40 posts tagged “gemini” and “llm-release”
The Gemini family of multimodal LLMs developed by Google DeepMind.
2024
First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
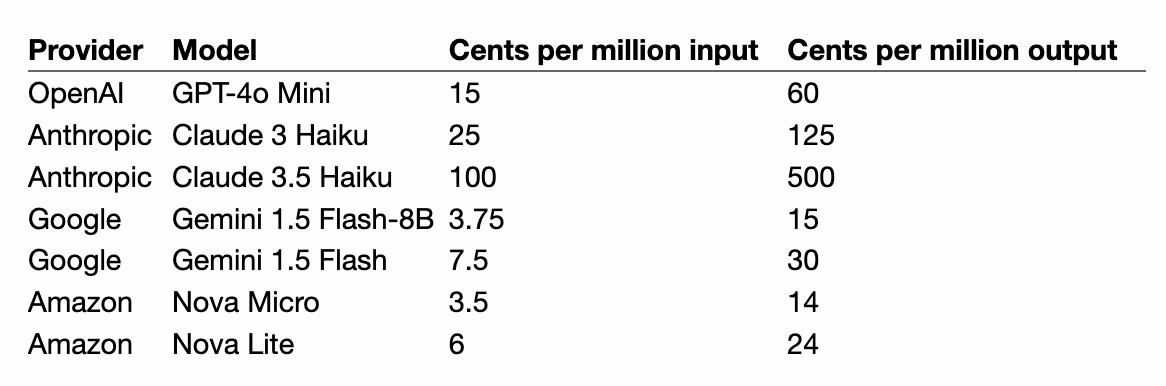
Amazon released three new Large Language Models yesterday at their AWS re:Invent conference. The new model family is called Amazon Nova and comes in three sizes: Micro, Lite and Pro.
[... 2,385 words]Say hello to gemini-exp-1121. Google Gemini's Logan Kilpatrick on Twitter:
Say hello to gemini-exp-1121! Our latest experimental gemini model, with:
- significant gains on coding performance
- stronger reasoning capabilities
- improved visual understanding
Available on Google AI Studio and the Gemini API right now
The 1121 in the name is a release date of the 21st November. This comes fast on the heels of last week's gemini-exp-1114.
Both of these new experimental Gemini models have seen moments at the top of the Chatbot Arena. gemini-exp-1114 took the top spot a few days ago, and then lost it to a new OpenAI model called "ChatGPT-4o-latest (2024-11-20)"... only for the new gemini-exp-1121 to hold the top spot right now.
(These model names are all so, so bad.)
I released llm-gemini 0.4.2 with support for the new model - this should have been 0.5 but I already have a 0.5a0 alpha that depends on an unreleased feature in LLM core.
I tried my pelican benchmark:
llm -m gemini-exp-1121 'Generate an SVG of a pelican riding a bicycle'

Since Gemini is a multi-modal vision model, I had it describe the image it had created back to me (by feeding it a PNG render):
llm -m gemini-exp-1121 describe -a pelican.png
And got this description, which is pretty great:
The image shows a simple, stylized drawing of an insect, possibly a bee or an ant, on a vehicle. The insect is composed of a large yellow circle for the body and a smaller yellow circle for the head. It has a black dot for an eye, a small orange oval for a beak or mouth, and thin black lines for antennae and legs. The insect is positioned on top of a simple black and white vehicle with two black wheels. The drawing is abstract and geometric, using basic shapes and a limited color palette of black, white, yellow, and orange.
Update: Logan confirmed on Twitter that these models currently only have a 32,000 token input, significantly less than the rest of the Gemini family.
Claude 3.5 Haiku
Anthropic released Claude 3.5 Haiku today, a few days later than expected (they said it would be out by the end of October).
[... 502 words]Gemini 1.5 Flash-8B is now production ready (via) Gemini 1.5 Flash-8B is "a smaller and faster variant of 1.5 Flash" - and is now released to production, at half the price of the 1.5 Flash model.
