10 posts tagged “phi”
Microsoft's Phi family of small Large Language Models.
2025
Saying “hi” to Microsoft’s Phi-4-reasoning
Microsoft released a new sub-family of models a few days ago: Phi-4 reasoning. They introduced them in this blog post celebrating a year since the release of Phi-3:
[... 1,498 words]Phi-4 Bug Fixes by Unsloth
(via)
This explains why I was seeing weird <|im_end|> suffexes during my experiments with Phi-4 the other day: it turns out the Phi-4 tokenizer definition as released by Microsoft had a bug in it, and there was a small bug in the chat template as well.
Daniel and Michael Han figured this out and have now published GGUF files with their fixes on Hugging Face.
microsoft/phi-4. Here's the official release of Microsoft's Phi-4 LLM, now officially under an MIT license.
A few weeks ago I covered the earlier unofficial versions, where I talked about how the model used synthetic training data in some really interesting ways.
It benchmarks favorably compared to GPT-4o, suggesting this is yet another example of a GPT-4 class model that can run on a good laptop.
The model already has several available community quantizations. I ran the mlx-community/phi-4-4bit one (a 7.7GB download) using mlx-llm like this:
uv run --with 'numpy<2' --with mlx-lm python -c '
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/phi-4-4bit")
prompt = "Generate an SVG of a pelican riding a bicycle"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True, max_tokens=2048)
print(response)'

Update: The model is now available via Ollama, so you can fetch a 9.1GB model file using ollama run phi4, after which it becomes available via the llm-ollama plugin.
2024
Phi-4 Technical Report (via) Phi-4 is the latest LLM from Microsoft Research. It has 14B parameters and claims to be a big leap forward in the overall Phi series. From Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning:
Phi-4 outperforms comparable and larger models on math related reasoning due to advancements throughout the processes, including the use of high-quality synthetic datasets, curation of high-quality organic data, and post-training innovations. Phi-4 continues to push the frontier of size vs quality.
The model is currently available via Azure AI Foundry. I couldn't figure out how to access it there, but Microsoft are planning to release it via Hugging Face in the next few days. It's not yet clear what license they'll use - hopefully MIT, as used by the previous models in the series.
In the meantime, unofficial GGUF versions have shown up on Hugging Face already. I got one of the matteogeniaccio/phi-4 GGUFs working with my LLM tool and llm-gguf plugin like this:
llm install llm-gguf
llm gguf download-model https://huggingface.co/matteogeniaccio/phi-4/resolve/main/phi-4-Q4_K_M.gguf
llm chat -m gguf/phi-4-Q4_K_M
This downloaded a 8.4GB model file. Here are some initial logged transcripts I gathered from playing around with the model.
An interesting detail I spotted on the Azure AI Foundry page is this:
Limited Scope for Code: Majority of phi-4 training data is based in Python and uses common packages such as
typing,math,random,collections,datetime,itertools. If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
This leads into the most interesting thing about this model: the way it was trained on synthetic data. The technical report has a lot of detail about this, including this note about why synthetic data can provide better guidance to a model:
Synthetic data as a substantial component of pretraining is becoming increasingly common, and the Phi series of models has consistently emphasized the importance of synthetic data. Rather than serving as a cheap substitute for organic data, synthetic data has several direct advantages over organic data.
Structured and Gradual Learning. In organic datasets, the relationship between tokens is often complex and indirect. Many reasoning steps may be required to connect the current token to the next, making it challenging for the model to learn effectively from next-token prediction. By contrast, each token generated by a language model is by definition predicted by the preceding tokens, making it easier for a model to follow the resulting reasoning patterns.
And this section about their approach for generating that data:
Our approach to generating synthetic data for phi-4 is guided by the following principles:
- Diversity: The data should comprehensively cover subtopics and skills within each domain. This requires curating diverse seeds from organic sources.
- Nuance and Complexity: Effective training requires nuanced, non-trivial examples that reflect the complexity and the richness of the domain. Data must go beyond basics to include edge cases and advanced examples.
