Friday, 12th September 2025
Qwen3-Next-80B-A3B. Qwen announced two new models via their Twitter account (and here's their blog): Qwen3-Next-80B-A3B-Instruct and Qwen3-Next-80B-A3B-Thinking.
They make some big claims on performance:
- Qwen3-Next-80B-A3B-Instruct approaches our 235B flagship.
- Qwen3-Next-80B-A3B-Thinking outperforms Gemini-2.5-Flash-Thinking.
The name "80B-A3B" indicates 80 billion parameters of which only 3 billion are active at a time. You still need to have enough GPU-accessible RAM to hold all 80 billion in memory at once but only 3 billion will be used for each round of inference, which provides a significant speedup in responding to prompts.
More details from their tweet:
- 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!)
- Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed & recall
- Ultra-sparse MoE: 512 experts, 10 routed + 1 shared
- Multi-Token Prediction → turbo-charged speculative decoding
- Beats Qwen3-32B in perf, rivals Qwen3-235B in reasoning & long-context
The models on Hugging Face are around 150GB each so I decided to try them out via OpenRouter rather than on my own laptop (Thinking, Instruct).
I'm used my llm-openrouter plugin. I installed it like this:
llm install llm-openrouter
llm keys set openrouter
# paste key here
Then found the model IDs with this command:
llm models -q next
Which output:
OpenRouter: openrouter/qwen/qwen3-next-80b-a3b-thinking
OpenRouter: openrouter/qwen/qwen3-next-80b-a3b-instruct
I have an LLM prompt template saved called pelican-svg which I created like this:
llm "Generate an SVG of a pelican riding a bicycle" --save pelican-svg
This means I can run my pelican benchmark like this:
llm -t pelican-svg -m openrouter/qwen/qwen3-next-80b-a3b-thinking
Or like this:
llm -t pelican-svg -m openrouter/qwen/qwen3-next-80b-a3b-instruct
Here's the thinking model output (exported with llm logs -c | pbcopy after I ran the prompt):
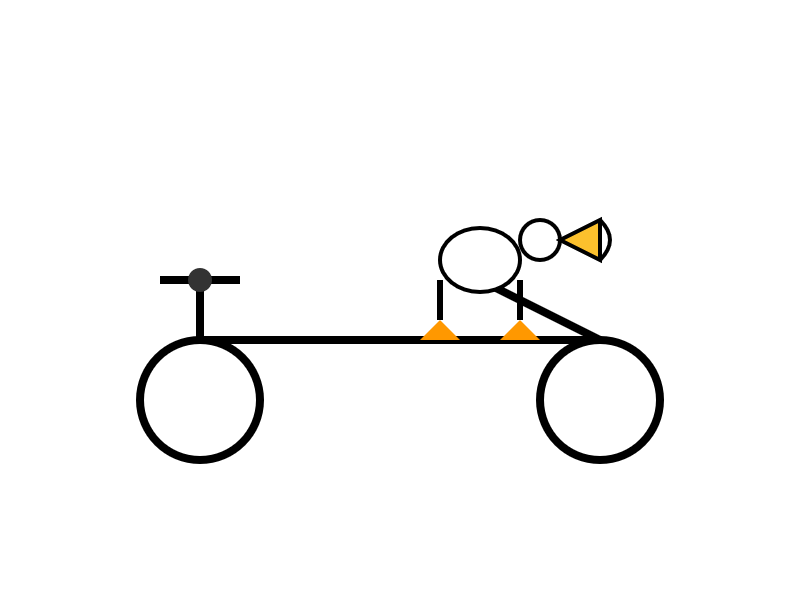
I enjoyed the "Whimsical style with smooth curves and friendly proportions (no anatomical accuracy needed for bicycle riding!)" note in the transcript.
The instruct (non-reasoning) model gave me this:

"🐧🦩 Who needs legs!?" indeed! I like that penguin-flamingo emoji sequence it's decided on for pelicans.
Claude Memory: A Different Philosophy (via) Shlok Khemani has been doing excellent work reverse-engineering LLM systems and documenting his discoveries.
Last week he wrote about ChatGPT memory. This week it's Claude.
Claude's memory system has two fundamental characteristics. First, it starts every conversation with a blank slate, without any preloaded user profiles or conversation history. Memory only activates when you explicitly invoke it. Second, Claude recalls by only referring to your raw conversation history. There are no AI-generated summaries or compressed profiles—just real-time searches through your actual past chats.
Claude's memory is implemented as two new function tools that are made available for a Claude to call. I confirmed this myself with the prompt "Show me a list of tools that you have available to you, duplicating their original names and descriptions" which gave me back these:
conversation_search: Search through past user conversations to find relevant context and information
recent_chats: Retrieve recent chat conversations with customizable sort order (chronological or reverse chronological), optional pagination using 'before' and 'after' datetime filters, and project filtering
The good news here is transparency - Claude's memory feature is implemented as visible tool calls, which means you can see exactly when and how it is accessing previous context.
