12 posts tagged “google-io”
2025
Gemini Diffusion. Another of the announcements from Google I/O yesterday was Gemini Diffusion, Google's first LLM to use diffusion (similar to image models like Imagen and Stable Diffusion) in place of transformers.
Google describe it like this:
Traditional autoregressive language models generate text one word – or token – at a time. This sequential process can be slow, and limit the quality and coherence of the output.
Diffusion models work differently. Instead of predicting text directly, they learn to generate outputs by refining noise, step-by-step. This means they can iterate on a solution very quickly and error correct during the generation process. This helps them excel at tasks like editing, including in the context of math and code.
The key feature then is speed. I made it through the waitlist and tried it out just now and wow, they are not kidding about it being fast.
In this video I prompt it with "Build a simulated chat app" and it responds at 857 tokens/second, resulting in an interactive HTML+JavaScript page (embedded in the chat tool, Claude Artifacts style) within single digit seconds.
The performance feels similar to the Cerebras Coder tool, which used Cerebras to run Llama3.1-70b at around 2,000 tokens/second.
How good is the model? I've not seen any independent benchmarks yet, but Google's landing page for it promises "the performance of Gemini 2.0 Flash-Lite at 5x the speed" so presumably they think it's comparable to Gemini 2.0 Flash-Lite, one of their least expensive models.
Prior to this the only commercial grade diffusion model I've encountered is Inception Mercury back in February this year.
Update: a correction from synapsomorphy on Hacker News:
Diffusion isn't in place of transformers, it's in place of autoregression. Prior diffusion LLMs like Mercury still use a transformer, but there's no causal masking, so the entire input is processed all at once and the output generation is obviously different. I very strongly suspect this is also using a transformer.
nvtop provided this explanation:
Despite the name, diffusion LMs have little to do with image diffusion and are much closer to BERT and old good masked language modeling. Recall how BERT is trained:
- Take a full sentence ("the cat sat on the mat")
- Replace 15% of tokens with a [MASK] token ("the cat [MASK] on [MASK] mat")
- Make the Transformer predict tokens at masked positions. It does it in parallel, via a single inference step.
Now, diffusion LMs take this idea further. BERT can recover 15% of masked tokens ("noise"), but why stop here. Let's train a model to recover texts with 30%, 50%, 90%, 100% of masked tokens.
Once you've trained that, in order to generate something from scratch, you start by feeding the model all [MASK]s. It will generate you mostly gibberish, but you can take some tokens (let's say, 10%) at random positions and assume that these tokens are generated ("final"). Next, you run another iteration of inference, this time input having 90% of masks and 10% of "final" tokens. Again, you mark 10% of new tokens as final. Continue, and in 10 steps you'll have generated a whole sequence. This is a core idea behind diffusion language models. [...]
Gemini 2.5: Our most intelligent models are getting even better. A bunch of new Gemini 2.5 announcements at Google I/O today.
2.5 Flash and 2.5 Pro are both getting audio output (previously previewed in Gemini 2.0) and 2.5 Pro is getting an enhanced reasoning mode called "Deep Think" - not yet available via the API.
Available today is the latest Gemini 2.5 Flash model, gemini-2.5-flash-preview-05-20. I added support to that in llm-gemini 0.20 (and, if you're using the LLM tool-use alpha, llm-gemini 0.20a2).
I tried it out on my personal benchmark, as seen in the Google I/O keynote!
llm -m gemini-2.5-flash-preview-05-20 'Generate an SVG of a pelican riding a bicycle'
Here's what I got from the default model, with its thinking mode enabled:
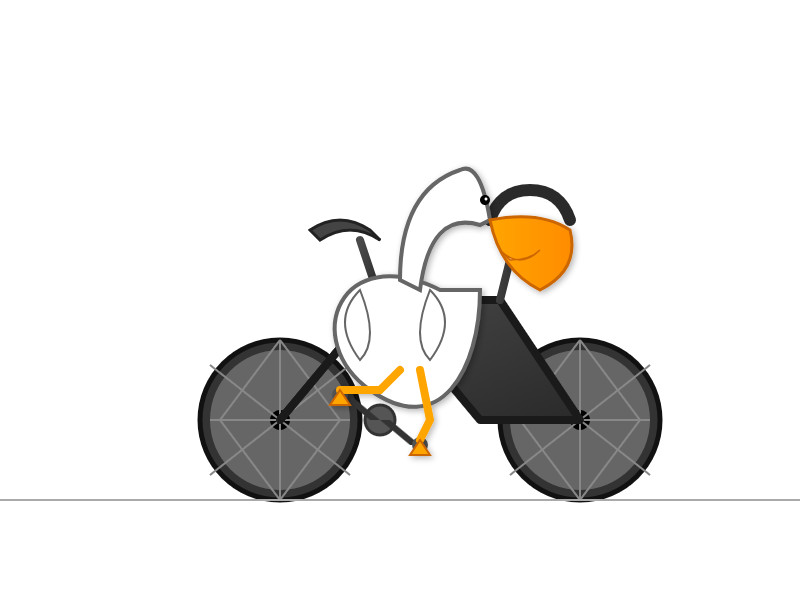
Full transcript. 11 input tokens, 2,619 output tokens, 10,391 thinking tokens = 4.5537 cents.
