Elsewhere
Release TIL Research Tool Museum Sighting
Filters: Sorted by date

I want Datasette Agent to be able to generate and execute Python code safely. This alpha is looking promising so far. GPT-5.5 has so far failed to break out of the sandbox!
Fixes for some limitations that emerged while I was trying to use this to build datasette-agent-micropython.

I'm at the Microsoft Build conference today, held at Fort Mason in San Francisco. There are California Brown Pelicans diving into the water directly behind venue!
I really like how you can paste a large volume of text into claude.ai (or the Claude desktop/mobile apps) and it will detect it as a large paste and turn it into a file attachment instead.
I decided to have Codex desktop build me a version of that as a prototype.
You can also open files directly - including images which will be shown as thumbnails - or drag files onto the textarea.
My latest sandboxing experiment: This alpha package bundles a lightly customized WASM build of MicroPython with a wrapper to execute code in it via wasmtime.
A minor bugfix release. Fixes a bug with INSERT ... RETURNING queries via the new /db/-/execute-write endpoint and a bunch of base_url issues which showed up when I was experimenting with Service Workers yesterday.





Datasette Lite is my version of Datasette that runs entirely in the browser using Pyodide in WebAssembly.
When I first built it four years ago I used Web Workers and code that intercepts navigation operations and fetches the generated HTML by running the Python app.
This worked, but had the disadvantage that any JavaScript in <script> tags would not be executed - breaking some Datasette functionality and a whole lot of Datasette plugins.
This morning I set Claude Opus 4.8 the task (in Claude Code for web) of figuring out how to run Python ASGI apps in Pyodide using Service Workers instead, and it seems to work! Here's a basic ASGI FastCGI demo and here's a demo that runs Datasette 1.0a31.
I'm still getting my head around exactly how it works, but once I've done that I plan to upgrade Datasette Lite itself.
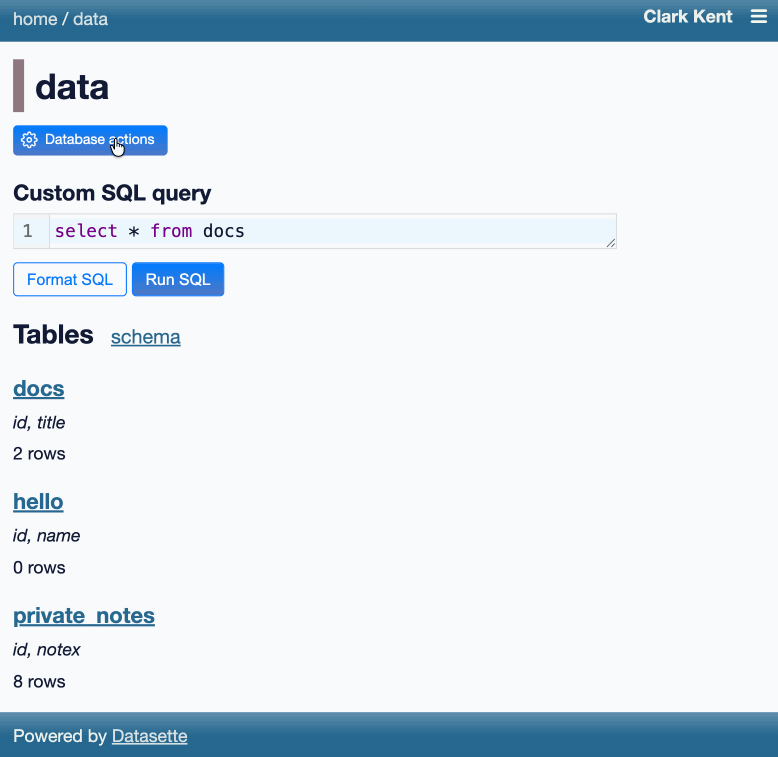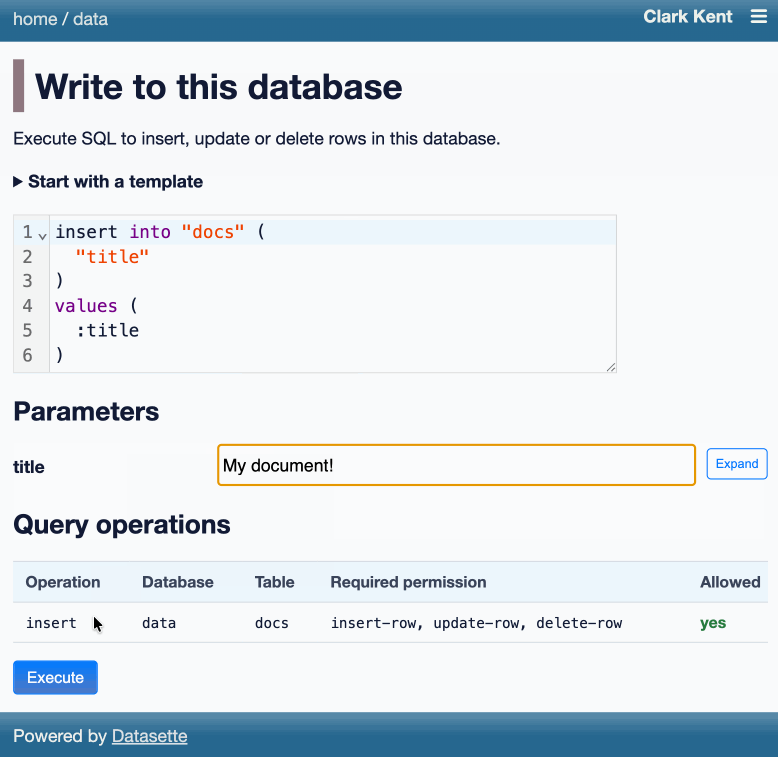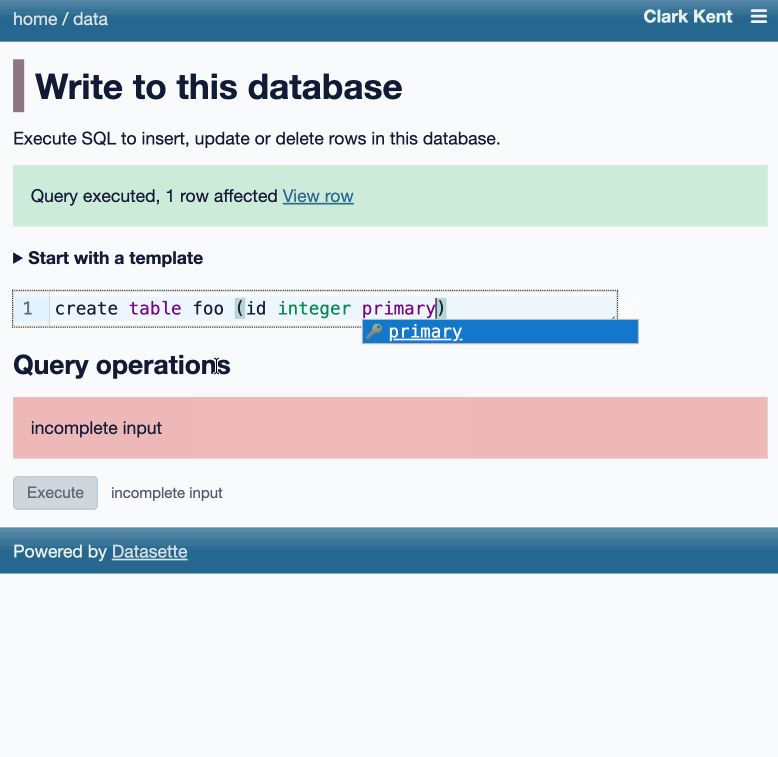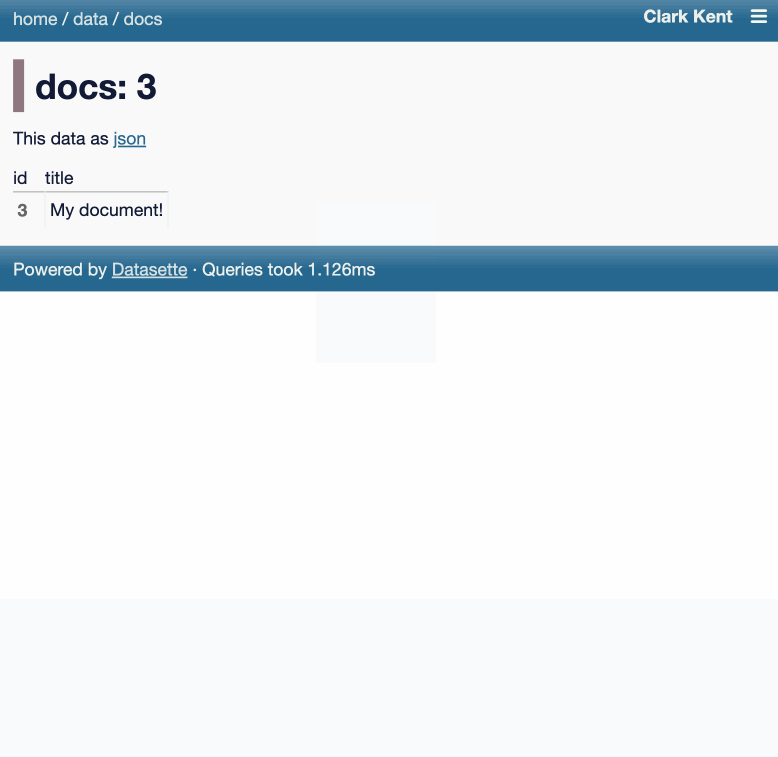
Another significant alpha release, with two new headline features.
Datasette now offers users with the necessary permissions the ability to both execute write queries against their database and to save stored queries (renamed from "canned queries") both privately and for use by other members of their Datasette instance.
There's more detail in SQL write queries and stored queries in Datasette 1.0a31 on the Datasette blog, which now has three posts introducing new features since the blog launched two weeks ago.
Here's an animated demo from the blog post showing how the new execute query interface lets people get started with templated insert/update/delete queries from tables they have permission to edit:
- New model: Claude Opus 4.8 (
claude-opus-4.8).- New
-o fast 1option for fast mode, for organizations with that feature enabled on their account.- Default max_tokens for each model now defaults to that model's maximum output rather than 8,192. #72
See also my notes on Opus 4.8 - I used this new release of llm-anthropic to generate the pelicans.
A slightly customized Markdown rendering tool with special treatment for fenced code SVG blocks - it both renders the image and provides a tab for switching to the code view.
You can paste in Markdown or give it a URL to a CORS-enabled Markdown file or Gist. Here's an example where it loads a Markdown file full of LLM pelican logs for Opus 4.8.






We took our new folding kayak out in the harbor and saw sea lions and harbor seals chilling on the docks.
The big new feature in this alpha is a new customizable "Jump to..." menu, described in detail in The extensible "Jump to" menu in Datasette 1.0a30 on the Datasette blog. You can try it out by hitting / on latest.datasette.io - it looks like this:

The new jump_items_sql() plugin hook allows plugins to add their own items to the set that's searched by the plugin.
