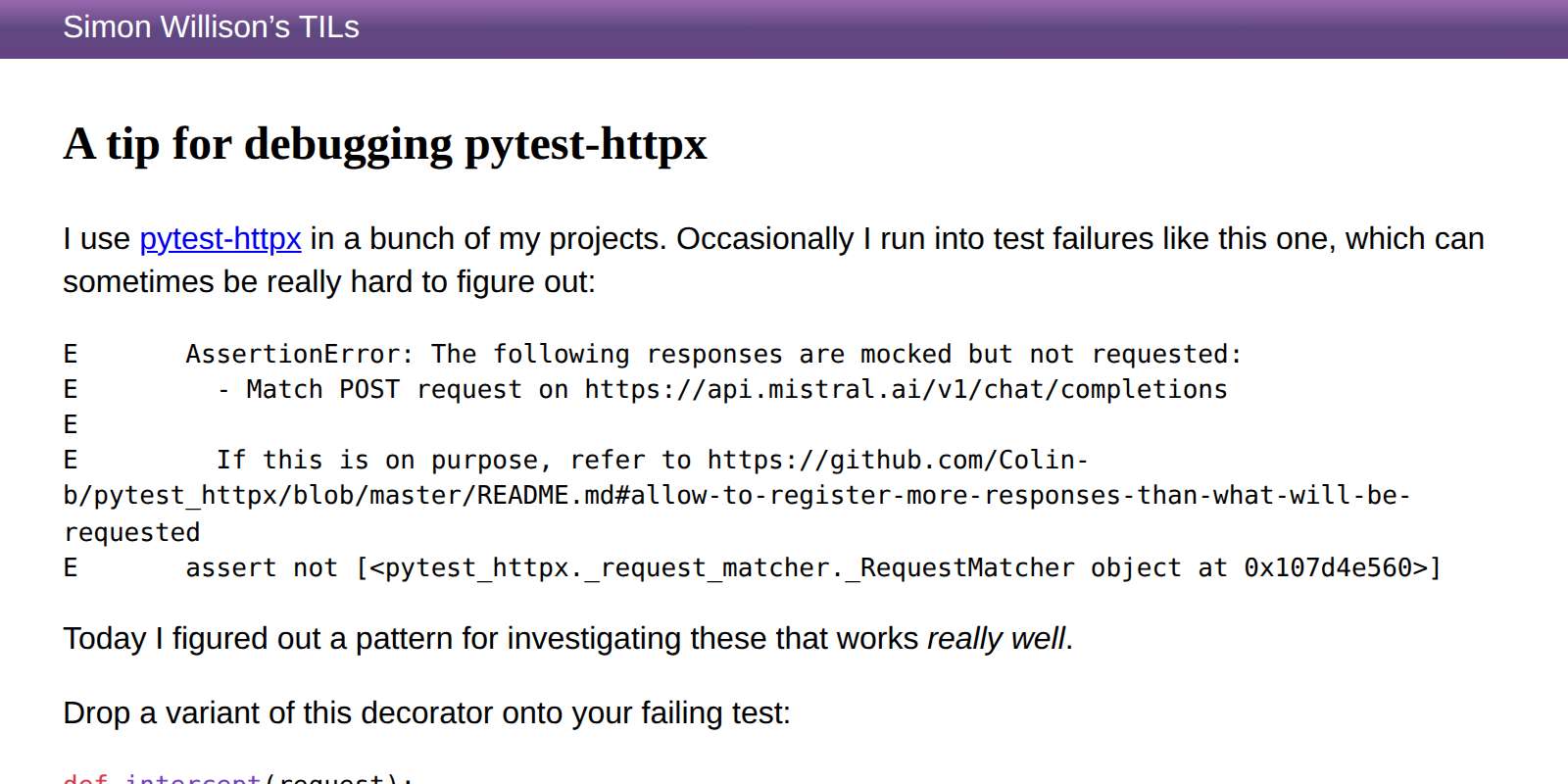
Wednesday, 28th May 2025
At Amazon, Some Coders Say Their Jobs Have Begun to Resemble Warehouse Work. I got a couple of quotes in this NYTimes story about internal resistance to Amazon's policy to encourage employees to make use of more generative AI:
“It’s more fun to write code than to read code,” said Simon Willison, an A.I. fan who is a longtime programmer and blogger, channeling the objections of other programmers. “If you’re told you have to do a code review, it’s never a fun part of the job. When you’re working with these tools, it’s most of the job.” [...]
It took me about 15 years of my career before I got over my dislike of reading code written by other people. It's a difficult skill to develop! I'm not surprised that a lot of people dislike AI-assisted programming paradigm when the end result is less time writing, more time reading!
“If you’re a prototyper, this is a gift from heaven,” Mr. Willison said. “You can knock something out that illustrates the idea.”
Rapid prototyping has been a key skill of mine for a long time. I love being able to bring half-baked illustrative prototypes of ideas to a meeting - my experience is that the quality of conversation goes up by an order of magnitude as a result of having something concrete for people to talk about.
These days I can vibe code a prototype in single digit minutes.
llm-llama-server 0.2. Here's a second option for using LLM's new tool support against local models (the first was via llm-ollama).
