Monday, 11th November 2024
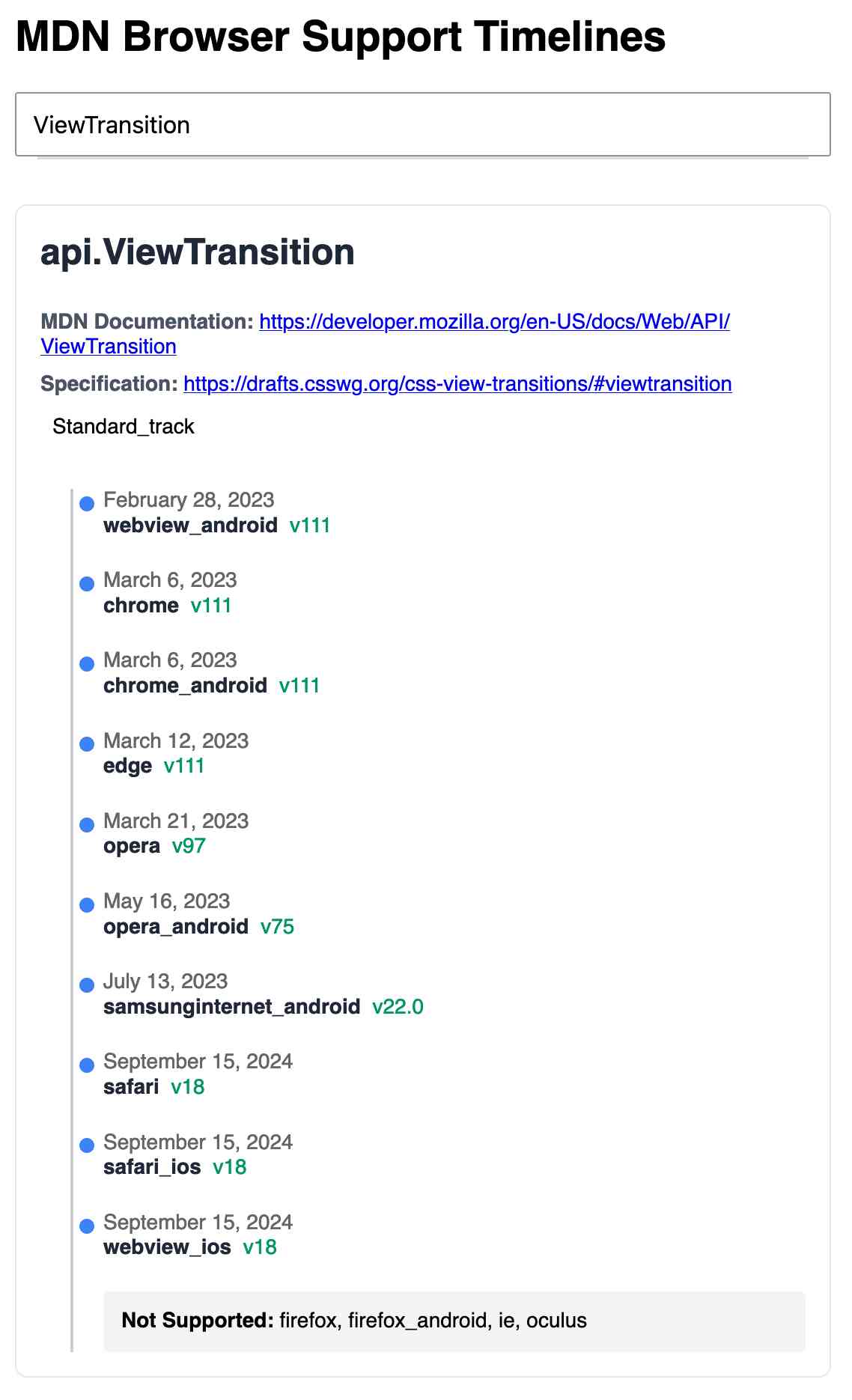
MDN Browser Support Timelines. I complained on Hacker News today that I wished the MDN browser compatibility ables - like this one for the Web Locks API - included an indication as to when each browser was released rather than just the browser numbers.