Taking advantage of the new makeJumpSections() JavaScript plugin hook added in Datasette 1.0a30, datasette-agent now presents this "Start a new agent chat" interface as part of the Jump to menu, any time you hit /:
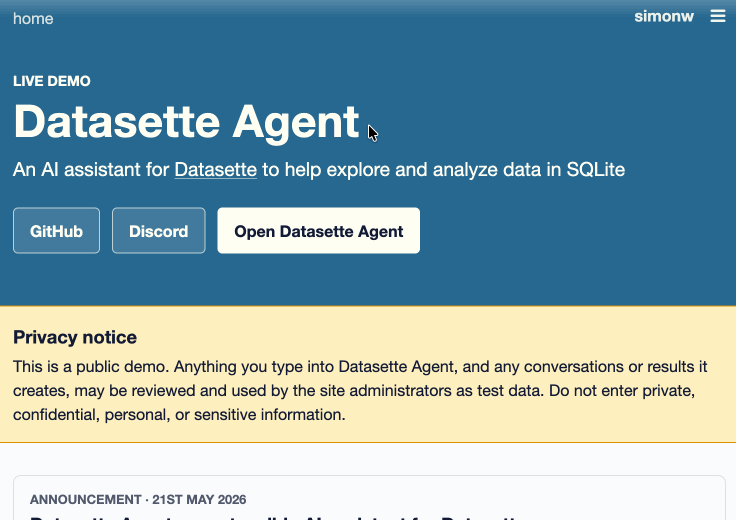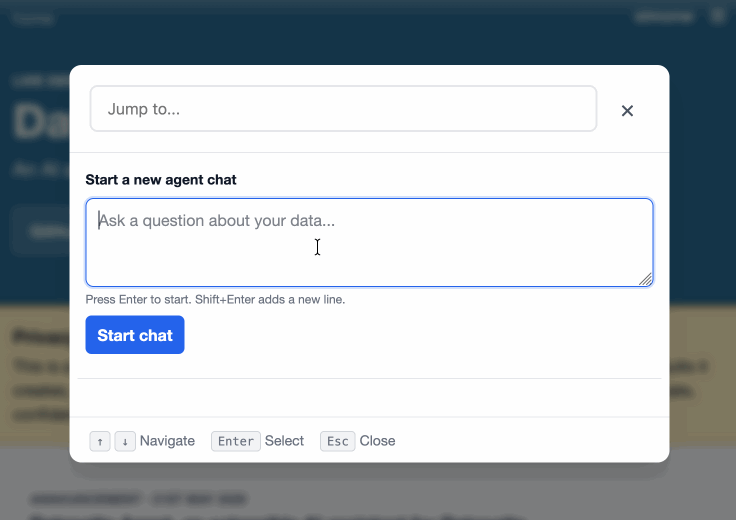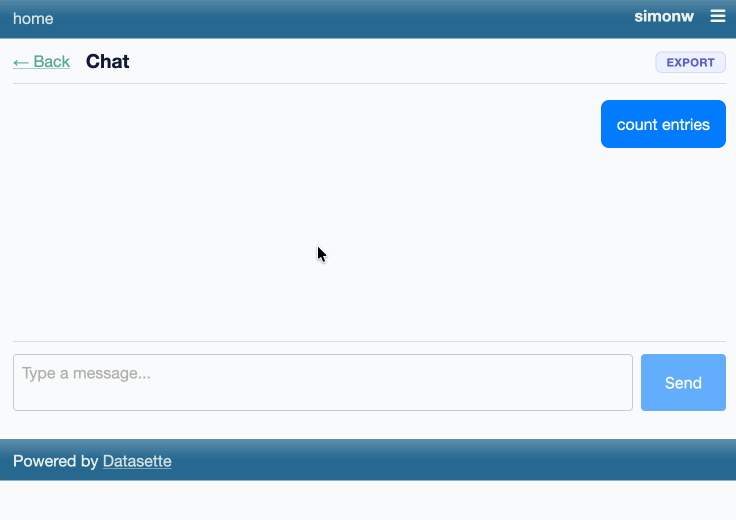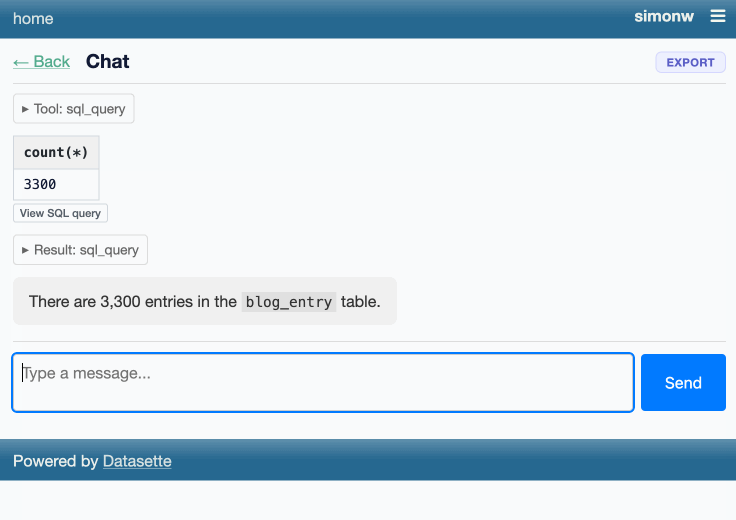
You can try this out by signing into agent.datasette.io using your GitHub account.
