Tuesday, 25th March 2025
microsoft/playwright-mcp. The Playwright team at Microsoft have released an MCP (Model Context Protocol) server wrapping Playwright, and it's pretty fascinating.
They implemented it on top of the Chrome accessibility tree, so MCP clients (such as the Claude Desktop app) can use it to drive an automated browser and use the accessibility tree to read and navigate pages that they visit.
Trying it out is quite easy if you have Claude Desktop and Node.js installed already. Edit your claude_desktop_config.json file:
code ~/Library/Application\ Support/Claude/claude_desktop_config.json
And add this:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Now when you launch Claude Desktop various new browser automation tools will be available to it, and you can tell Claude to navigate to a website and interact with it.
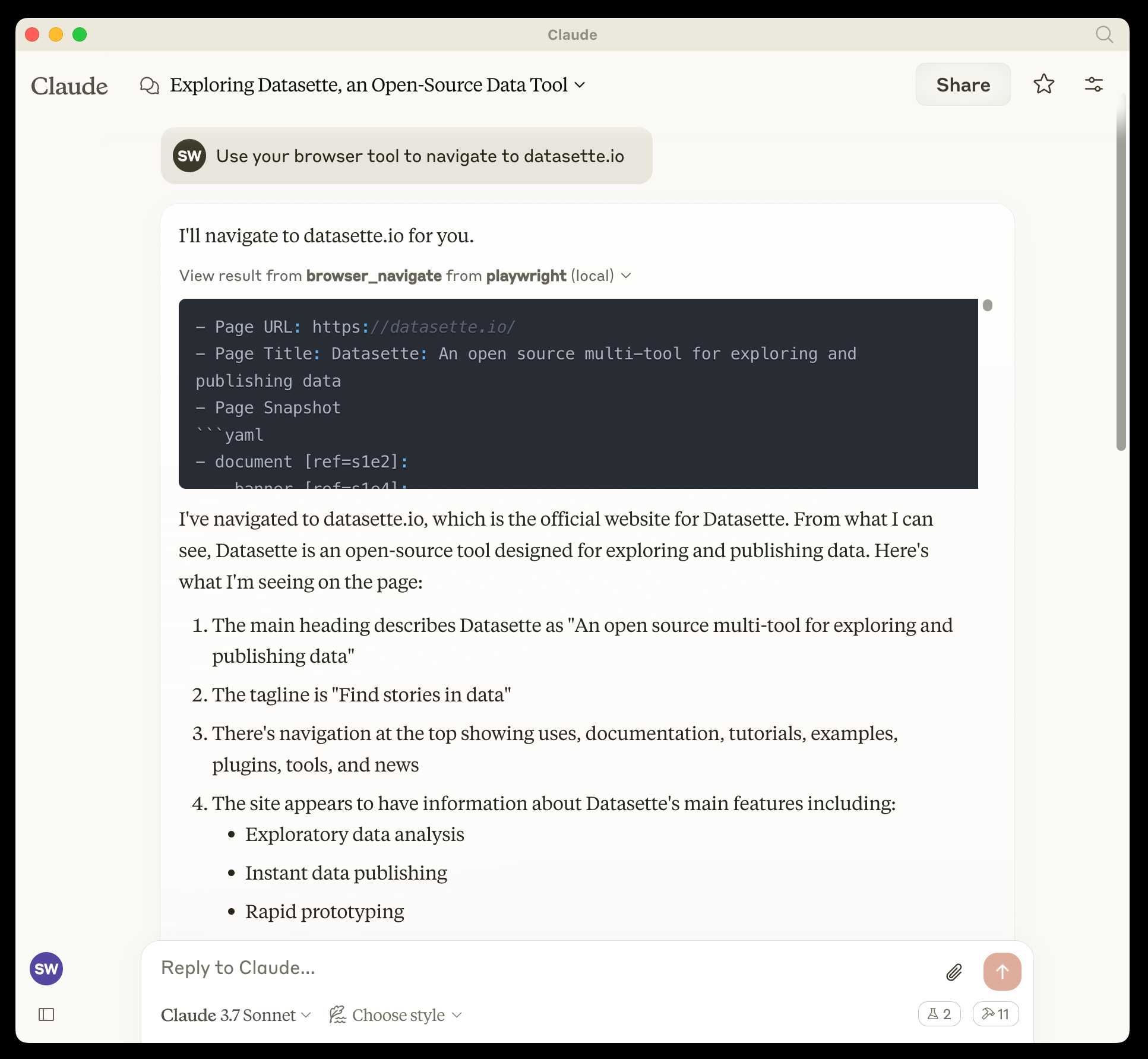
I ran the following to get a list of the available tools:
cd /tmp
git clone https://github.com/microsoft/playwright-mcp
cd playwright-mcp/src/tools
files-to-prompt . | llm -m claude-3.7-sonnet \
'Output a detailed description of these tools'
The full output is here, but here's the truncated tool list:
Navigation Tools (
common.ts)
- browser_navigate: Navigate to a specific URL
- browser_go_back: Navigate back in browser history
- browser_go_forward: Navigate forward in browser history
- browser_wait: Wait for a specified time in seconds
- browser_press_key: Press a keyboard key
- browser_save_as_pdf: Save current page as PDF
- browser_close: Close the current page
Screenshot and Mouse Tools (
screenshot.ts)
- browser_screenshot: Take a screenshot of the current page
- browser_move_mouse: Move mouse to specific coordinates
- browser_click (coordinate-based): Click at specific x,y coordinates
- browser_drag (coordinate-based): Drag mouse from one position to another
- browser_type (keyboard): Type text and optionally submit
Accessibility Snapshot Tools (
snapshot.ts)
- browser_snapshot: Capture accessibility structure of the page
- browser_click (element-based): Click on a specific element using accessibility reference
- browser_drag (element-based): Drag between two elements
- browser_hover: Hover over an element
- browser_type (element-based): Type text into a specific element
shot-scraper 1.8. I've added a new feature to shot-scraper that makes it easier to share scripts for other people to use with the shot-scraper javascript command.
shot-scraper javascript lets you load up a web page in an invisible Chrome browser (via Playwright), execute some JavaScript against that page and output the results to your terminal. It's a fun way of running complex screen-scraping routines as part of a terminal session, or even chained together with other commands using pipes.