It turns out they do! If you click on each browser version in turn you can see an expanded area showing the browser release date:
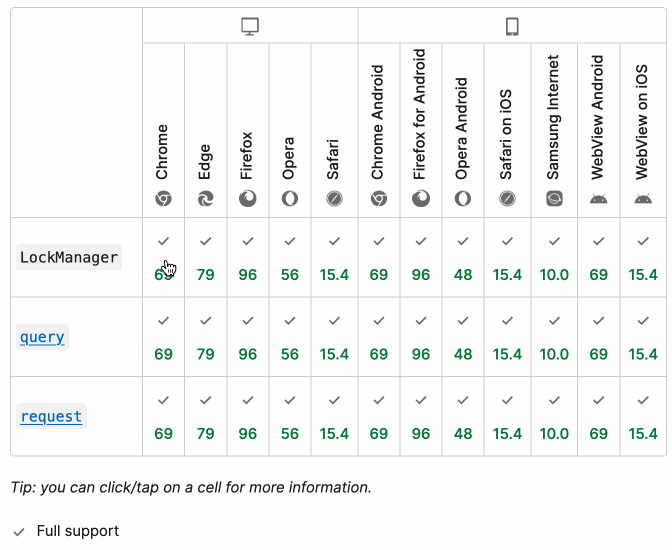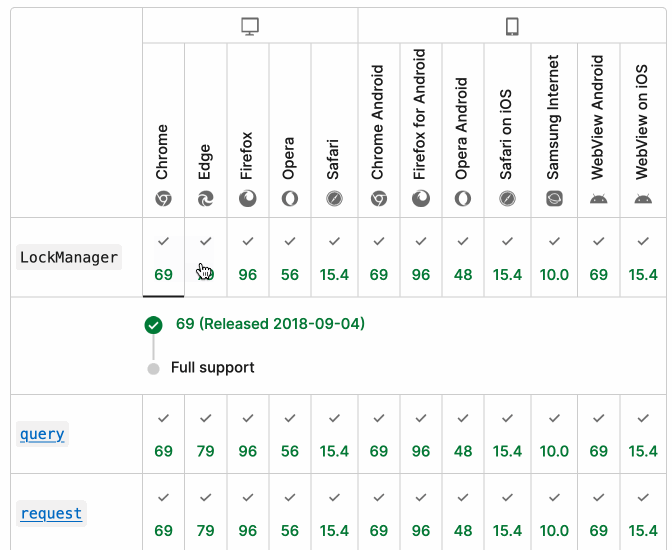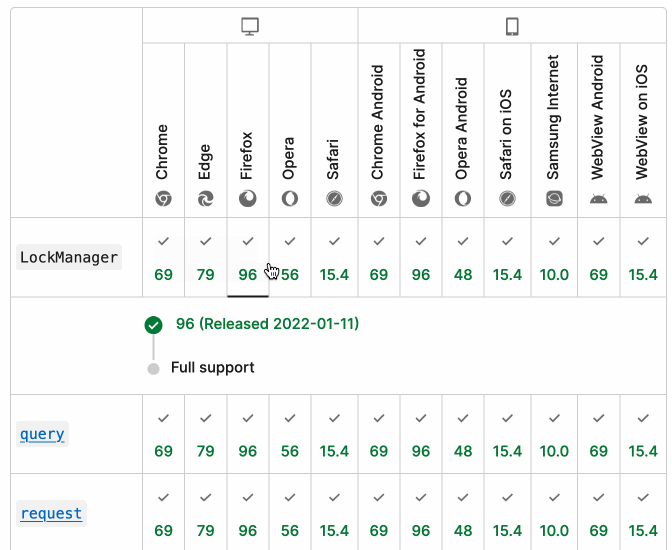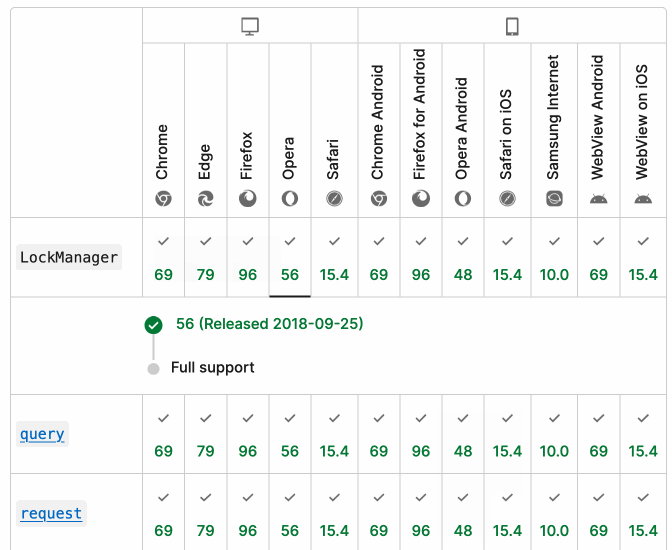
There's even an inline help tip telling you about the feature, which I've been studiously ignoring for years.