One of the smaller features in Datasette 1.0a30 is this:
New documented datasette.fixtures.populate_fixture_database(conn) helper for creating the fixture database tables used by Datasette's own tests, intended for plugin test suites.
This new plugin takes advantage of that API. You can try it out using uvx without even installing Datasette like this:
uvx --prerelease=allow \ --with datasette-fixtures datasette \ --get /fixtures/roadside_attractions.json
Which outputs:
{
"ok": true,
"next": null,
"rows": [
{"pk": 1, "name": "The Mystery Spot", "address": "465 Mystery Spot Road, Santa Cruz, CA 95065", "url": "https://www.mysteryspot.com/", "latitude": 37.0167, "longitude": -122.0024},
{"pk": 2, "name": "Winchester Mystery House", "address": "525 South Winchester Boulevard, San Jose, CA 95128", "url": "https://winchestermysteryhouse.com/", "latitude": 37.3184, "longitude": -121.9511},
{"pk": 3, "name": "Burlingame Museum of PEZ Memorabilia", "address": "214 California Drive, Burlingame, CA 94010", "url": null, "latitude": 37.5793, "longitude": -122.3442},
{"pk": 4, "name": "Bigfoot Discovery Museum", "address": "5497 Highway 9, Felton, CA 95018", "url": "https://www.bigfootdiscoveryproject.com/", "latitude": 37.0414, "longitude": -122.0725}
],
"truncated": false
}Via Hacker News I learned that UK publisher Usborne published free PDFs of their 1980s Computer Books, some of which I remember working through on my Commodore 64 as a child.
These were so great! Beautifully illustrated books with fun projects made up of code you could type into your own machine.
I remember playing "Mad House" typed in from the 1983 book "Creepy Computer Games", so I fed that PDF into Claude and had it build an interactive version of that game in JavaScript and HTML:
Build a vanilla JS artifact that exactly recreates the game Mad House from this book, make sure it's mobile friendly and has a suitable retro aesthetic
Credit the book title and link to https://usborne.com/us/books/computer-and-coding-books





It's been a few months since I last poked at Monty, the sandboxed subset of Python implemented in Rust. I had Claude Code look at the most recent release.
Importantly the max_duration_secs, max_memory, max_allocations, and max_recursion_depth settings all appear to work as advertised.
- Improved design of the
/-/llm-limitspage, now using the base template. #2- Now shown in application menu for users with the
datasette-llm-limits-viewpermission.
A Datasette Agent plugin for running commands in a Fly Sprites sandbox.
- "View SQL query" buttons below rendered charts.
- "View SQL query" buttons for both visible tables and collapsed SQL result tool calls.
- Don't display empty reasoning chunks
- Improved handling of truncated responses - table still displays to the user even if the SQL results were truncated when showing the agent.
See Datasette Agent, an extensible AI assistant for Datasette.







- More color! Bar and waffle charts without a color column are shaded by magnitude with a sequential color scheme; color columns holding text values use the
observable10categorical scheme. #2- Now checks
execute-sqlpermission before running the query to find the column names.- Charts now display interactive tooltips.
- Fixed a bug where
waffleYcharts were not described to the agent.
