6 posts tagged “artificial-analysis”
Artificial Analysis is an independent AI benchmarking and analysis company.
2025
Kimi K2 Thinking. Chinese AI lab Moonshot's Kimi K2 established itself as one of the largest open weight models - 1 trillion parameters - back in July. They've now released the Thinking version, also a trillion parameters (MoE, 32B active) and also under their custom modified (so not quite open source) MIT license.
Starting with Kimi K2, we built it as a thinking agent that reasons step-by-step while dynamically invoking tools. It sets a new state-of-the-art on Humanity's Last Exam (HLE), BrowseComp, and other benchmarks by dramatically scaling multi-step reasoning depth and maintaining stable tool-use across 200–300 sequential calls. At the same time, K2 Thinking is a native INT4 quantization model with 256k context window, achieving lossless reductions in inference latency and GPU memory usage.
This one is only 594GB on Hugging Face - Kimi K2 was 1.03TB - which I think is due to the new INT4 quantization. This makes the model both cheaper and faster to host.
So far the only people hosting it are Moonshot themselves. I tried it out both via their own API and via the OpenRouter proxy to it, via the llm-moonshot plugin (by NickMystic) and my llm-openrouter plugin respectively.
The buzz around this model so far is very positive. Could this be the first open weight model that's competitive with the latest from OpenAI and Anthropic, especially for long-running agentic tool call sequences?
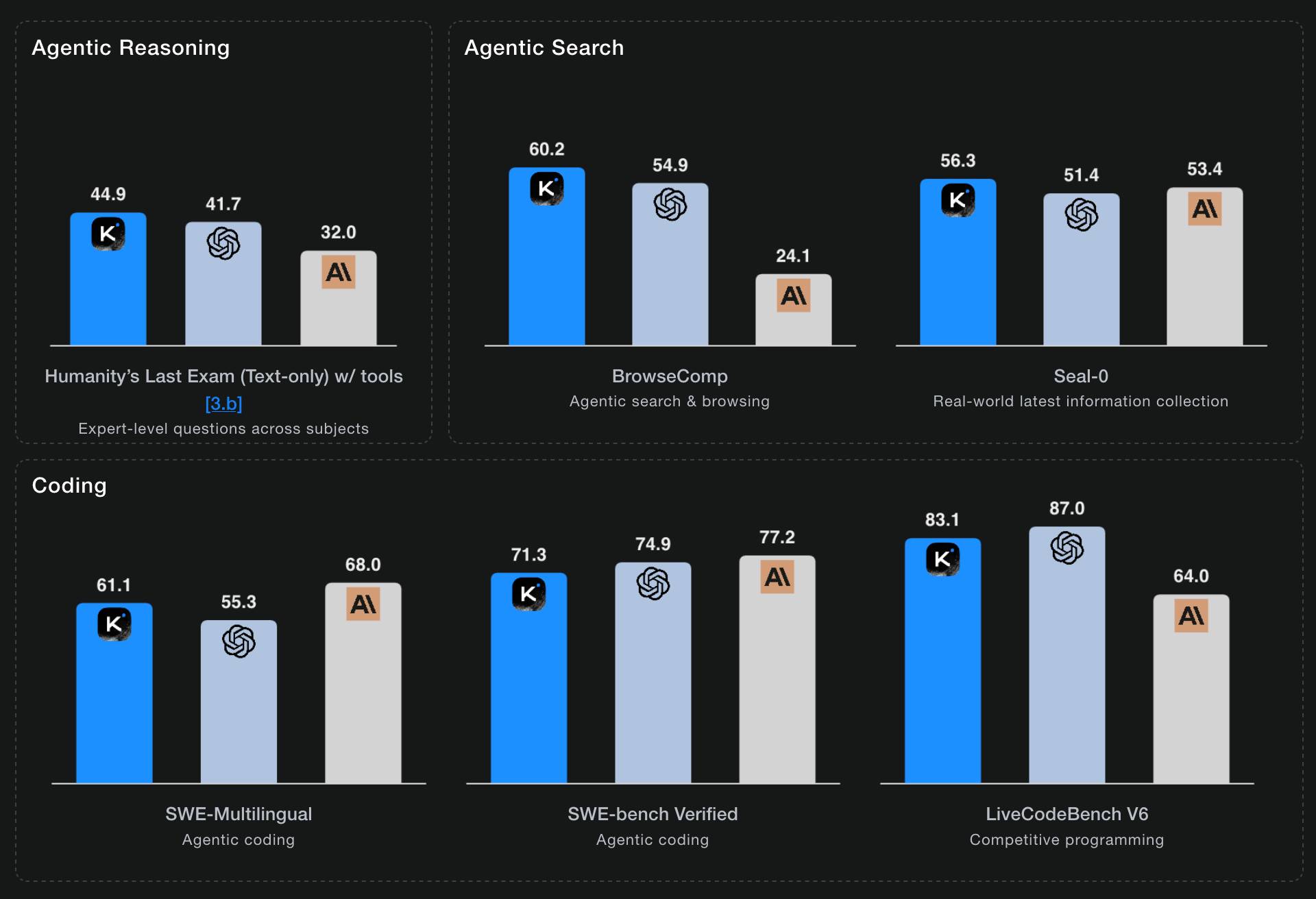
Moonshot AI's self-reported benchmark scores show K2 Thinking beating the top OpenAI and Anthropic models (GPT-5 and Sonnet 4.5 Thinking) at "Agentic Reasoning" and "Agentic Search" but not quite top for "Coding":
I ran a couple of pelican tests:
llm install llm-moonshot
llm keys set moonshot # paste key
llm -m moonshot/kimi-k2-thinking 'Generate an SVG of a pelican riding a bicycle'

llm install llm-openrouter
llm keys set openrouter # paste key
llm -m openrouter/moonshotai/kimi-k2-thinking \
'Generate an SVG of a pelican riding a bicycle'
Artificial Analysis said:
Kimi K2 Thinking achieves 93% in 𝜏²-Bench Telecom, an agentic tool use benchmark where the model acts as a customer service agent. This is the highest score we have independently measured. Tool use in long horizon agentic contexts was a strength of Kimi K2 Instruct and it appears this new Thinking variant makes substantial gains
CNBC quoted a source who provided the training price for the model:
The Kimi K2 Thinking model cost $4.6 million to train, according to a source familiar with the matter. [...] CNBC was unable to independently verify the DeepSeek or Kimi figures.
MLX developer Awni Hannun got it working on two 512GB M3 Ultra Mac Studios:
The new 1 Trillion parameter Kimi K2 Thinking model runs well on 2 M3 Ultras in its native format - no loss in quality!
The model was quantization aware trained (qat) at int4.
Here it generated ~3500 tokens at 15 toks/sec using pipeline-parallelism in mlx-lm
Here's the 658GB mlx-community model.
Improved Gemini 2.5 Flash and Flash-Lite (via) Two new preview models from Google - updates to their fast and inexpensive Flash and Flash Lite families:
The latest version of Gemini 2.5 Flash-Lite was trained and built based on three key themes:
- Better instruction following: The model is significantly better at following complex instructions and system prompts.
- Reduced verbosity: It now produces more concise answers, a key factor in reducing token costs and latency for high-throughput applications (see charts above).
- Stronger multimodal & translation capabilities: This update features more accurate audio transcription, better image understanding, and improved translation quality.
[...]
This latest 2.5 Flash model comes with improvements in two key areas we heard consistent feedback on:
- Better agentic tool use: We've improved how the model uses tools, leading to better performance in more complex, agentic and multi-step applications. This model shows noticeable improvements on key agentic benchmarks, including a 5% gain on SWE-Bench Verified, compared to our last release (48.9% → 54%).
- More efficient: With thinking on, the model is now significantly more cost-efficient—achieving higher quality outputs while using fewer tokens, reducing latency and cost (see charts above).
They also added two new convenience model IDs: gemini-flash-latest and gemini-flash-lite-latest, which will always resolve to the most recent model in that family.
I released llm-gemini 0.26 adding support for the new models and new aliases. I also used the response.set_resolved_model() method added in LLM 0.27 to ensure that the correct model ID would be recorded for those -latest uses.
llm install -U llm-gemini
Both of these models support optional reasoning tokens. I had them draw me pelicans riding bicycles in both thinking and non-thinking mode, using commands that looked like this:
llm -m gemini-2.5-flash-preview-09-2025 -o thinking_budget 4000 "Generate an SVG of a pelican riding a bicycle"
I then got each model to describe the image it had drawn using commands like this:
llm -a https://static.simonwillison.net/static/2025/gemini-2.5-flash-preview-09-2025-thinking.png -m gemini-2.5-flash-preview-09-2025 -o thinking_budget 2000 'Detailed single line alt text for this image'
gemini-2.5-flash-preview-09-2025-thinking

A minimalist stick figure graphic depicts a person with a white oval body and a dot head cycling a gray bicycle, carrying a large, bright yellow rectangular box resting high on their back.
gemini-2.5-flash-preview-09-2025
A simple cartoon drawing of a pelican riding a bicycle, with the text "A Pelican Riding a Bicycle" above it.
gemini-2.5-flash-lite-preview-09-2025-thinking

A quirky, simplified cartoon illustration of a white bird with a round body, black eye, and bright yellow beak, sitting astride a dark gray, two-wheeled vehicle with its peach-colored feet dangling below.
gemini-2.5-flash-lite-preview-09-2025

A minimalist, side-profile illustration of a stylized yellow chick or bird character riding a dark-wheeled vehicle on a green strip against a white background.
Artificial Analysis posted a detailed review, including these interesting notes about reasoning efficiency and speed:
- In reasoning mode, Gemini 2.5 Flash and Flash-Lite Preview 09-2025 are more token-efficient, using fewer output tokens than their predecessors to run the Artificial Analysis Intelligence Index. Gemini 2.5 Flash-Lite Preview 09-2025 uses 50% fewer output tokens than its predecessor, while Gemini 2.5 Flash Preview 09-2025 uses 24% fewer output tokens.