- Accuracy: Code should execute correctly, proofs should be valid, and explanations should adhere to established knowledge, etc.
- Chain-of-Thought: Data should encourage systematic reasoning, teaching the model various approaches to the problems in a step-by-step manner. [...]
We created 50 broad types of synthetic datasets, each one relying on a different set of seeds and different multi-stage prompting procedure, spanning an array of topics, skills, and natures of interaction, accumulating to a total of about 400B unweighted tokens. [...]
Question Datasets: A large set of questions was collected from websites, forums, and Q&A platforms. These questions were then filtered using a plurality-based technique to balance difficulty. Specifically, we generated multiple independent answers for each question and applied majority voting to assess the consistency of responses. We discarded questions where all answers agreed (indicating the question was too easy) or where answers were entirely inconsistent (indicating the question was too difficult or ambiguous). [...]
Creating Question-Answer pairs from Diverse Sources: Another technique we use for seed curation involves leveraging language models to extract question-answer pairs from organic sources such as books, scientific papers, and code.
NuExtract 1.5. Structured extraction - where an LLM helps turn unstructured text (or image content) into structured data - remains one of the most directly useful applications of LLMs.
NuExtract is a family of small models directly trained for this purpose (though text only at the moment) and released under the MIT license.
It comes in a variety of shapes and sizes:
- NuExtract-v1.5 is a 3.8B parameter model fine-tuned on Phi-3.5-mini instruct. You can try this one out in this playground.
- NuExtract-tiny-v1.5 is 494M parameters, fine-tuned on Qwen2.5-0.5B.
- NuExtract-1.5-smol is 1.7B parameters, fine-tuned on SmolLM2-1.7B.
All three models were fine-tuned on NuMind's "private high-quality dataset". It's interesting to see a model family that uses one fine-tuning set against three completely different base models.
Useful tip from Steffen Röcker:
Make sure to use it with low temperature, I've uploaded NuExtract-tiny-v1.5 to Ollama and set it to 0. With the Ollama default of 0.7 it started repeating the input text. It works really well despite being so smol.
