Many options for running Mistral models in your terminal using LLM
18th December 2023
Mistral AI is the most exciting AI research lab at the moment. They’ve now released two extremely powerful smaller Large Language Models under an Apache 2 license, and have a third much larger one that’s available via their API.
I’ve been trying out their models using my LLM command-line tool tool. Here’s what I’ve figured out so far.
- Mixtral 8x7B via llama.cpp and llm-llama-cpp
- Mistral 7B via llm-llama-cpp or llm-gpt4all or llm-mlc
- Using the Mistral API, which includes the new Mistral-medium
- Mistral via other API providers
- Using Llamafile’s OpenAI API endpoint
Mixtral 8x7B via llama.cpp and llm-llama-cpp
On Friday 8th December Mistral AI tweeted a mysterious magnet (BitTorrent) link. This is the second time they’ve done this, the first was on September 26th when they released their excellent Mistral 7B model, also as a magnet link.
The new release was an 87GB file containing Mixtral 8x7B—“a high-quality sparse mixture of experts model (SMoE) with open weights”, according to the article they released three days later.
Mixtral is a very impressive model. GPT-4 has long been rumored to use a mixture of experts architecture, and Mixtral is the first truly convincing openly licensed implementation of this architecture I’ve seen. It’s already showing impressive benchmark scores.
This PR for llama.cpp added support for the new model. llama-cpp-python updated to land that patch shortly afterwards.
Which means... you can now run Mixtral on a Mac (and other platforms too, though I haven’t tested them myself yet) using my llm-llama-cpp plugin.
Here’s how to do that:
-
Install LLM:
pipx install llm
- Install the plugin:
llm install llm-llama-cpp
- Install
llama-cpp-python—this needs to be done manually because the best approach differs for different platforms. On an Apple Silicon Mac I recommend running:More details in the llm-llama-cpp READMECMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-python - Download a GGUF file for Mixtral 8X7B Instruct v0.1. TheBloke has 8 different options for this—I picked the 36GB
mixtral-8x7b-instruct-v0.1.Q6_K.gguf:curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' - Run the model like this:
llm -m gguf \ -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf \ '[INST] Write a Python function that downloads a file from a URL[/INST]'
The -m gguf here says to use the gguf model that was installed by the llm-llama-cpp plugin—this is a model which requires you to pass a path option—with -o path filename—specifying which model you would like to run.
The [INST] part there is the format of prompt expected by the Instruct model. I need to update the llm-llama-cpp plugin to make it easier to automatically construct the correct prompt format, see this issue.
Here’s what I got for that prompt:
Sure, here’s an example Python function that downloads a file from a URL using the
requestslibrary:import requests def download_file(url, save_path): """ Download a file from a URL and save it to a local path. :param url: The URL of the file to download. :param save_path: The local path to save the file. """ response = requests.get(url, stream=True) if response.status_code == 200: with open(save_path, 'wb') as f: for chunk in response.iter_content(1024): f.write(chunk) print(f"File downloaded successfully at {save_path}") else: print(f"Failed to download file from {url}. Status code: {response.status_code}")To use this function, simply call it with the URL of the file you want to download and the local path where you want to save it. For example:
download_file('https://example.com/myfile.txt', '/path/to/save/myfile.txt')Note that this function uses the
stream=Trueparameter in therequests.get()method to download the file in chunks, which can help prevent memory issues when downloading large files. It also checks the HTTP status code of the response before saving the file, so you can handle any errors that might occur during the download.
That’s a very solid reply!
Mistral 7B via llm-llama-cpp or llm-gpt4all or llm-mlc
The smaller Mistral 7B model dropped back in September. It’s since established itself as the most capable model family of that size—a size which is very convenient for running on personal devices.
I’m even running Mistral 7B on my iPhone now, thanks to an update to the MLC Chat iOS app from a few days ago.
