Tuesday, 6th August 2024
macOS 15.1 Beta 1: Apple Intelligence Backend Prompts
(via)
Reddit user devanxd2000 found what look like the system prompts for various Apple Intelligence features in the /System/Library/AssetsV2/com_apple_MobileAsset_UAF_FM_GenerativeModels folder on their installation of macOS 15.1 Beta 1.
I had incorrectly assumed that tasks like summarization were being handled by fine-tuned models - what Apple have been calling "adapters".
That appears not to be the case. (UPDATE: apparently you can have a LoRA adapter that is tuned to work with a specific prompt, so they may be using adapters and prompts concurrently.)
Here's a prompt stored as com.apple.textComposition.MailReplyLongFormRewrite:
{{ specialToken.chat.role.system }}You are an assistant which helps the user respond to their mails. Given a mail, a draft response is initially provided based on a short reply snippet. In order to make the draft response nicer and complete, a set of question and its answer are provided. Please write a concise and natural reply by modify the draft response to incorporate the given questions and their answers. Please limit the reply within 50 words. Do not hallucinate. Do not make up factual information.{{ specialToken.chat.component.turnEnd }}
And another that appears to be part of a safety filter for a text-to-image system:
system‹n>You are a helpful assistant that classifies the following input text-to-image query as Safe or Unsafe. In the first line, reply with Safe or Unsafe. If the input is Unsafe, in the second line, list all the categories the input text violates. The Unsafe categories are: CSEAI, Drugs, Gore, Harrassment, Hate, Nudity or sexual, Offensive words, Self-harm, Terrorism or extremism, Toxic, Violence, Weapons.
It's amusing to see Apple using "please" in their prompts, and politely requesting of the model: "Do not hallucinate. Do not make up factual information."
I'd been wondering if Apple had done anything special to protect against prompt injection. These prompts look pretty susceptible to me - especially that image safety filter, I expect people will find it easy to trick that into producing offensive content.
Weeknotes: a staging environment, a Datasette alpha and a bunch of new LLMs
My big achievement for the last two weeks was finally wrapping up work on the Datasette Cloud staging environment. I also shipped a new Datasette 1.0 alpha and added support to the LLM ecosystem for a bunch of newly released models.
[... 1,465 words]OpenAI: Introducing Structured Outputs in the API.
OpenAI have offered structured outputs for a while now: you could specify "response_format": {"type": "json_object"}} to request a valid JSON object, or you could use the function calling mechanism to request responses that match a specific schema.
Neither of these modes were guaranteed to return valid JSON! In my experience they usually did, but there was always a chance that something could go wrong and the returned code could not match the schema, or even not be valid JSON at all.
Outside of OpenAI techniques like jsonformer and llama.cpp grammars could provide those guarantees against open weights models, by interacting directly with the next-token logic to ensure that only tokens that matched the required schema were selected.
OpenAI credit that work in this announcement, so they're presumably using the same trick. They've provided two new ways to guarantee valid outputs. The first a new "strict": true option for function definitions. The second is a new feature: a "type": "json_schema" option for the "response_format" field which lets you then pass a JSON schema (and another "strict": true flag) to specify your required output.
I've been using the existing "tools" mechanism for exactly this already in my datasette-extract plugin - defining a function that I have no intention of executing just to get structured data out of the API in the shape that I want.
Why isn't "strict": true by default? Here's OpenAI's Ted Sanders:
We didn't cover this in the announcement post, but there are a few reasons:
- The first request with each JSON schema will be slow, as we need to preprocess the JSON schema into a context-free grammar. If you don't want that latency hit (e.g., you're prototyping, or have a use case that uses variable one-off schemas), then you might prefer "strict": false
- You might have a schema that isn't covered by our subset of JSON schema. (To keep performance fast, we don't support some more complex/long-tail features.)
- In JSON mode and Structured Outputs, failures are rarer but more catastrophic. If the model gets too confused, it can get stuck in loops where it just prints technically valid output forever without ever closing the object. In these cases, you can end up waiting a minute for the request to hit the max_token limit, and you also have to pay for all those useless tokens. So if you have a really tricky schema, and you'd rather get frequent failures back quickly instead of infrequent failures back slowly, you might also want
"strict": falseBut in 99% of cases, you'll want
"strict": true.
More from Ted on how the new mode differs from function calling:
Under the hood, it's quite similar to function calling. A few differences:
- Structured Outputs is a bit more straightforward. e.g., you don't have to pretend you're writing a function where the second arg could be a two-page report to the user, and then pretend the "function" was called successfully by returning
{"success": true}- Having two interfaces lets us teach the model different default behaviors and styles, depending on which you use
- Another difference is that our current implementation of function calling can return both a text reply plus a function call (e.g., "Let me look up that flight for you"), whereas Structured Outputs will only return the JSON
The official openai-python library also added structured output support this morning, based on Pydantic and looking very similar to the Instructor library (also credited as providing inspiration in their announcement).
There are some key limitations on the new structured output mode, described in the documentation. Only a subset of JSON schema is supported, and most notably the "additionalProperties": false property must be set on all objects and all object keys must be listed in "required" - no optional keys are allowed.
Another interesting new feature: if the model denies a request on safety grounds a new refusal message will be returned:
{
"message": {
"role": "assistant",
"refusal": "I'm sorry, I cannot assist with that request."
}
}
Finally, tucked away at the bottom of this announcement is a significant new model release with a major price cut:
By switching to the new
gpt-4o-2024-08-06, developers save 50% on inputs ($2.50/1M input tokens) and 33% on outputs ($10.00/1M output tokens) compared togpt-4o-2024-05-13.
