Thursday, 17th October 2024
Gemini API Additional Terms of Service. I've been trying to figure out what Google's policy is on using data submitted to their Google Gemini LLM for further training. It turns out it's clearly spelled out in their terms of service, but it differs for the paid v.s. free tiers.
The paid APIs do not train on your inputs:
When you're using Paid Services, Google doesn't use your prompts (including associated system instructions, cached content, and files such as images, videos, or documents) or responses to improve our products [...] This data may be stored transiently or cached in any country in which Google or its agents maintain facilities.
The Gemini API free tier does:
The terms in this section apply solely to your use of Unpaid Services. [...] Google uses this data, consistent with our Privacy Policy, to provide, improve, and develop Google products and services and machine learning technologies, including Google’s enterprise features, products, and services. To help with quality and improve our products, human reviewers may read, annotate, and process your API input and output.
But watch out! It looks like the AI Studio tool, since it's offered for free (even if you have a paid account setup) is treated as "free" for the purposes of these terms. There's also an interesting note about the EU:
The terms in this "Paid Services" section apply solely to your use of paid Services ("Paid Services"), as opposed to any Services that are offered free of charge like direct interactions with Google AI Studio or unpaid quota in Gemini API ("Unpaid Services"). [...] If you're in the European Economic Area, Switzerland, or the United Kingdom, the terms applicable to Paid Services apply to all Services including AI Studio even though it's offered free of charge.
Confusingly, the following paragraph about data used to fine-tune your own custom models appears in that same "Data Use for Unpaid Services" section:
Google only uses content that you import or upload to our model tuning feature for that express purpose. Tuning content may be retained in connection with your tuned models for purposes of re-tuning when supported models change. When you delete a tuned model, the related tuning content is also deleted.
It turns out their tuning service is "free of charge" on both pay-as-you-go and free plans according to the Gemini pricing page, though you still pay for input/output tokens at inference time (on the paid tier - it looks like the free tier remains free even for those fine-tuned models).
Video scraping: extracting JSON data from a 35 second screen capture for less than 1/10th of a cent
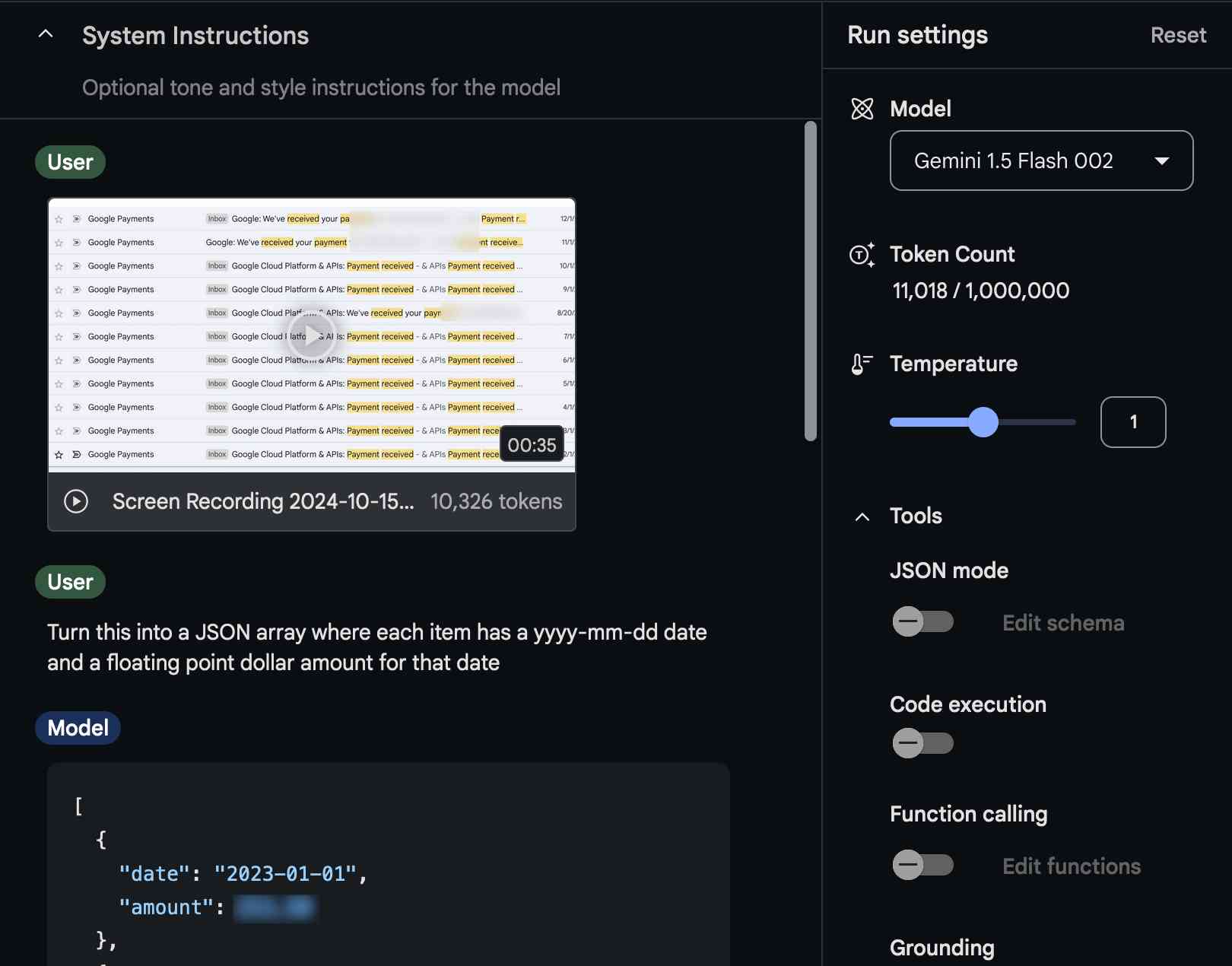
The other day I found myself needing to add up some numeric values that were scattered across twelve different emails.
