Monday, 28th October 2024
Prompt GPT-4o audio. A week and a half ago I built a tool for experimenting with OpenAI's new audio input. I just put together the other side of that, for experimenting with audio output.
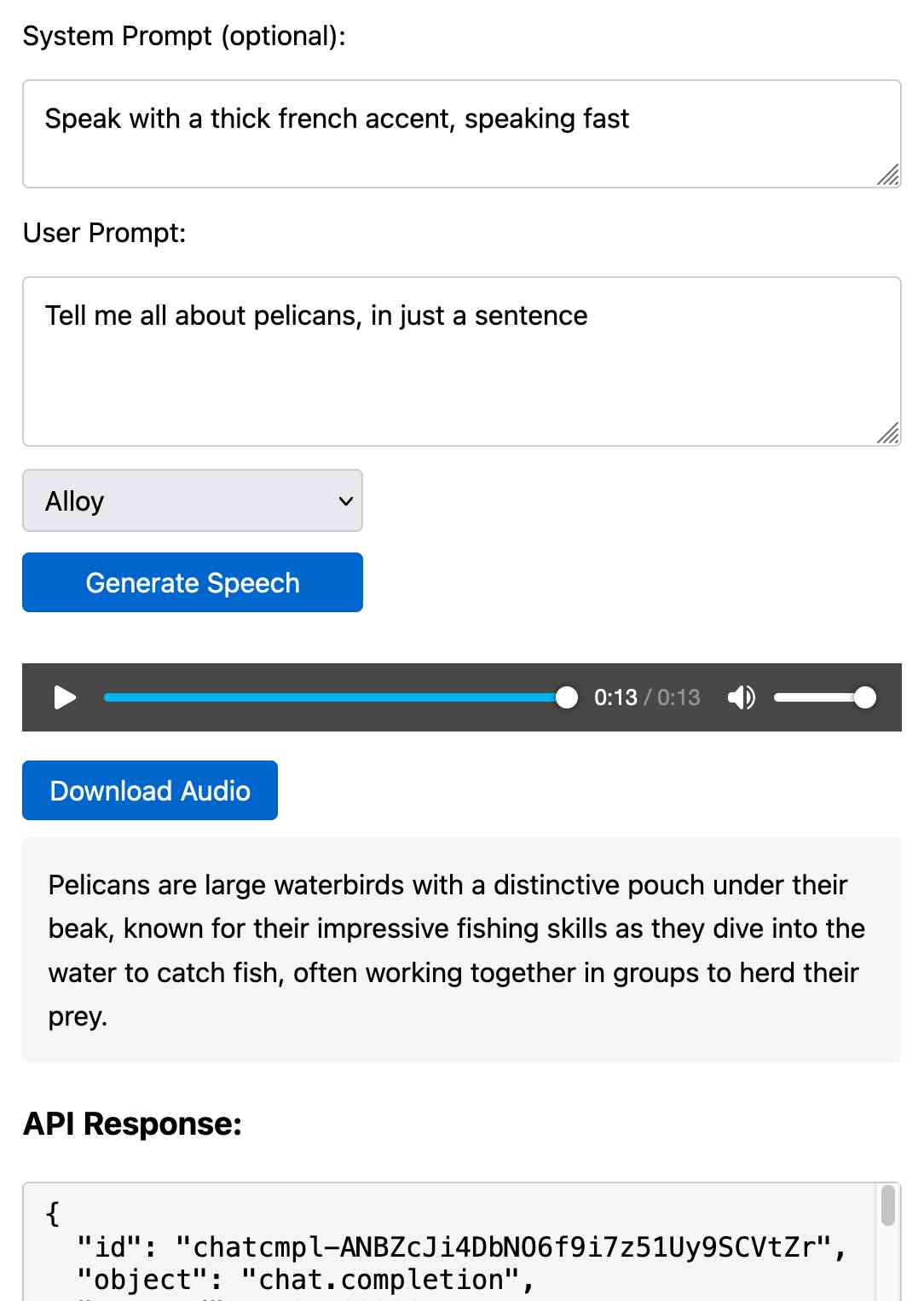
Once you've provided an API key (which is saved in localStorage) you can use this to prompt the gpt-4o-audio-preview model with a system and regular prompt and select a voice for the response.
I built it with assistance from Claude: initial app, adding system prompt support.
You can preview and download the resulting wav file, and you can also copy out the raw JSON. If you save that in a Gist you can then feed its Gist ID to https://tools.simonwillison.net/gpt-4o-audio-player?gist=GIST_ID_HERE (Claude transcript) to play it back again.
You can try using that to listen to my French accented pelican description.
There's something really interesting to me here about this form of application which exists entirely as HTML and JavaScript that uses CORS to talk to various APIs. GitHub's Gist API is accessible via CORS too, so it wouldn't take much more work to add a "save" button which writes out a new Gist after prompting for a personal access token. I prototyped that a bit here.
python-imgcat (via) I was investigating options for displaying images in a terminal window (for multi-modal logging output of LLM) and I found this neat Python library for displaying images using iTerm 2.
It includes a CLI tool, which means you can run it without installation using uvx like this:
uvx imgcat filename.png

Hugging Face Hub: Configure progress bars.
This has been driving me a little bit spare. Every time I try and build anything against a library that uses huggingface_hub somewhere under the hood to access models (most recently trying out MLX-VLM) I inevitably get output like this every single time I execute the model:
Fetching 11 files: 100%|██████████████████| 11/11 [00:00<00:00, 15871.12it/s]
I finally tracked down a solution, after many breakpoint() interceptions. You can fix it like this:
from huggingface_hub.utils import disable_progress_bars disable_progress_bars()
Or by setting the HF_HUB_DISABLE_PROGRESS_BARS environment variable, which in Python code looks like this:
os.environ["HF_HUB_DISABLE_PROGRESS_BARS"] = '1'
If you want to make a good RAG tool that uses your documentation, you should start by making a search engine over those documents that would be good enough for a human to use themselves.