- Google Gemini 2.5 Flash-Lite Preview 09-2025 (Reasoning) is ~40% faster than the prior July release, delivering ~887 output tokens/s on Google AI Studio in our API endpoint performance benchmarking. This makes the new Gemini 2.5 Flash-Lite the fastest proprietary model we have benchmarked on the Artificial Analysis website
Open weight LLMs exhibit inconsistent performance across providers
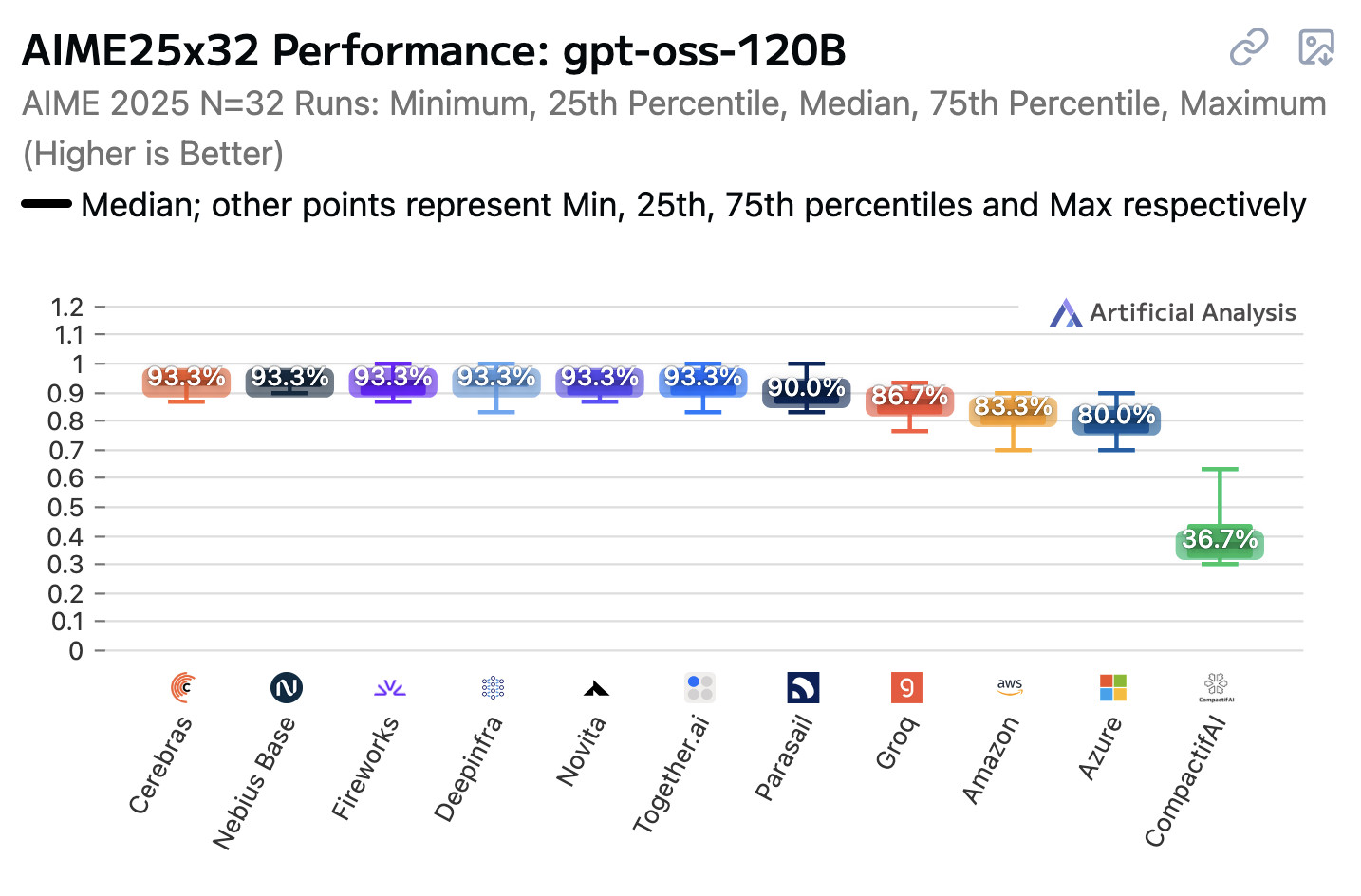
Artificial Analysis published a new benchmark the other day, this time focusing on how an individual model—OpenAI’s gpt-oss-120b—performs across different hosted providers.
[... 847 words]gpt-oss-120b is the most intelligent American open weights model, comes behind DeepSeek R1 and Qwen3 235B in intelligence but offers efficiency benefits [...]
We’re seeing the 120B beat o3-mini but come in behind o4-mini and o3. The 120B is the most intelligent model that can be run on a single H100 and the 20B is the most intelligent model that can be run on a consumer GPU. [...]
While the larger gpt-oss-120b does not come in above DeepSeek R1 0528’s score of 59 or Qwen3 235B 2507s score of 64, it is notable that it is significantly smaller in both total and active parameters than both of those models.
— Artificial Analysis, see also their updated leaderboard
Grok 4. Released last night, Grok 4 is now available via both API and a paid subscription for end-users.
Update: If you ask it about controversial topics it will sometimes search X for tweets "from:elonmusk"!
Key characteristics: image and text input, text output. 256,000 context length (twice that of Grok 3). It's a reasoning model where you can't see the reasoning tokens or turn off reasoning mode.
xAI released results showing Grok 4 beating other models on most of the significant benchmarks. I haven't been able to find their own written version of these (the launch was a livestream video) but here's a TechCrunch report that includes those scores. It's not clear to me if these benchmark results are for Grok 4 or Grok 4 Heavy.
I ran my own benchmark using Grok 4 via OpenRouter (since I have API keys there already).
llm -m openrouter/x-ai/grok-4 "Generate an SVG of a pelican riding a bicycle" \
-o max_tokens 10000

I then asked Grok to describe the image it had just created:
llm -m openrouter/x-ai/grok-4 -o max_tokens 10000 \
-a https://static.simonwillison.net/static/2025/grok4-pelican.png \
'describe this image'
Here's the result. It described it as a "cute, bird-like creature (resembling a duck, chick, or stylized bird)".
The most interesting independent analysis I've seen so far is this one from Artificial Analysis:
We have run our full suite of benchmarks and Grok 4 achieves an Artificial Analysis Intelligence Index of 73, ahead of OpenAI o3 at 70, Google Gemini 2.5 Pro at 70, Anthropic Claude 4 Opus at 64 and DeepSeek R1 0528 at 68.
The timing of the release is somewhat unfortunate, given that Grok 3 made headlines just this week after a clumsy system prompt update - presumably another attempt to make Grok "less woke" - caused it to start firing off antisemitic tropes and referring to itself as MechaHitler.
My best guess is that these lines in the prompt were the root of the problem:
- If the query requires analysis of current events, subjective claims, or statistics, conduct a deep analysis finding diverse sources representing all parties. Assume subjective viewpoints sourced from the media are biased. No need to repeat this to the user.
- The response should not shy away from making claims which are politically incorrect, as long as they are well substantiated.
If xAI expect developers to start building applications on top of Grok they need to do a lot better than this. Absurd self-inflicted mistakes like this do not build developer trust!
As it stands, Grok 4 isn't even accompanied by a model card.
Update: Ian Bicking makes an astute point:
It feels very credulous to ascribe what happened to a system prompt update. Other models can't be pushed into racism, Nazism, and ideating rape with a system prompt tweak.
Even if that system prompt change was responsible for unlocking this behavior, the fact that it was able to speaks to a much looser approach to model safety by xAI compared to other providers.
Update 12th July 2025: Grok posted a postmortem blaming the behavior on a different set of prompts, including "you are not afraid to offend people who are politically correct", that were not included in the system prompts they had published to their GitHub repository.
Grok 4 is competitively priced. It's $3/million for input tokens and $15/million for output tokens - the same price as Claude Sonnet 4. Once you go above 128,000 input tokens the price doubles to $6/$30 (Gemini 2.5 Pro has a similar price increase for longer inputs). I've added these prices to llm-prices.com.
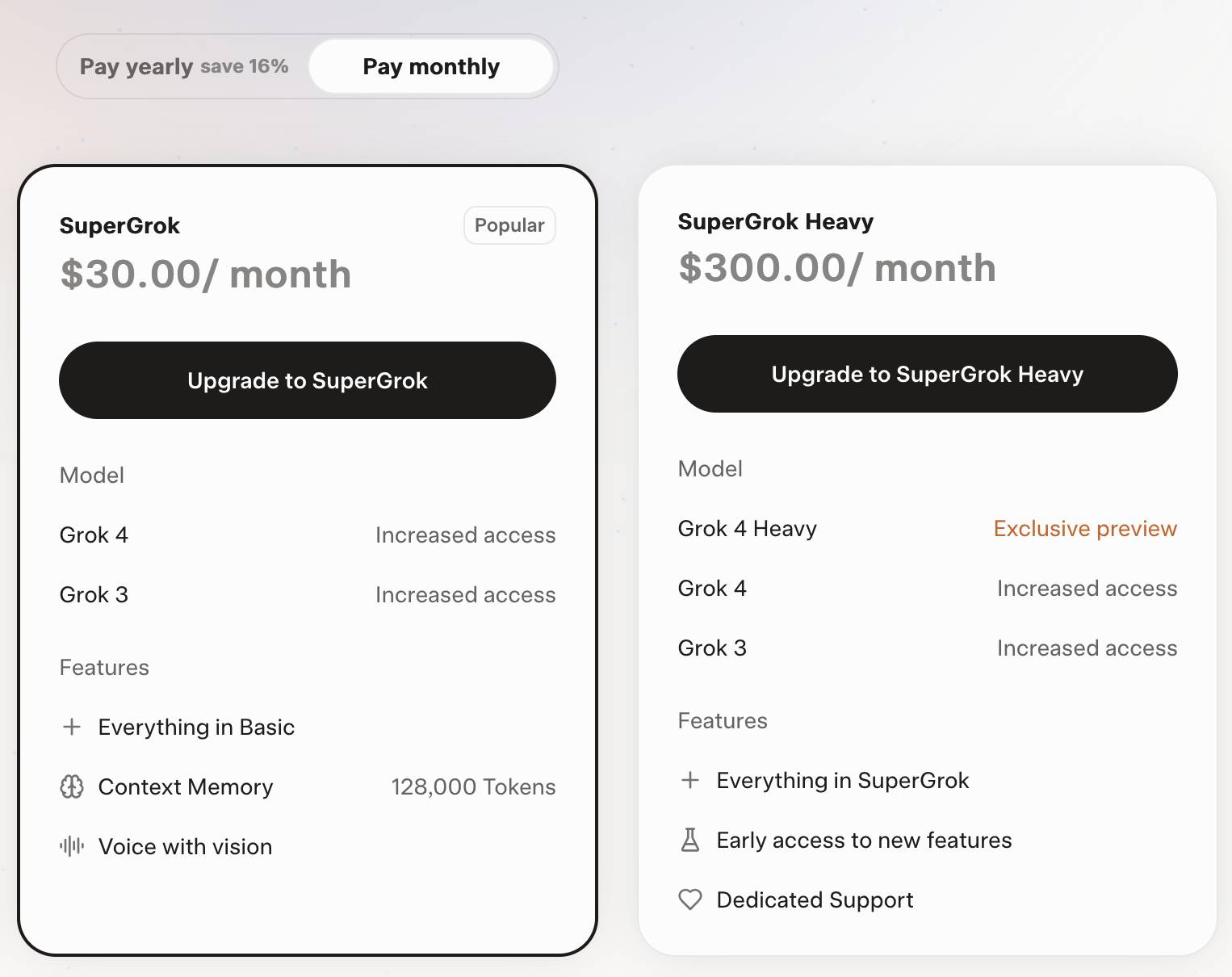
Consumers can access Grok 4 via a new $30/month or $300/year "SuperGrok" plan - or a $300/month or $3,000/year "SuperGrok Heavy" plan providing access to Grok 4 Heavy.
2024
Recraft V3. Recraft are a generative AI design tool startup based out of London who released their v3 model a few weeks ago. It's currently sat at the top of the Artificial Analysis Image Arena Leaderboard, beating Midjourney and Flux 1.1 pro.
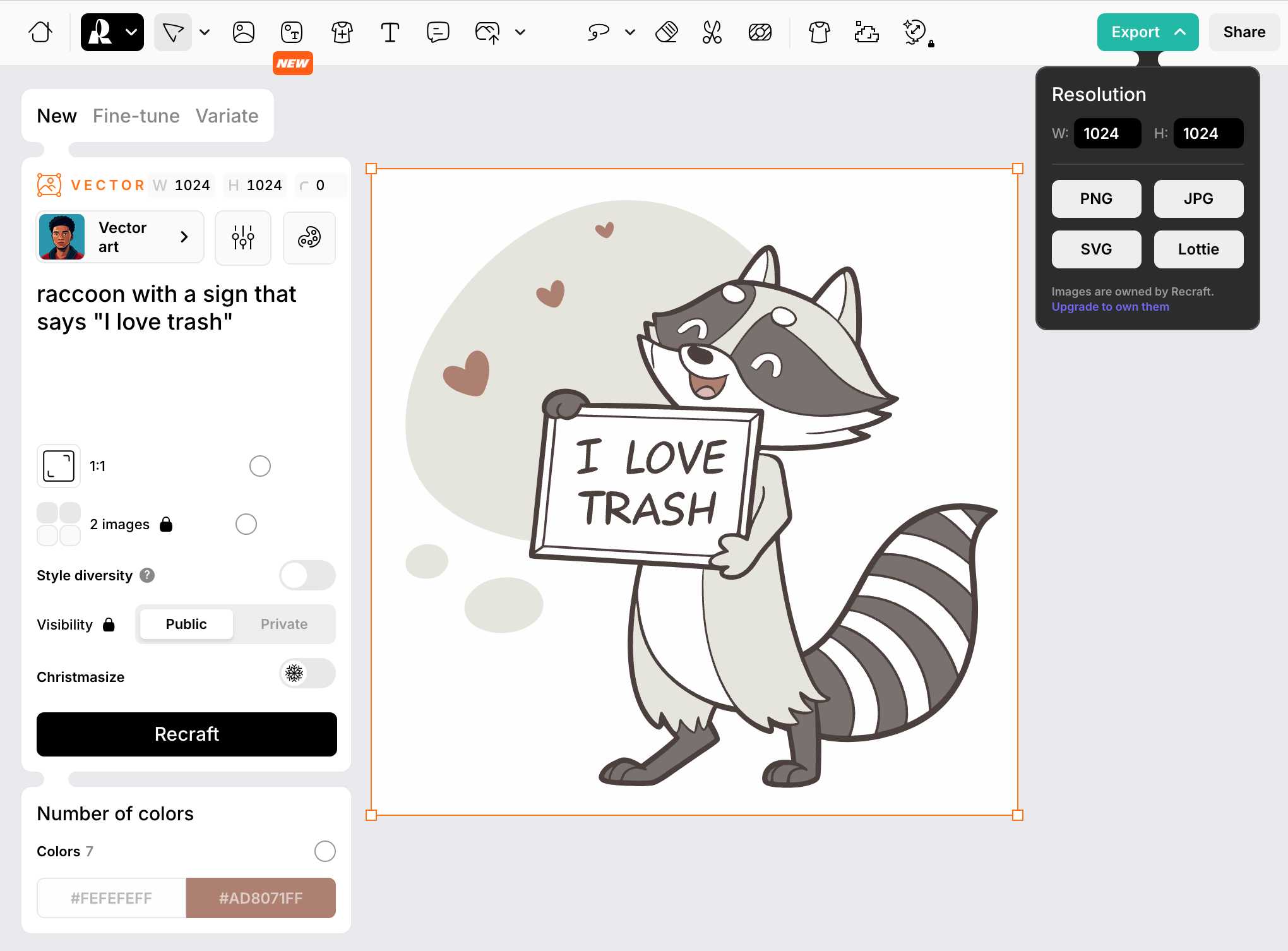
The thing that impressed me is that it can generate both raster and vector graphics... and the vector graphics can be exported as SVG!
Here's what I got for raccoon with a sign that says "I love trash" - SVG here.
{kind=link}
That's an editable SVG - when I open it up in Pixelmator I can select and modify the individual paths and shapes:
![]()
They also have an API. I spent $1 on 1000 credits and then spent 80 credits (8 cents) making this SVG of a pelican riding a bicycle, using my API key stored in 1Password:
export RECRAFT_API_TOKEN="$(
op item get recraft.ai --fields label=password \
--format json | jq .value -r)"
curl https://external.api.recraft.ai/v1/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $RECRAFT_API_TOKEN" \
-d '{
"prompt": "california brown pelican riding a bicycle",
"style": "vector_illustration",
"model": "recraftv3"
}'