It turns out the llama.cpp ecosystem has pretty robust OpenAI-compatible tool support already, so my llm-llama-server plugin only needed a quick upgrade to get those working there.
Unfortunately it looks like streaming support doesn't work with tools in llama-server at the moment, so I added a new model ID called llama-server-tools which disables streaming and enables tools.
Here's how to try it out. First, ensure you have llama-server - the easiest way to get that on macOS is via Homebrew:
brew install llama.cpp
Start the server running like this. This command will download and cache the 3.2GB unsloth/gemma-3-4b-it-GGUF:Q4_K_XL if you don't yet have it:
llama-server --jinja -hf unsloth/gemma-3-4b-it-GGUF:Q4_K_XL
Then in another window:
llm install llm-llama-server
llm -m llama-server-tools -T llm_time 'what time is it?' --td
And since you don't even need an API key for this, even if you've never used LLM before you can try it out with this uvx one-liner:
uvx --with llm-llama-server llm -m llama-server-tools -T llm_time 'what time is it?' --td
For more notes on using llama.cpp with LLM see Trying out llama.cpp’s new vision support from a couple of weeks ago.
Here's a quick demo of the kind of casual things I use LLMs for on a daily basis.
I just found out that Perplexity offer their Deep Research feature via their API, through a model called Sonar Deep Research.
Their documentation includes an example response, which included this usage data in the JSON:
{"prompt_tokens": 19, "completion_tokens": 498, "total_tokens": 517, "citation_tokens": 10175, "num_search_queries": 48, "reasoning_tokens": 95305}
But how much would that actually cost?
Their pricing page lists the price for that model. I snapped this screenshot of the prices:

I could break out a calculator at this point, but I'm not quite curious enough to go through the extra effort.
So I pasted that screenshot into Claude along with the JSON and prompted:
{"prompt_tokens": 19, "completion_tokens": 498, "total_tokens": 517, "citation_tokens": 10175, "num_search_queries": 48, "reasoning_tokens": 95305}Calculate price, use javascript
I wanted to make sure Claude would use its JavaScript analysis tool, since LLMs can't do maths.
I watched Claude Sonnet 4 write 61 lines of JavaScript - keeping an eye on it to check it didn't do anything obviously wrong. The code spat out this output:
=== COST CALCULATIONS ===
Input tokens cost: 19 tokens × $2/million = $0.000038
Output tokens cost: 498 tokens × $8/million = $0.003984
Search queries cost: 48 queries × $5/1000 = $0.240000
Reasoning tokens cost: 95305 tokens × $3/million = $0.285915
=== COST SUMMARY ===
Input tokens: $0.000038
Output tokens: $0.003984
Search queries: $0.240000
Reasoning tokens: $0.285915
─────────────────────────
TOTAL COST: $0.529937
TOTAL COST: $0.5299 (rounded to 4 decimal places)
So that Deep Research API call would cost 53 cents! Curiosity satisfied in less than a minute.
Codestral Embed. Brand new embedding model from Mistral, specifically trained for code. Mistral claim that:
Codestral Embed significantly outperforms leading code embedders in the market today: Voyage Code 3, Cohere Embed v4.0 and OpenAI’s large embedding model.
The model is designed to work at different sizes. They show performance numbers for 256, 512, 1024 and 1546 sized vectors in binary (256 bits = 32 bytes of storage per record), int8 and float32 representations. The API documentation says you can request up to 3072.
The dimensions of our embeddings are ordered by relevance. For any integer target dimension n, you can choose to keep the first n dimensions for a smooth trade-off between quality and cost.
I think that means they're using Matryoshka embeddings.
Here's the problem: the benchmarks look great, but the model is only available via their API (or for on-prem deployments at "contact us" prices).
I'm perfectly happy to pay for API access to an embedding model like this, but I only want to do that if the model itself is also open weights so I can maintain the option to run it myself in the future if I ever need to.
The reason is that the embeddings I retrieve from this API only maintain their value if I can continue to calculate more of them in the future. If I'm going to spend money on calculating and storing embeddings I want to know that value is guaranteed far into the future.
If the only way to get new embeddings is via an API, and Mistral shut down that API (or go out of business), that investment I've made in the embeddings I've stored collapses in an instant.
I don't actually want to run the model myself. Paying Mistral $0.15 per million tokens (50% off for batch discounts) to not have to waste my own server's RAM and GPU holding that model in memory is great deal!
In this case, open weights is a feature I want purely because it gives me complete confidence in the future of my investment.
I wonder if one of the reasons I'm finding LLMs so much more useful for coding than a lot of people that I see in online discussions is that effectively all of the code I work on has automated tests.
I've been trying to stay true to the idea of a Perfect Commit - one that bundles the implementation, tests and documentation in a single unit - for over five years now. As a result almost every piece of (non vibe-coding) code I work on has pretty comprehensive test coverage.
This massively derisks my use of LLMs. If an LLM writes weird, convoluted code that solves my problem I can prove that it works with tests - and then have it refactor the code until it looks good to me, keeping the tests green the whole time.
LLMs help write the tests, too. I finally have a 24/7 pair programmer who can remember how to use unittest.mock!
Next time someone complains that they've found LLMs to be more of a hindrance than a help in their programming work, I'm going to try to remember to ask after the health of their test suite.