Running Llama 3.2 Vision and Phi-3.5 Vision on a Mac with mistral.rs
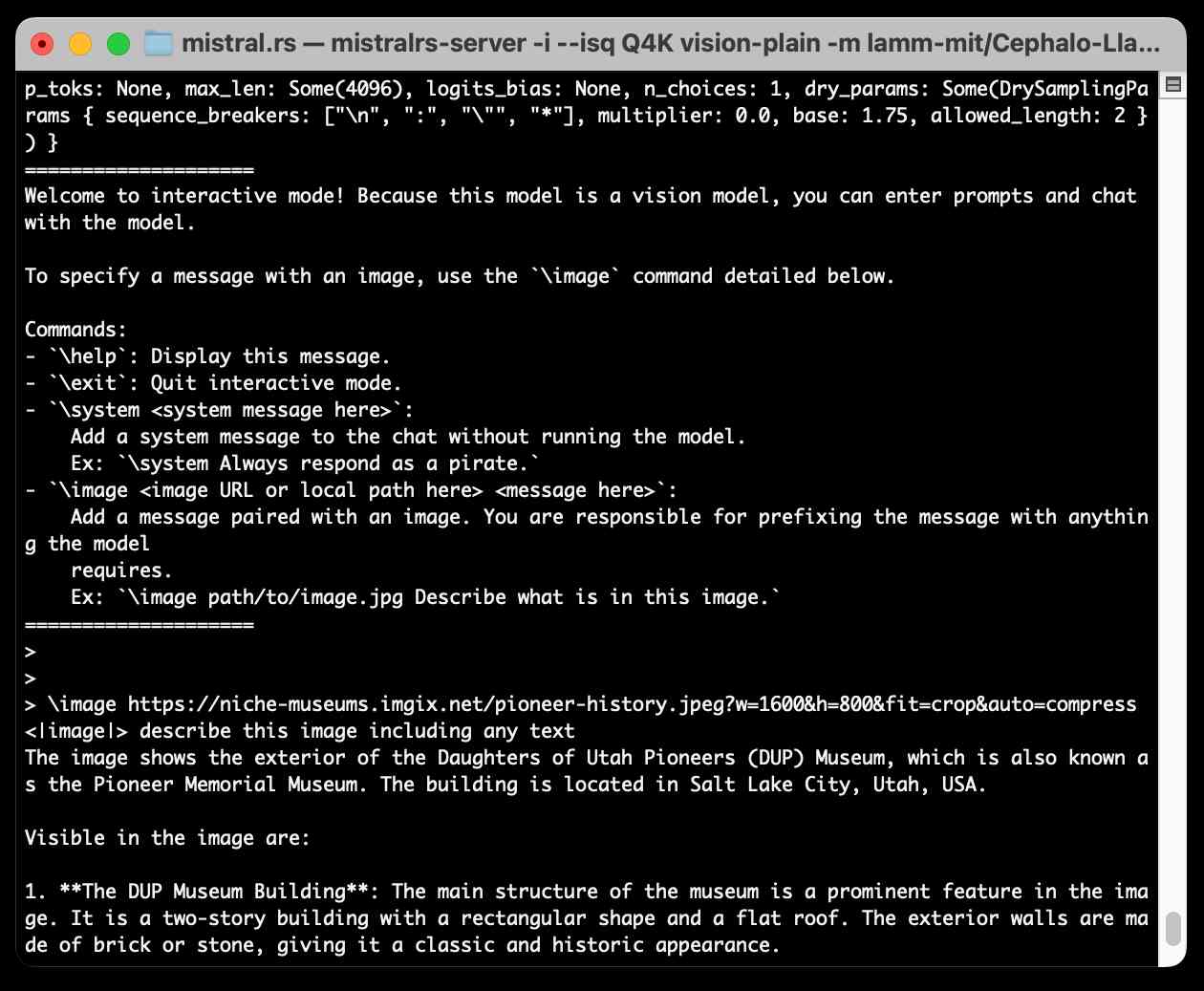
mistral.rs is an LLM inference library written in Rust by Eric Buehler. Today I figured out how to use it to run the Llama 3.2 Vision and Phi-3.5 Vision models on my Mac.
[... 1,231 words]New Phi-3 models: small, medium and vision. I couldn't find a good official announcement post to link to about these three newly released models, but this post on LocalLLaMA on Reddit has them in one place: Phi-3 small (7B), Phi-3 medium (14B) and Phi-3 vision (4.2B) (the previously released model was Phi-3 mini - 3.8B).
You can try out the vision model directly here, no login required. It didn't do a great job with my first test image though, hallucinating the text.
As with Mini these are all released under an MIT license.
UPDATE: Here's a page from the newly published Phi-3 Cookbook describing the models in the family.
experimental-phi3-webgpu (via) Run Microsoft’s excellent Phi-3 model directly in your browser, using WebGPU so didn’t work in Firefox for me, just in Chrome.
It fetches around 2.1GB of data into the browser cache on first run, but then gave me decent quality responses to my prompts running at an impressive 21 tokens a second (M2, 64GB).
I think Phi-3 is the highest quality model of this size, so it’s a really good fit for running in a browser like this.
microsoft/Phi-3-mini-4k-instruct-gguf (via) Microsoft’s Phi-3 LLM is out and it’s really impressive. This 4,000 token context GGUF model is just a 2.2GB (for the Q4 version) and ran on my Mac using the llamafile option described in the README. I could then run prompts through it using the llm-llamafile plugin.
The vibes are good! Initial test prompts I’ve tried feel similar to much larger 7B models, despite using just a few GBs of RAM. Tokens are returned fast too—it feels like the fastest model I’ve tried yet.
And it’s MIT licensed.
Microsoft Research relicense Phi-2 as MIT (via) Phi-2 was already an interesting model—really strong results for its size—made available under a non-commercial research license. It just got significantly more interesting: Microsoft relicensed it as MIT open source.