Friday, 28th February 2025
Structured data extraction from unstructured content using LLM schemas
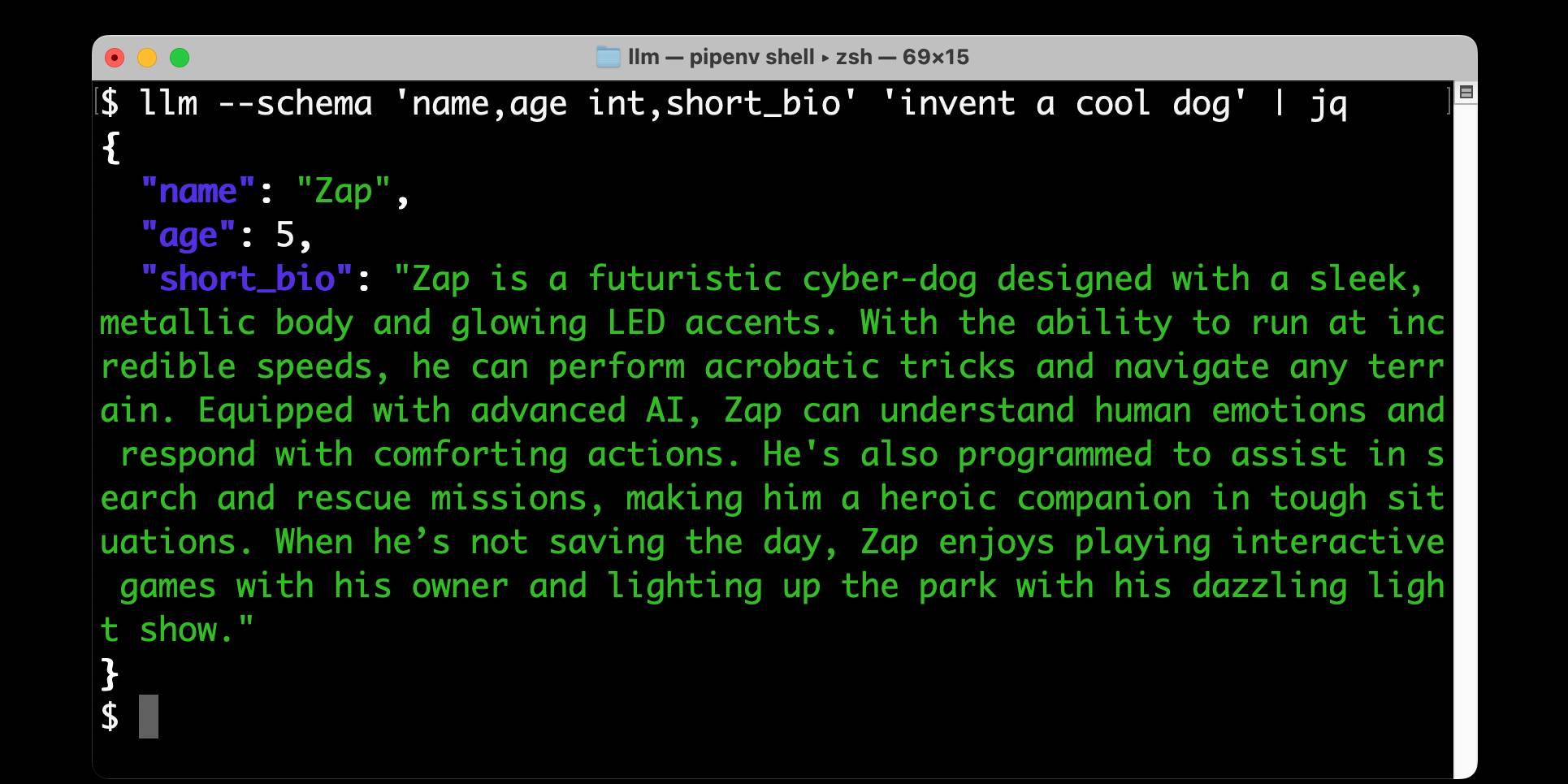
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]For some time, I’ve argued that a common conception of AI is misguided. This is the idea that AI systems like large language and vision models are individual intelligent agents, analogous to human agents. Instead, I’ve argued that these models are “cultural technologies” like writing, print, pictures, libraries, internet search engines, and Wikipedia. Cultural technologies allow humans to access the information that other humans have created in an effective and wide-ranging way, and they play an important role in increasing human capacities.
— Alison Gopnik, in Stone Soup AI
strip-tags 0.6. It's been a while since I updated this tool, but in investigating a tricky mistake in my tutorial for LLM schemas I discovered a bug that I needed to fix.
Those release notes in full:
- Fixed a bug where
strip-tags -t metastill removed<meta>tags from the<head>because the entire<head>element was removed first. #32- Kept
<meta>tags now default to keeping theircontentandpropertyattributes.- The CLI
-m/--minifyoption now also removes any remaining blank lines. #33- A new
strip_tags(remove_blank_lines=True)option can be used to achieve the same thing with the Python library function.
Now I can do this and persist the <meta> tags for the article along with the stripped text content:
curl -s 'https://apnews.com/article/trump-federal-employees-firings-a85d1aaf1088e050d39dcf7e3664bb9f' | \
strip-tags -t meta --minify
Here's the output from that command.