I want to see all the information at once without having to click through each browser. I had a poke around in the Firefox network tab and found https://bcd.developer.mozilla.org/bcd/api/v0/current/api.Lock.json - a JSON document containing browser support details (with release dates) for that API... and it was served using access-control-allow-origin: * which means I can hit it from my own little client-side applications.
I decided to build something with an autocomplete drop-down interface for selecting the API. That meant I'd need a list of all of the available APIs, and I used GitHub code search to find that in the mdn/browser-compat-data repository, in the api/ directory.
I needed the list of files in that directory for my autocomplete. Since there are just over 1,000 of those the regular GitHub contents API won't return them all, so I switched to the tree API instead.
Here's the finished tool - source code here:
95% of the code was written by LLMs, but I did a whole lot of assembly and iterating to get it to the finished state. Three of the transcripts for that:
- Web Locks API Browser Support Timeline in which I paste in the original API JSON and ask it to come up with a timeline visualization for it.
- Enhancing API Feature Display with URL Hash where I dumped in a more complex JSON example to get it to show multiple APIs on the same page, and also had it add
#fragmentbookmarking to the tool - Fetch GitHub API Data Hierarchy where I got it to write me an async JavaScript function for fetching a directory listing from that tree API.
As a junior engineer, there's simply no substitute for getting the first 100K lines of code under your belt. The "start over each day" method will help get you to those 100K lines faster.
You might think covering the same ground multiple times isn't as valuable as getting 100K diverse lines of code. I disagree. Solving the same problem repeatedly is actually really beneficial for retaining knowledge of patterns you figure out.
You only need 5K perfect lines to see all the major patterns once. The other 95K lines are repetition to rewire your neurons.
That development time acceleration of 4 days down to 20 minutes… that’s equivalent to about 10 years of Moore’s Law cycles. That is, using generative AI like this is equivalent to computers getting 10 years better overnight.
That was a real eye-opening framing for me. AI isn’t magical, it’s not sentient, it’s not the end of the world nor our saviour; we don’t need to endlessly debate “intelligence” or “reasoning.” It’s just that… computers got 10 years better. The iPhone was first released in 2007. Imagine if it had come out in 1997 instead. We wouldn’t even know what to do with it.
Binary vector embeddings are so cool (via) Evan Schwartz:
Vector embeddings by themselves are pretty neat. Binary quantized vector embeddings are extra impressive. In short, they can retain 95+% retrieval accuracy with 32x compression and ~25x retrieval speedup.
It's so unintuitive how well this trick works: take a vector of 1024x4 byte floating point numbers (4096 bytes = 32,768 bits), turn that into an array of single bits for > 0 or <= 0 which reduces it to just 1024 bits or 128 bytes - a 1/32 reduction.
Now you can compare vectors using a simple Hamming distance - a count of the number of bits that differ - and yet still get embedding similarity scores that are only around 10% less accurate than if you had used the much larger floating point numbers.
Evan digs into models that this works for, which include OpenAI's text-embedding-3-large and the small but powerful all-MiniLM-L6-v2.
How I ship projects at big tech companies (via) This piece by Sean Goedecke on shipping features at larger tech companies is fantastic.
Why do so many engineers think shipping is easy? I know it sounds extreme, but I think many engineers do not understand what shipping even is inside a large tech company. What does it mean to ship? It does not mean deploying code or even making a feature available to users. Shipping is a social construct within a company. Concretely, that means that a project is shipped when the important people at your company believe it is shipped.
Sean emphasizes communication, building confidence and gaining trust and the importance of deploying previews of the feature (for example using feature flags) as early as possible to get that crucial internal buy-in and feedback from other teams.
I think a lot of engineers hold off on deploys essentially out of fear. If you want to ship, you need to do the exact opposite: you need to deploy as much as you can as early as possible, and you need to do the scariest changes as early as you can possibly do them. Remember that you have the most end-to-end context on the project, which means you should be the least scared of scary changes.