I ran the same thing again with -o thinking_budget 0 to turn off thinking mode entirely, and got this:

Full transcript. 11 input, 1,243 output = 0.0747 cents.
The non-thinking model is priced differently - still $0.15/million for input but $0.60/million for output as opposed to $3.50/million for thinking+output. The pelican it drew was 61x cheaper!
Finally, inspired by the keynote I ran this follow-up prompt to animate the more expensive pelican:
llm --cid 01jvqjqz9aha979yemcp7a4885 'Now animate it'
This one is pretty great!

Tucked into today's Google I/O keynote, a blink-and-you'll miss it moment:
The pelican in the keynote was created by Alexander Chen. Here's the code they wrote with the help of Gemini, which uses p5.js to power the animation.
2024
But where the company once limited itself to gathering low-hanging fruit along the lines of “what time is the super bowl,” on Tuesday executives showcased generative AI tools that will someday plan an entire anniversary dinner, or cross-country-move, or trip abroad. A quarter-century into its existence, a company that once proudly served as an entry point to a web that it nourished with traffic and advertising revenue has begun to abstract that all away into an input for its large language models.
PaliGemma model README (via) One of the more over-looked announcements from Google I/O yesterday was PaliGemma, an openly licensed VLM (Vision Language Model) in the Gemma family of models.
The model accepts an image and a text prompt. It outputs text, but that text can include special tokens representing regions on the image. This means it can return both bounding boxes and fuzzier segment outlines of detected objects, behavior that can be triggered using a prompt such as "segment puffins".
From the README:
PaliGemma uses the Gemma tokenizer with 256,000 tokens, but we further extend its vocabulary with 1024 entries that represent coordinates in normalized image-space (
<loc0000>...<loc1023>), and another with 128 entries (<seg000>...<seg127>) that are codewords used by a lightweight referring-expression segmentation vector-quantized variational auto-encoder (VQ-VAE) [...]
You can try it out on Hugging Face.
It's a 3B model, making it feasible to run on consumer hardware.
llm-gemini 0.1a4.
A new release of my llm-gemini plugin adding support for the Gemini 1.5 Flash model that was revealed this morning at Google I/O.
I'm excited about this new model because of its low price. Flash is $0.35 per 1 million tokens for prompts up to 128K token and $0.70 per 1 million tokens for longer prompts - up to a million tokens now and potentially two million at some point in the future. That's 1/10th of the price of Gemini Pro 1.5, cheaper than GPT 3.5 ($0.50/million) and only a little more expensive than Claude 3 Haiku ($0.25/million).
How developers are using Gemini 1.5 Pro’s 1 million token context window. I got to be a talking head for a few seconds in an intro video for today's Google I/O keynote, talking about how I used Gemini Pro 1.5 to index my bookshelf (and with a cameo from my squirrel nutcracker). I'm at 1m25s.
(Or at 10m6s in the full video of the keynote)
2022
Bringing page transitions to the web (via) Jake Archibald’s 13 minute Google I/O talk demonstrating the page transitions API that’s now available in Chrome Canary. This is a fascinating piece of API design—it works by effectively creating a static image screenshot of the before and after states of the transition, then letting you define CSS animations that animate a transition between the two static images. By default the screenshot encompasses the full viewport, but you can instead define multiple elements within the page and apply separate transitions to them. It’s only available for SPAs right now but the final design should include support for multi-page applications as well—which means transitions with no JavaScript needed at all!
2014
Aside from Google I/O, does Google organize any other conferences?
They run a whole bunch, but many of them aren’t widely advertised—they have a lot of invite-only events for customers of their advertising tools, for example, and there are things like the Google Analytics Summit.
[... 95 words]2013
What’s it like being an attendee at Google I/O?
It’s a fantastic opportunity to spend quality time with the Google employees who built the APIs you build software on top of—the core Android team, the Google Maps people, the Chrome engineers etc. it’s kind of like Apple’s WWDC in that regard—short of going to work for Google there is no better way to meet and interrogate that many expert Google engineers in one place.
[... 84 words]What has Google given out at I/O in the past years?
I/O 2013 was a Chromebook Pixel (with or without LTE) and 1 terabyte of Google Drive space for three years.
[... 37 words]2010
App Engine at Google I/O 2010. OpenID and OAuth are now baked in to the AppEngine users API. They’re also demoing two very exciting new features—a mapper API for doing map/reduce style queries against the data store, and a Channel API for building comet applications.