Friday, 8th December 2023
We like to assume that automation technology will maintain or increase wage levels for a few skilled supervisors. But in the long-term skilled automation supervisors also tend to earn less.
Here's an example: In 1801 the Jacquard loom was invented, which automated silkweaving with punchcards. Around 1800, a manual weaver could earn 30 shillings/week. By the 1830s the same weaver would only earn around 5s/week. A Jacquard operator earned 15s/week, but he was also 12x more productive.
The Jacquard operator upskilled and became an automation supervisor, but their wage still dropped. For manual weavers the wages dropped even more. If we believe assistive AI will deliver unseen productivity gains, we can assume that wage erosion will also be unprecedented.
Standard Webhooks 1.0.0 (via) A loose specification for implementing webhooks, put together by a technical steering committee that includes representatives from Zapier, Twilio and more.
These recommendations look great to me. Even if you don’t follow them precisely, this document is still worth reviewing any time you consider implementing webhooks—it covers a bunch of non-obvious challenges, such as responsible retry scheduling, thin-vs-thick hook payloads, authentication, custom HTTP headers and protecting against Server side request forgery attacks.
Weeknotes: datasette-enrichments, datasette-comments, sqlite-chronicle
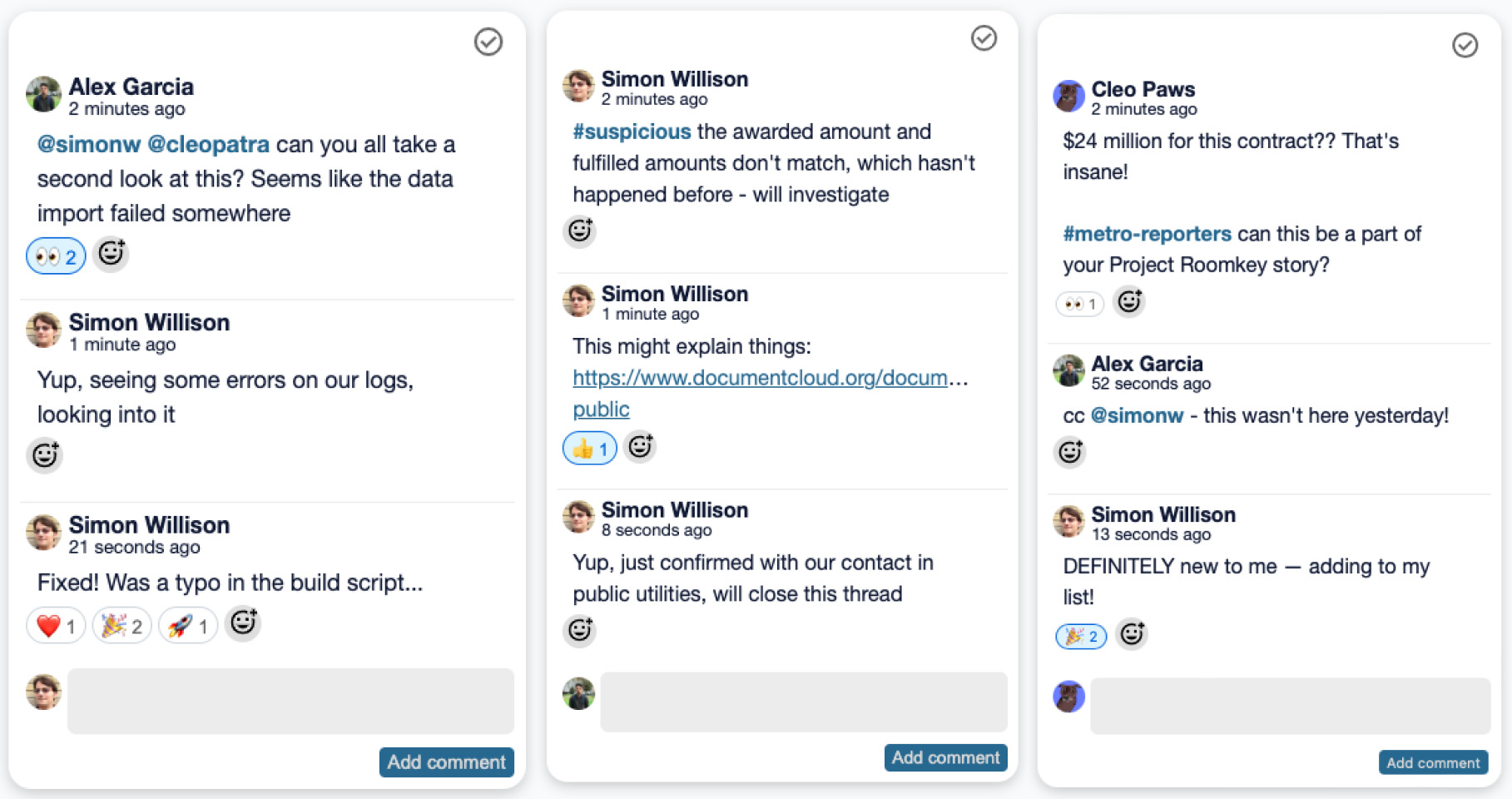
I’ve mainly been working on Datasette Enrichments and continuing to explore the possibilities enabled by sqlite-chronicle.
[... 1,123 words]Announcing Purple Llama: Towards open trust and safety in the new world of generative AI (via) New from Meta AI, Purple Llama is “an umbrella project featuring open trust and safety tools and evaluations meant to level the playing field for developers to responsibly deploy generative AI models and experiences”.
There are three components: a 27 page “Responsible Use Guide”, a new open model called Llama Guard and CyberSec Eval, “a set of cybersecurity safety evaluations benchmarks for LLMs”.
Disappointingly, despite this being an initiative around trustworthy LLM development,prompt injection is mentioned exactly once, in the Responsible Use Guide, with an incorrect description describing it as involving “attempts to circumvent content restrictions”!
The Llama Guard model is interesting: it’s a fine-tune of Llama 2 7B designed to help spot “toxic” content in input or output from a model, effectively an openly released alternative to OpenAI’s moderation API endpoint.
The CyberSec Eval benchmarks focus on two concepts: generation of insecure code, and preventing models from assisting attackers from generating new attacks. I don’t think either of those are anywhere near as important as prompt injection mitigation.
My hunch is that the reason prompt injection didn’t get much coverage in this is that, like the rest of us, Meta’s AI research teams have no idea how to fix it yet!
Create a culture that favors begging forgiveness (and reversing decisions quickly) rather than asking permission. Invest in infrastructure such as progressive / cancellable rollouts. Use asynchronous written docs to get people aligned (“comment in this doc by Friday if you disagree with the plan”) rather than meetings (“we’ll get approval at the next weekly review meeting”).