It's really, really cheap:
- $0.0375 per 1 million input tokens on prompts <128K
- $0.15 per 1 million output tokens on prompts <128K
- $0.01 per 1 million input tokens on cached prompts <128K
Prices are doubled for prompts longer than 128K.
I believe images are still charged at a flat rate of 258 tokens, which I think means a single non-cached image with Flash should cost 0.00097 cents - a number so tiny I'm doubting if I got the calculation right.
OpenAI's cheapest model remains GPT-4o mini, at $0.15/1M input - though that drops to half of that for reused prompt prefixes thanks to their new prompt caching feature (or by half if you use batches, though those can’t be combined with OpenAI prompt caching. Gemini also offer half-off for batched requests).
Anthropic's cheapest model is still Claude 3 Haiku at $0.25/M, though that drops to $0.03/M for cached tokens (if you configure them correctly).
I've released llm-gemini 0.2 with support for the new model:
llm install -U llm-gemini
llm keys set gemini
# Paste API key here
llm -m gemini-1.5-flash-8b-latest "say hi"
Updated production-ready Gemini models.
Two new models from Google Gemini today: gemini-1.5-pro-002 and gemini-1.5-flash-002. Their -latest aliases will update to these new models in "the next few days", and new -001 suffixes can be used to stick with the older models. The new models benchmark slightly better in various ways and should respond faster.
Flash continues to have a 1,048,576 input token and 8,192 output token limit. Pro is 2,097,152 input tokens.
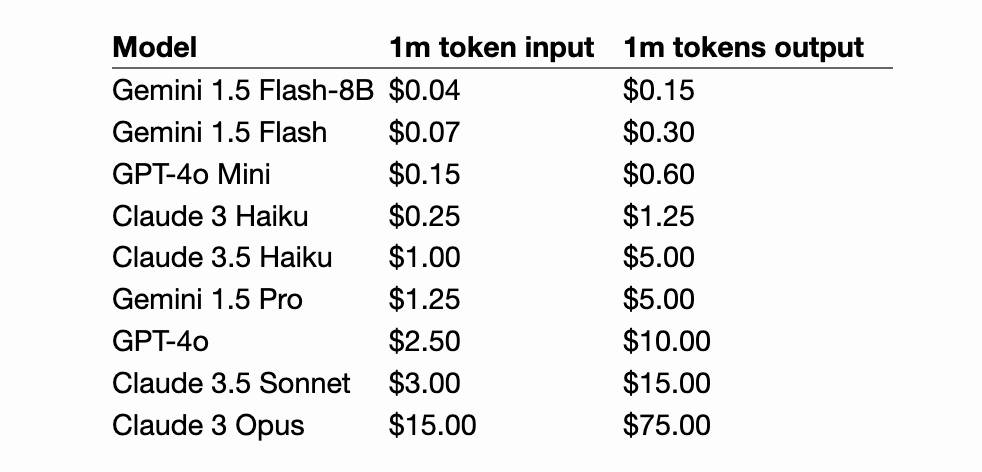
Google also announced a significant price reduction for Pro, effective on the 1st of October. Inputs less than 128,000 tokens drop from $3.50/million to $1.25/million (above 128,000 tokens it's dropping from $7 to $5) and output costs drop from $10.50/million to $2.50/million ($21 down to $10 for the >128,000 case).
For comparison, GPT-4o is currently $5/m input and $15/m output and Claude 3.5 Sonnet is $3/m input and $15/m output. Gemini 1.5 Pro was already the cheapest of the frontier models and now it's even cheaper.
Correction: I missed gpt-4o-2024-08-06 which is listed later on the OpenAI pricing page and priced at $2.50/m input and $10/m output. So the new Gemini 1.5 Pro prices are undercutting that.
Gemini has always offered finely grained safety filters - it sounds like those are now turned down to minimum by default, which is a welcome change:
For the models released today, the filters will not be applied by default so that developers can determine the configuration best suited for their use case.
Also interesting: they've tweaked the expected length of default responses:
For use cases like summarization, question answering, and extraction, the default output length of the updated models is ~5-20% shorter than previous models.