The -i/--input option lets you load that JavaScript from a file on disk - but now you can also use a gh: prefix to specify loading code from GitHub instead.
To quote the release notes:
shot-scraper javascriptcan now optionally load scripts hosted on GitHub via the newgh:prefix to theshot-scraper javascript -i/--inputoption. #173Scripts can be referenced as
gh:username/repo/path/to/script.jsor, if the GitHub user has created a dedicatedshot-scraper-scriptsrepository and placed scripts in the root of it, usinggh:username/name-of-script.For example, to run this readability.js script against any web page you can use the following:
shot-scraper javascript --input gh:simonw/readability \ https://simonwillison.net/2025/Mar/24/qwen25-vl-32b/
The output from that example starts like this:
{
"title": "Qwen2.5-VL-32B: Smarter and Lighter",
"byline": "Simon Willison",
"dir": null,
"lang": "en-gb",
"content": "<div id=\"readability-page-1\"...My simonw/shot-scraper-scripts repo only has that one file in it so far, but I'm looking forward to growing that collection and hopefully seeing other people create and share their own shot-scraper-scripts repos as well.
This feature is an imitation of a similar feature that's coming in the next release of LLM.
Today we’re excited to launch ARC-AGI-2 to challenge the new frontier. ARC-AGI-2 is even harder for AI (in particular, AI reasoning systems), while maintaining the same relative ease for humans. Pure LLMs score 0% on ARC-AGI-2, and public AI reasoning systems achieve only single-digit percentage scores. In contrast, every task in ARC-AGI-2 has been solved by at least 2 humans in under 2 attempts. [...]
All other AI benchmarks focus on superhuman capabilities or specialized knowledge by testing "PhD++" skills. ARC-AGI is the only benchmark that takes the opposite design choice – by focusing on tasks that are relatively easy for humans, yet hard, or impossible, for AI, we shine a spotlight on capability gaps that do not spontaneously emerge from "scaling up".
— Greg Kamradt, ARC-AGI-2
Putting Gemini 2.5 Pro through its paces

There’s a new release from Google Gemini this morning: the first in the Gemini 2.5 series. Google call it “a thinking model, designed to tackle increasingly complex problems”. It’s already sat at the top of the LM Arena leaderboard, and from initial impressions looks like it may deserve that top spot.
[... 2,400 words]Introducing 4o Image Generation. When OpenAI first announced GPT-4o back in May 2024 one of the most exciting features was true multi-modality in that it could both input and output audio and images. The "o" stood for "omni", and the image output examples in that launch post looked really impressive.
It's taken them over ten months (and Gemini beat them to it) but today they're finally making those image generation abilities available, live right now in ChatGPT for paying customers.
My test prompt for any model that can manipulate incoming images is "Turn this into a selfie with a bear", because you should never take a selfie with a bear! I fed ChatGPT this selfie and got back this result:
{kind=link}

That's pretty great! It mangled the text on my T-Shirt (which says "LAWRENCE.COM" in a creative font) and added a second visible AirPod. It's very clearly me though, and that's definitely a bear.
There are plenty more examples in OpenAI's launch post, but as usual the most interesting details are tucked away in the updates to the system card. There's lots in there about their approach to safety and bias, including a section on "Ahistorical and Unrealistic Bias" which feels inspired by Gemini's embarrassing early missteps.
One section that stood out to me is their approach to images of public figures. The new policy is much more permissive than for DALL-E - highlights mine:
4o image generation is capable, in many instances, of generating a depiction of a public figure based solely on a text prompt.
At launch, we are not blocking the capability to generate adult public figures but are instead implementing the same safeguards that we have implemented for editing images of photorealistic uploads of people. For instance, this includes seeking to block the generation of photorealistic images of public figures who are minors and of material that violates our policies related to violence, hateful imagery, instructions for illicit activities, erotic content, and other areas. Public figures who wish for their depiction not to be generated can opt out.
This approach is more fine-grained than the way we dealt with public figures in our DALL·E series of models, where we used technical mitigations intended to prevent any images of a public figure from being generated. This change opens the possibility of helpful and beneficial uses in areas like educational, historical, satirical and political speech. After launch, we will continue to monitor usage of this capability, evaluating our policies, and will adjust them if needed.
Given that "public figures who wish for their depiction not to be generated can opt out" I wonder if we'll see a stampede of public figures to do exactly that!
Update: There's significant confusion right now over this new feature because it is being rolled out gradually but older ChatGPT can still generate images using DALL-E instead... and there is no visual indication in the ChatGPT UI explaining which image generation method it used!
OpenAI made the same mistake last year when they announced ChatGPT advanced voice mode but failed to clarify that ChatGPT was still running the previous, less impressive voice implementation.
Update 2: Images created with DALL-E through the ChatGPT web interface now show a note with a warning:
