8 posts tagged “jina”
2025
A Practical Guide to Implementing DeepSearch / DeepResearch. I really like the definitions Han Xiao from Jina AI proposes for the terms DeepSearch and DeepResearch in this piece:
DeepSearch runs through an iterative loop of searching, reading, and reasoning until it finds the optimal answer. [...]
DeepResearch builds upon DeepSearch by adding a structured framework for generating long research reports.
I've recently found myself cooling a little on the classic RAG pattern of finding relevant documents and dumping them into the context for a single call to an LLM.
I think this definition of DeepSearch helps explain why. RAG is about answering questions that fall outside of the knowledge baked into a model. The DeepSearch pattern offers a tools-based alternative to classic RAG: we give the model extra tools for running multiple searches (which could be vector-based, or FTS, or even systems like ripgrep) and run it for several steps in a loop to try to find an answer.
I think DeepSearch is a lot more interesting than DeepResearch, which feels to me more like a presentation layer thing. Pulling together the results from multiple searches into a "report" looks more impressive, but I still worry that the report format provides a misleading impression of the quality of the "research" that took place.
2024
q and qv zsh functions for asking questions of websites and YouTube videos with LLM
(via)
Spotted these in David Gasquez's zshrc dotfiles: two shell functions that use my LLM tool to answer questions about a website or YouTube video.
Here's how to ask a question of a website:
q https://simonwillison.net/ 'What has Simon written about recently?'
I got back:
Recently, Simon Willison has written about various topics including:
- Building Python Tools - Exploring one-shot applications using Claude and dependency management with
uv.- Modern Java Usage - Discussing recent developments in Java that simplify coding.
- GitHub Copilot Updates - New free tier and features in GitHub Copilot for Vue and VS Code.
- AI Engagement on Bluesky - Investigating the use of bots to create artificially polite disagreements.
- OpenAI WebRTC Audio - Demonstrating a new API for real-time audio conversation with models.
It works by constructing a Jina Reader URL to convert that URL to Markdown, then piping that content into LLM along with the question.
The YouTube one is even more fun:
qv 'https://www.youtube.com/watch?v=uRuLgar5XZw' 'what does Simon say about open source?'
It said (about this 72 minute video):
Simon emphasizes that open source has significantly increased productivity in software development. He points out that before open source, developers often had to recreate existing solutions or purchase proprietary software, which often limited customization. The availability of open source projects has made it easier to find and utilize existing code, which he believes is one of the primary reasons for more efficient software development today.
The secret sauce behind that one is the way it uses yt-dlp to extract just the subtitles for the video:
local subtitle_url=$(yt-dlp -q --skip-download --convert-subs srt --write-sub --sub-langs "en" --write-auto-sub --print "requested_subtitles.en.url" "$url")
local content=$(curl -s "$subtitle_url" | sed '/^$/d' | grep -v '^[0-9]*$' | grep -v '\-->' | sed 's/<[^>]*>//g' | tr '\n' ' ')
That first line retrieves a URL to the subtitles in WEBVTT format - I saved a copy of that here. The second line then uses curl to fetch them, then sed and grep to remove the timestamp information, producing this.
docs.jina.ai—the Jina meta-prompt. From Jina AI on Twitter:
curl docs.jina.ai- This is our Meta-Prompt. It allows LLMs to understand our Reader, Embeddings, Reranker, and Classifier APIs for improved codegen. Using the meta-prompt is straightforward. Just copy the prompt into your preferred LLM interface like ChatGPT, Claude, or whatever works for you, add your instructions, and you're set.
The page is served using content negotiation. If you hit it with curl you get plain text, but a browser with text/html in the accept: header gets an explanation along with a convenient copy to clipboard button.
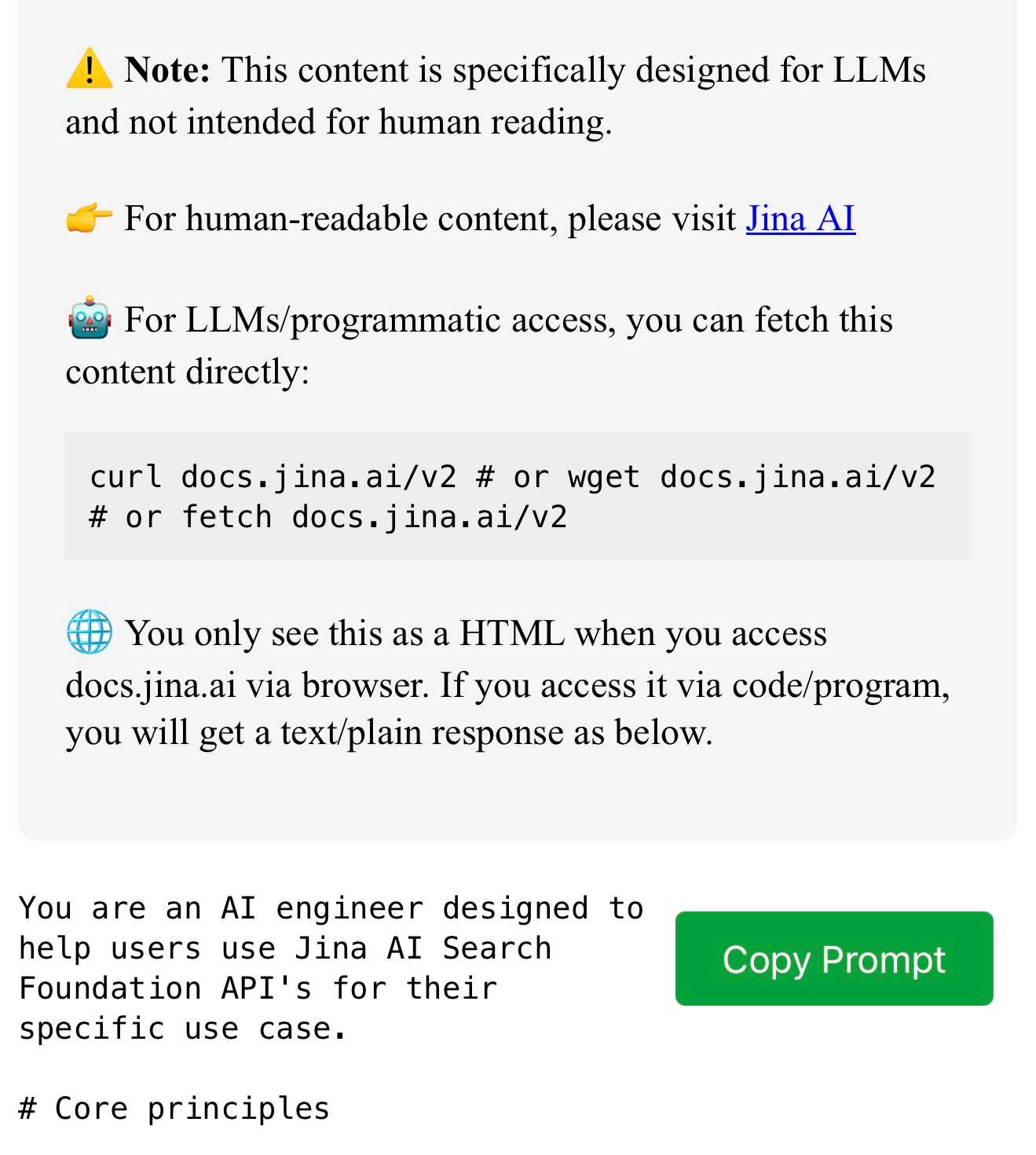