Gemini Chat App. Google released three new Gemini models today: improved versions of Gemini 1.5 Pro and Gemini 1.5 Flash plus a new model, Gemini 1.5 Flash-8B, which is significantly faster (and will presumably be cheaper) than the regular Flash model.
The Flash-8B model is described in the Gemini 1.5 family of models paper in section 8:
By inheriting the same core architecture, optimizations, and data mixture refinements as its larger counterpart, Flash-8B demonstrates multimodal capabilities with support for context window exceeding 1 million tokens. This unique combination of speed, quality, and capabilities represents a step function leap in the domain of single-digit billion parameter models.
While Flash-8B’s smaller form factor necessarily leads to a reduction in quality compared to Flash and 1.5 Pro, it unlocks substantial benefits, particularly in terms of high throughput and extremely low latency. This translates to affordable and timely large-scale multimodal deployments, facilitating novel use cases previously deemed infeasible due to resource constraints.
The new models are available in AI Studio, but since I built my own custom prompting tool against the Gemini CORS-enabled API the other day I figured I'd build a quick UI for these new models as well.
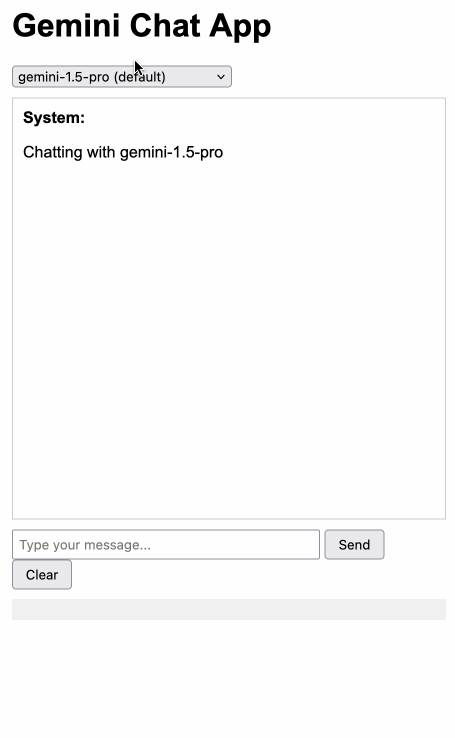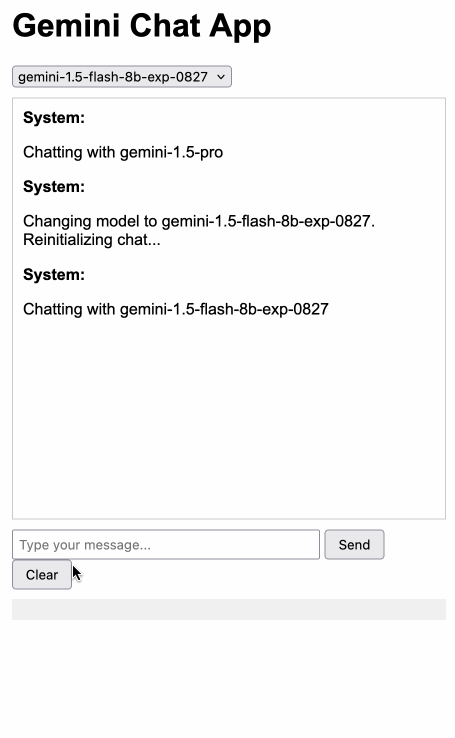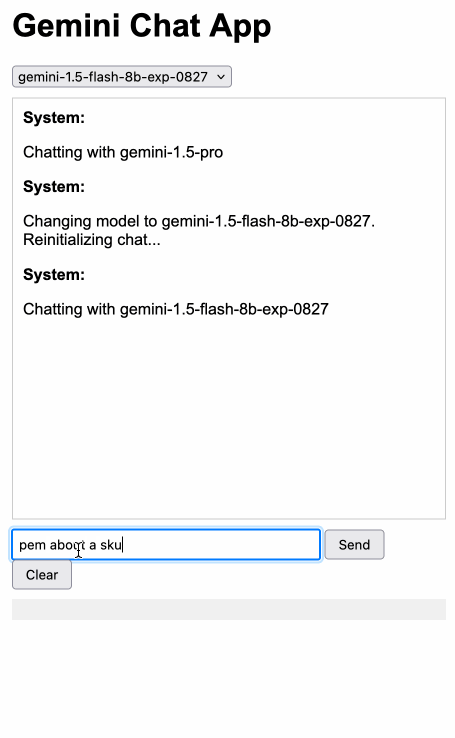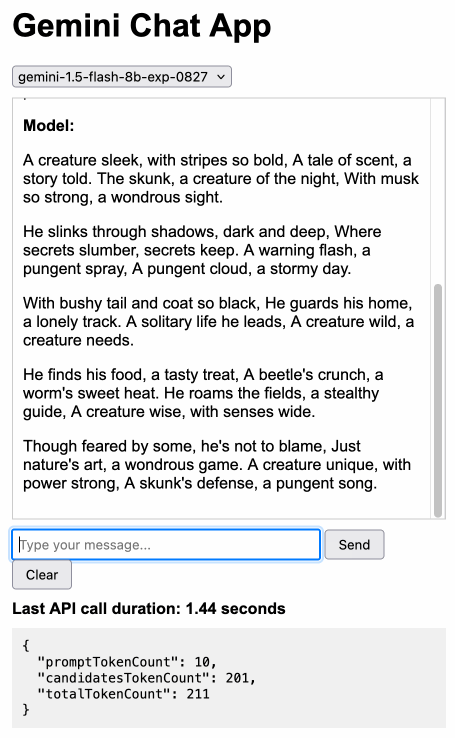
Building this with Claude 3.5 Sonnet took literally ten minutes from start to finish - you can see that from the timestamps in the conversation. Here's the deployed app and the finished code.
The feature I really wanted to build was streaming support. I started with this example code showing how to run streaming prompts in a Node.js application, then told Claude to figure out what the client-side code for that should look like based on a snippet from my bounding box interface hack. My starting prompt:
Build me a JavaScript app (no react) that I can use to chat with the Gemini model, using the above strategy for API key usage
I still keep hearing from people who are skeptical that AI-assisted programming like this has any value. It's honestly getting a little frustrating at this point - the gains for things like rapid prototyping are so self-evident now.
llm-gemini 0.1a4.
A new release of my llm-gemini plugin adding support for the Gemini 1.5 Flash model that was revealed this morning at Google I/O.
I'm excited about this new model because of its low price. Flash is $0.35 per 1 million tokens for prompts up to 128K token and $0.70 per 1 million tokens for longer prompts - up to a million tokens now and potentially two million at some point in the future. That's 1/10th of the price of Gemini Pro 1.5, cheaper than GPT 3.5 ($0.50/million) and only a little more expensive than Claude 3 Haiku ($0.25/million).
Three major LLM releases in 24 hours (plus weeknotes)
I’m a bit behind on my weeknotes, so there’s a lot to cover here. But first... a review of the last 24 hours of Large Language Model news. All times are in US Pacific on April 9th 2024.
[... 1,401 words]Gemini 1.5 Pro public preview (via) Huge release from Google: Gemini 1.5 Pro—the GPT-4 competitive model with the incredible 1 million token context length—is now available without a waitlist in 180+ countries (including the USA but not Europe or the UK as far as I can tell)... and the API is free for 50 requests/day (rate limited to 2/minute).
Beyond that you’ll need to pay—$7/million input tokens and $21/million output tokens, which is slightly less than GPT-4 Turbo and a little more than Claude 3 Sonnet.
They also announced audio input (up to 9.5 hours in a single prompt), system instruction support and a new JSON mode.
Our next-generation model: Gemini 1.5 (via) The big news here is about context length: Gemini 1.5 (a Mixture-of-Experts model) will do 128,000 tokens in general release, available in limited preview with a 1 million token context and has shown promising research results with 10 million tokens!
1 million tokens is 700,000 words or around 7 novels—also described in the blog post as an hour of video or 11 hours of audio.