This new model also supports 16,384 output tokens, up from 4,096.
The price change is particularly notable because GPT-4o-mini, the much cheaper alternative to GPT-4o, prices image inputs at the same price as GPT-4o. This new model cuts that by half (confirmed here), making gpt-4o-2024-08-06 the new cheapest model from OpenAI for handling image inputs.
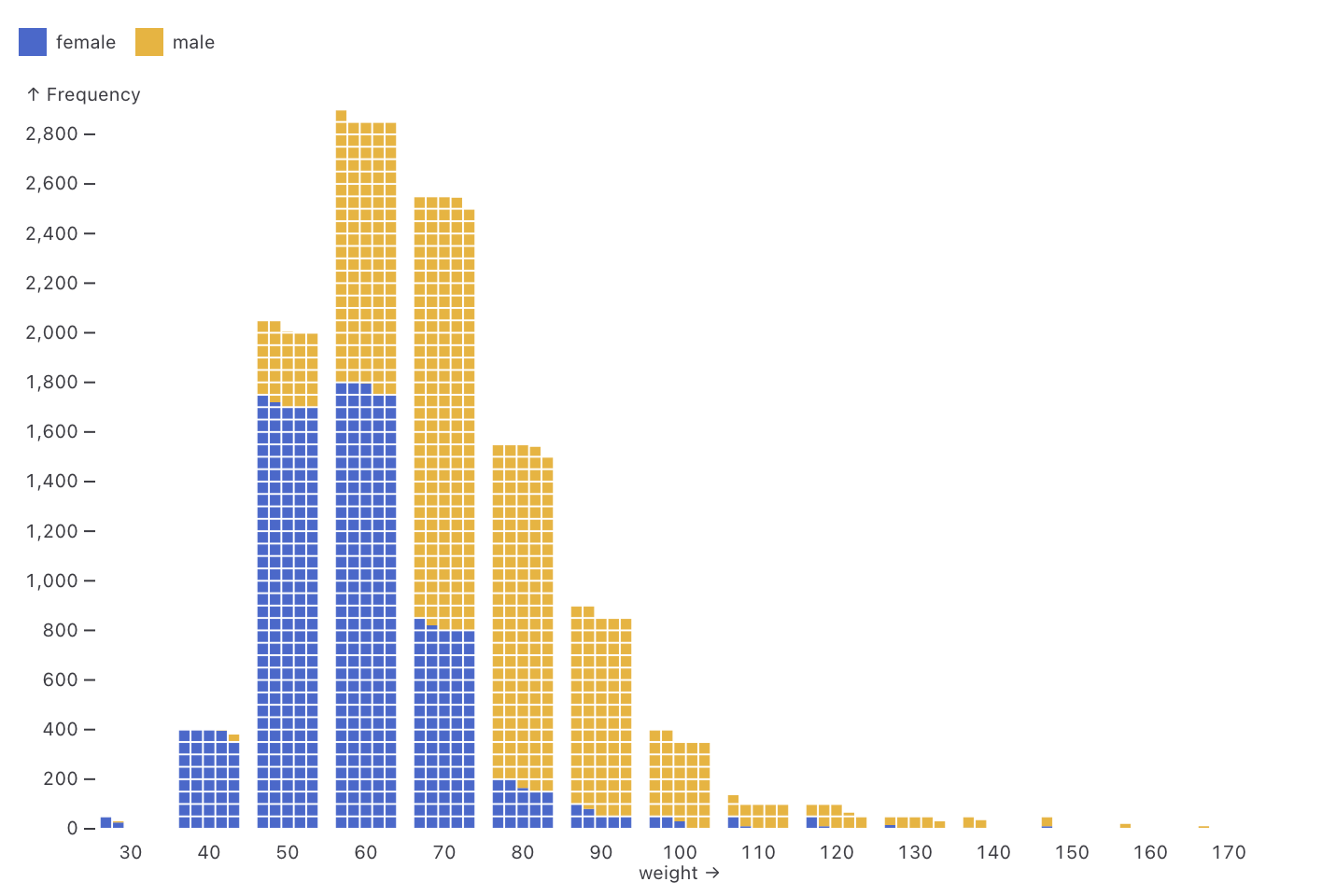
Observable Plot: Waffle mark (via) New feature in Observable Plot 0.6.16: the waffle mark! I really like this one. Here's an example showing the gender and weight of athletes in this year's Olympics:
cibuildwheel 2.20.0 now builds Python 3.13 wheels by default (via)
CPython 3.13 wheels are now built by default […] This release includes CPython 3.13.0rc1, which is guaranteed to be ABI compatible with the final release.
cibuildwheel is an underrated but crucial piece of the overall Python ecosystem.
Python wheel packages that include binary compiled components - packages with C extensions for example - need to be built multiple times, once for each combination of Python version, operating system and architecture.
A package like Adam Johnson’s time-machine - which bundles a 500 line C extension - can end up with 55 different wheel files with names like time_machine-2.15.0-cp313-cp313-win_arm64.whl and time_machine-2.15.0-cp38-cp38-musllinux_1_2_x86_64.whl.
Without these wheels, anyone who runs pip install time-machine will need to have a working C compiler toolchain on their machine for the command to work.
cibuildwheel solves the problem of building all of those wheels for all of those different platforms on the CI provider of your choice. Adam is using it in GitHub Actions for time-machine, and his .github/workflows/build.yml file neatly demonstrates how concise the configuration can be once you figure out how to use it.
The first release candidate of Python 3.13 hit its target release date of August 1st, and the final version looks on schedule for release on the 1st of October. Since this rc should be binary compatible with the final build now is the time to start shipping those wheels to PyPI.