This helps address my big complaint about ChatGPT memory (see I really don’t like ChatGPT’s new memory dossier back in May) - I like to understand as much as possible about what's going into my context so I can better anticipate how it is likely to affect the model.
The OpenAI system is very different: rather than letting the model decide when to access memory via tools, OpenAI instead automatically include details of previous conversations at the start of every conversation.
Shlok's notes on ChatGPT's memory did include one detail that I had previously missed that I find reassuring:
Recent Conversation Content is a history of your latest conversations with ChatGPT, each timestamped with topic and selected messages. [...] Interestingly, only the user's messages are surfaced, not the assistant's responses.
One of my big worries about memory was that it could harm my "clean slate" approach to chats: if I'm working on code and the model starts going down the wrong path (getting stuck in a bug loop for example) I'll start a fresh chat to wipe that rotten context away. I had worried that ChatGPT memory would bring that bad context along to the next chat, but omitting the LLM responses makes that much less of a risk than I had anticipated.
Update: Here's a slightly confusing twist: yesterday in Bringing memory to teams at work Anthropic revealed an additional memory feature, currently only available to Team and Enterprise accounts, with a feature checkbox labeled "Generate memory of chat history" that looks much more similar to the OpenAI implementation:
With memory, Claude focuses on learning your professional context and work patterns to maximize productivity. It remembers your team’s processes, client needs, project details, and priorities. [...]
Claude uses a memory summary to capture all its memories in one place for you to view and edit. In your settings, you can see exactly what Claude remembers from your conversations, and update the summary at any time by chatting with Claude.
I haven't experienced this feature myself yet as it isn't part of my Claude subscription. I'm glad to hear it's fully transparent and can be edited by the user, resolving another of my complaints about the ChatGPT implementation.
This version of Claude memory also takes Claude Projects into account:
If you use projects, Claude creates a separate memory for each project. This ensures that your product launch planning stays separate from client work, and confidential discussions remain separate from general operations.
I praised OpenAI for adding this a few weeks ago.
London Transport Museum Depot Open Days. I just found out about this (thanks, ChatGPT) and I'm heart-broken to learn that I'm in London a week too early! If you are in London next week (Thursday 18th through Sunday 21st 2025) you should definitely know about it:
The Museum Depot in Acton is our working museum store, and a treasure trove of over 320,000 objects.
Three times a year, we throw open the doors and welcome thousands of visitors to explore. Discover rare road and rail vehicles spanning over 100 years, signs, ceramic tiles, original posters, ephemera, ticket machines, and more.
And if you can go on Saturday 20th or Sunday 21st you can ride the small-scale railway there!
The Depot is also home to the London Transport Miniature Railway, a working miniature railway based on real London Underground locomotives, carriages, signals and signs run by our volunteers.
Note that this "miniature railway" is not the same thing as a model railway - it uses a 7¼ in gauge railway and you can sit on top of and ride the carriages.
The trick with Claude Code is to give it large, but not too large, extremely well defined problems.
(If the problems are too large then you are now vibe coding… which (a) frequently goes wrong, and (b) is a one-way street: once vibes enter your app, you end up with tangled, write-only code which functions perfectly but can no longer be edited by humans. Great for prototyping, bad for foundations.)
— Matt Webb, What I think about when I think about Claude Code
gpt-5 and gpt-5-mini rate limit updates. OpenAI have increased the rate limits for their two main GPT-5 models. These look significant:
gpt-5
Tier 1: 30K → 500K TPM (1.5M batch)
Tier 2: 450K → 1M (3M batch)
Tier 3: 800K → 2M
Tier 4: 2M → 4Mgpt-5-mini
Tier 1: 200K → 500K (5M batch)
GPT-5 rate limits here show tier 5 stays at 40M tokens per minute. The GPT-5 mini rate limits for tiers 2 through 5 are 2M, 4M, 10M and 180M TPM respectively.
As a reminder, those tiers are assigned based on how much money you have spent on the OpenAI API - from $5 for tier 1 up through $50, $100, $250 and then $1,000 for tier
For comparison, Anthropic's current top tier is Tier 4 ($400 spent) which provides 2M maximum input tokens per minute and 400,000 maximum output tokens, though you can contact their sales team for higher limits than that.
Gemini's top tier is Tier 3 for $1,000 spent and currently gives you 8M TPM for Gemini 2.5 Pro and Flash and 30M TPM for the Flash-Lite and 2.0 Flash models.
So OpenAI's new rate limit increases for their top performing model pulls them ahead of Anthropic but still leaves them significantly behind Gemini.
GPT-5 mini remains the champion for smaller models with that enormous 180M TPS limit for its top tier.