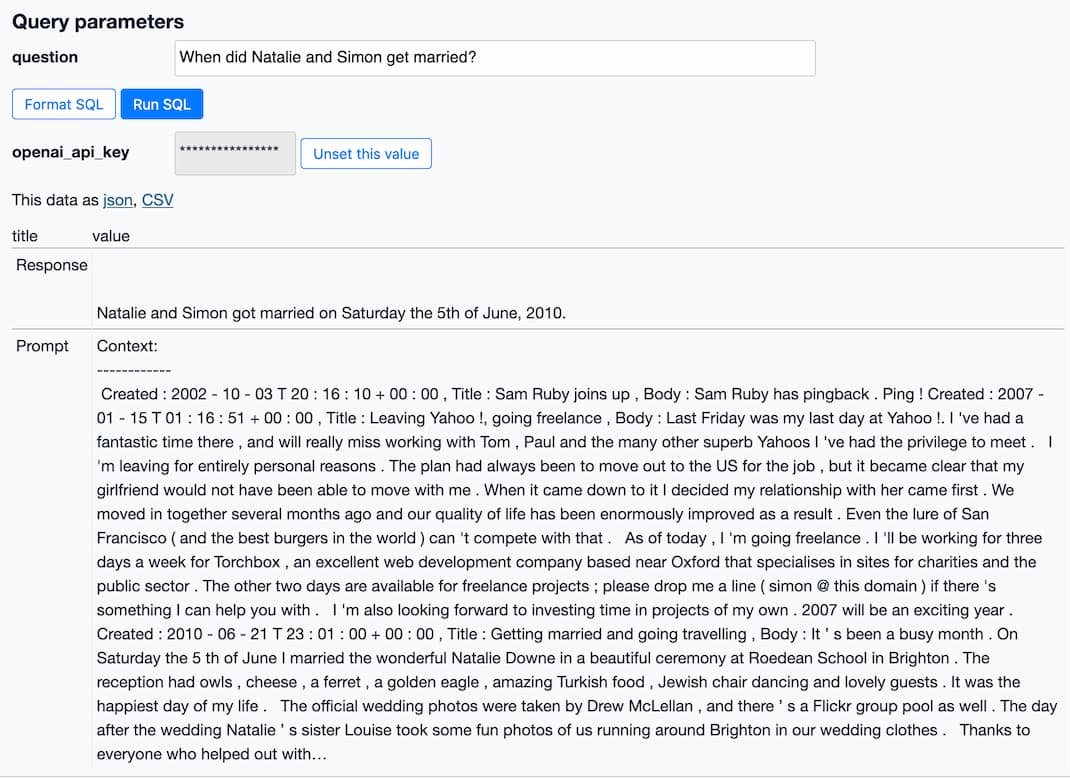
If you’ve spent any time with GPT-3 or ChatGPT, you’ve likely thought about how useful it would be if you could point them at a specific, current collection of text or documentation and have it use that as part of its input for answering questions.
[... 3,447 words]