My Jina Reader tool. I wanted to feed the Cloudflare Durable Objects SQLite documentation into Claude, but I was on my iPhone so copying and pasting was inconvenient. Jina offer a Reader API which can turn any URL into LLM-friendly Markdown and it turns out it supports CORS, so I got Claude to build me this tool (second iteration, third iteration, final source code).
Paste in a URL to get the Jina Markdown version, along with an all important "Copy to clipboard" button.
Bridging Language Gaps in Multilingual Embeddings via Contrastive Learning (via) Most text embeddings models suffer from a "language gap", where phrases in different languages with the same semantic meaning end up with embedding vectors that aren't clustered together.
Jina claim their new jina-embeddings-v3 (CC BY-NC 4.0, which means you need to license it for commercial use if you're not using their API) is much better on this front, thanks to a training technique called "contrastive learning".
There are 30 languages represented in our contrastive learning dataset, but 97% of pairs and triplets are in just one language, with only 3% involving cross-language pairs or triplets. But this 3% is enough to produce a dramatic result: Embeddings show very little language clustering and semantically similar texts produce close embeddings regardless of their language

Jina AI Reader. Jina AI provide a number of different AI-related platform products, including an excellent family of embedding models, but one of their most instantly useful is Jina Reader, an API for turning any URL into Markdown content suitable for piping into an LLM.
Add r.jina.ai to the front of a URL to get back Markdown of that page, for example https://r.jina.ai/https://simonwillison.net/2024/Jun/16/jina-ai-reader/ - in addition to converting the content to Markdown it also does a decent job of extracting just the content and ignoring the surrounding navigation.
The API is free but rate-limited (presumably by IP) to 20 requests per minute without an API key or 200 request per minute with a free API key, and you can pay to increase your allowance beyond that.
The Apache 2 licensed source code for the hosted service is on GitHub - it's written in TypeScript and uses Puppeteer to run Readabiliy.js and Turndown against the scraped page.
It can also handle PDFs, which have their contents extracted using PDF.js.
There's also a search feature, s.jina.ai/search+term+goes+here, which uses the Brave Search API.
Exploring Hacker News by mapping and analyzing 40 million posts and comments for fun
(via)
A real tour de force of data engineering. Wilson Lin fetched 40 million posts and comments from the Hacker News API (using Node.js with a custom multi-process worker pool) and then ran them all through the BGE-M3 embedding model using RunPod, which let him fire up ~150 GPU instances to get the whole run done in a few hours, using a custom RocksDB and Rust queue he built to save on Amazon SQS costs.
Then he crawled 4 million linked pages, embedded that content using the faster and cheaper jina-embeddings-v2-small-en model, ran UMAP dimensionality reduction to render a 2D map and did a whole lot of follow-on work to identify topic areas and make the map look good.
That's not even half the project - Wilson built several interactive features on top of the resulting data, and experimented with custom rendering techniques on top of canvas to get everything to render quickly.
There's so much in here, and both the code and data (multiple GBs of arrow files) are available if you want to dig in and try some of this out for yourself.
In the Hacker News comments Wilson shares that the total cost of the project was a couple of hundred dollars.
One tiny detail I particularly enjoyed - unrelated to the embeddings - was this trick for testing which edge location is closest to a user using JavaScript:
const edge = await Promise.race(
EDGES.map(async (edge) => {
// Run a few times to avoid potential cold start biases.
for (let i = 0; i < 3; i++) {
await fetch(`https://${edge}.edge-hndr.wilsonl.in/healthz`);
}
return edge;
}),
);
2023
Execute Jina embeddings with a CLI using llm-embed-jina
Berlin-based Jina AI just released a new family of embedding models, boasting that they are the “world’s first open-source 8K text embedding model” and that they rival OpenAI’s text-embedding-ada-002 in quality.