[... 1,294 words]New in NotebookLM: Customizing your Audio Overviews. The most requested feature for Google's NotebookLM "audio overviews" (aka automatically generated podcast conversations) has been the ability to provide direction to those artificial podcast hosts - setting their expertise level or asking them to focus on specific topics.
Today's update adds exactly that:
Now you can provide instructions before you generate a "Deep Dive" Audio Overview. For example, you can focus on specific topics or adjust the expertise level to suit your audience. Think of it like slipping the AI hosts a quick note right before they go on the air, which will change how they cover your material.
I pasted in a link to my post about video scraping and prompted it like this:
You are both pelicans who work as data journalist at a pelican news service. Discuss this from the perspective of pelican data journalists, being sure to inject as many pelican related anecdotes as possible
Here's the resulting 7m40s MP3, and the transcript.
It starts off strong!
You ever find yourself wading through mountains of data trying to pluck out the juicy bits? It's like hunting for a single shrimp in a whole kelp forest, am I right?
Then later:
Think of those facial recognition systems they have for humans. We could have something similar for our finned friends. Although, gotta say, the ethical implications of that kind of tech are a whole other kettle of fish. We pelicans gotta use these tools responsibly and be transparent about it.
And when brainstorming some potential use-cases:
Imagine a pelican citizen journalist being able to analyze footage of a local council meeting, you know, really hold those pelicans in power accountable, or a pelican historian using video scraping to analyze old film reels, uncovering lost details about our pelican ancestors.
Plus this delightful conclusion:
The future of data journalism is looking brighter than a school of silversides reflecting the morning sun. Until next time, keep those wings spread, those eyes sharp, and those minds open. There's a whole ocean of data out there just waiting to be explored.
And yes, people on Reddit have got them to swear.
Using static websites for tiny archives (via) Alex Chan:
Over the last year or so, I’ve been creating static websites to browse my local archives. I’ve done this for a variety of collections, including:
- paperwork I’ve scanned
- documents I’ve created
- screenshots I’ve taken
- web pages I’ve bookmarked
- video and audio files I’ve saved
This is such a neat idea. These tiny little personal archive websites aren't even served through a localhost web server - they exist as folders on disk, and Alex browses them by opening up the index.html file directly in a browser.