There are a bunch of different options for running this model and its variants locally using LLM on a Mac—and probably other platforms too, though I’ve not tested these options myself on Linux or Windows:
- Using llm-llama-cpp: download one of these Mistral-7B-Instruct GGUF files for the chat-tuned version, or one of these for base Mistral, then follow the steps listed above
- Using llm-gpt4all. This is the easiest plugin to install:
The model will be downloaded the first time you try to use it:
llm install llm-gpt4all
llm -m mistral-7b-instruct-v0 'Introduce yourself' - Using llm-mlc. Follow the instructions in the README to install it, then:
# Download the model: llm mlc download-model https://huggingface.co/mlc-ai/mlc-chat-Mistral-7B-Instruct-v0.2-q3f16_1 # Run it like this: llm -m mlc-chat-Mistral-7B-Instruct-v0.2-q3f16_1 'Introduce yourself'
Each of these options work, but I’ve not spent time yet comparing them in terms of output quality or performance.
Using the Mistral API, which includes the new Mistral-medium
Mistral also recently announced La plateforme, their early access API for calling hosted versions of their models.
Their new API renames Mistral 7B model “Mistral-tiny”, the new Mixtral model “Mistral-small”... and offers something called Mistral-medium as well:
Our highest-quality endpoint currently serves a prototype model, that is currently among the top serviced models available based on standard benchmarks. It masters English/French/Italian/German/Spanish and code and obtains a score of 8.6 on MT-Bench.
I got access to their API and used it to build a new plugin, llm-mistral. Here’s how to use that:
- Install it:
llm install llm-mistral
- Set your Mistral API key:
llm keys set mistral # <paste key here>
- Run the models like this:
llm -m mistral-tiny 'Say hi' # Or mistral-small or mistral-medium cat mycode.py | llm -m mistral-medium -s 'Explain this code'
Here’s their comparison table pitching Mistral Small and Medium against GPT-3.5:
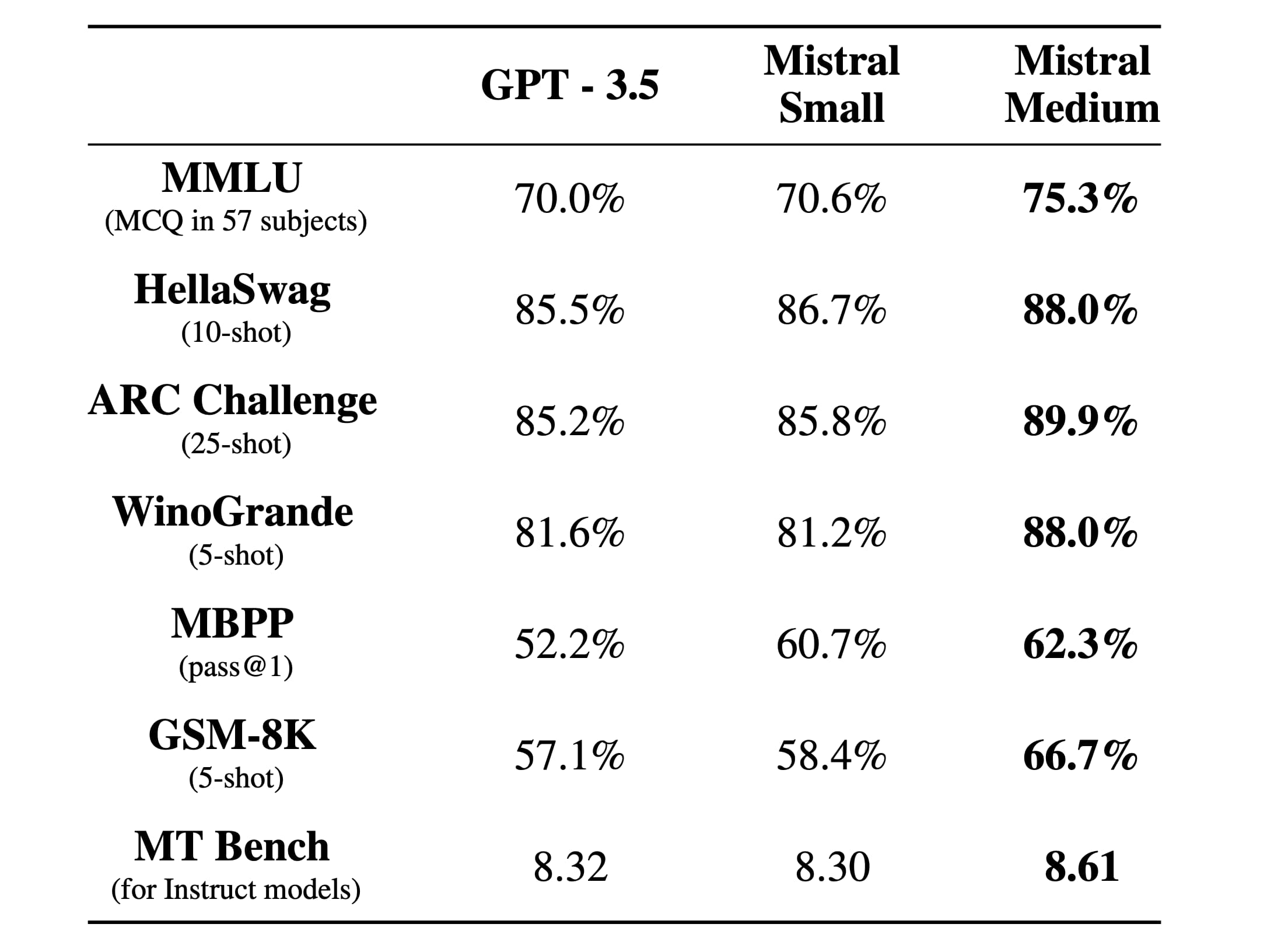
These may well be cherry-picked, but note that Small beats GPT-3.5 on almost every metric, and Medium beats it on everything by a wider margin.
Here’s the MT Bench leaderboard which includes scores for GPT-4 and Claude 2.1:
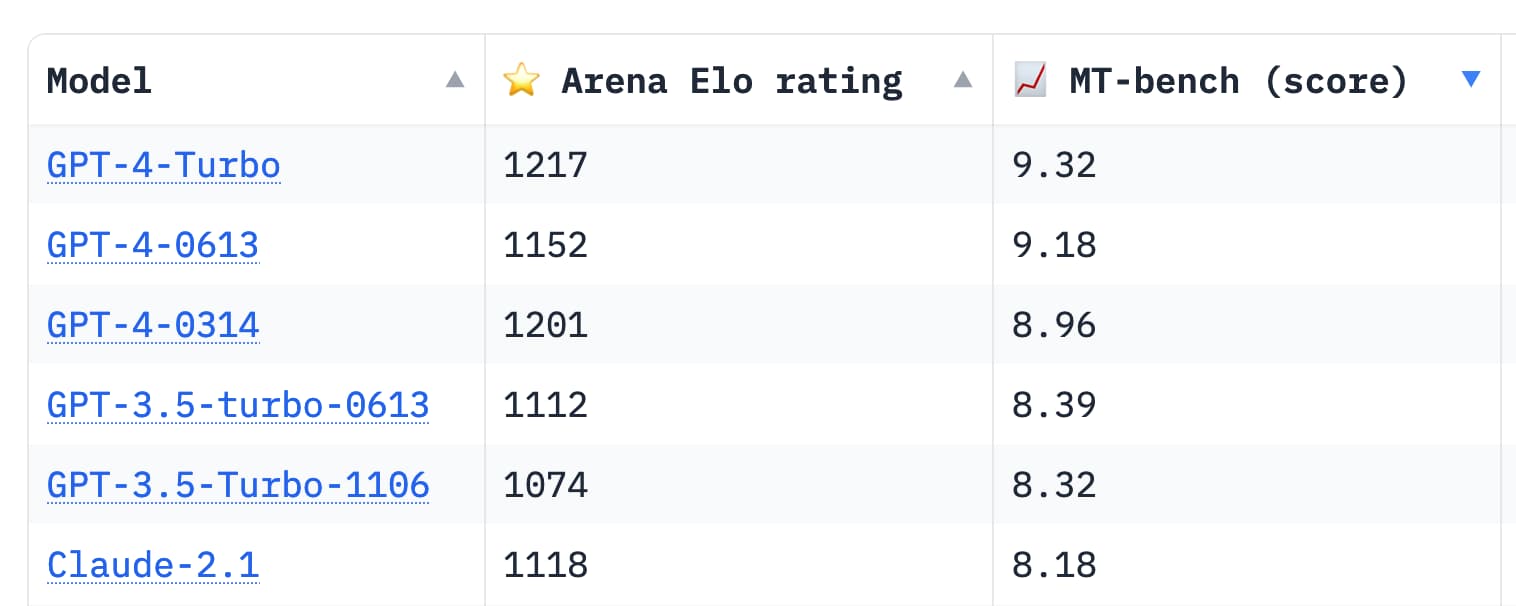
That 8.61 score for Medium puts it half way between GPT-3.5 and GPT-4.
Benchmark scores are no replacement for spending time with a model to get a feel for how well it behaves across a wide spectrum of tasks, but these scores are extremely promising. GPT-4 may not hold the best model crown for much longer.
Mistral via other API providers
Since both Mistral 7B and Mixtral 8x7B are available under an Apache 2 license, there’s been something of a race to the bottom in terms of pricing from other LLM hosting providers.
This trend makes me a little nervous, since it actively disincentivizes future open model releases from Mistral and from other providers who are hoping to offer their own hosted versions.
LLM has plugins for a bunch of these providers already. The three that I’ve tried so far are Replicate, Anyscale Endpoints and OpenRouter.
For Replicate using llm-replicate:
llm install llm-replicate
llm keys set replicate
# <paste API key here>
llm replicate add mistralai/mistral-7b-v0.1Then run prompts like this:
llm -m replicate-mistralai-mistral-7b-v0.1 '3 reasons to get a pet weasel:'This example is the non-instruct tuned model, so the prompt needs to be shaped such that the model can complete it.
For Anyscale Endpoints using llm-anyscale-endpoints:
llm install llm-anyscale-endpoints
llm keys set anyscale-endpoints
# <paste API key here>Now you can run both the 7B and the Mixtral 8x7B models:
llm -m mistralai/Mixtral-8x7B-Instruct-v0.1 \
'3 reasons to get a pet weasel'
llm -m mistralai/Mistral-7B-Instruct-v0.1 \
'3 reasons to get a pet weasel'And for OpenRouter using llm-openrouter:
llm install llm-openrouter
llm keys set openrouter
# <paste API key here>Then run the models like so:
llm -m openrouter/mistralai/mistral-7b-instruct \
'2 reasons to get a pet dragon'
llm -m openrouter/mistralai/mixtral-8x7b-instruct \
'2 reasons to get a pet dragon'OpenRouter are currently offering Mistral and Mixtral via their API for $0.00/1M input tokens—it’s free! Obviously not sustainable, so don’t rely on that continuing, but that does make them a great platform for running some initial experiments with these models.
Using Llamafile’s OpenAI API endpoint
I wrote about Llamafile recently, a fascinating option fur running LLMs where the LLM can be bundled up in an executable that includes everything needed to run it, on multiple platforms.
Justine Tunney released llamafiles for Mixtral a few days ago.
The mixtral-8x7b-instruct-v0.1.Q5_K_M-server.llamafile one runs an OpenAI-compatible API endpoints which LLM can talk to.
Here’s how to use that:
- Download the llamafile:
curl -LO https://huggingface.co/jartine/Mixtral-8x7B-v0.1.llamafile/resolve/main/mixtral-8x7b-instruct-v0.1.Q5_K_M-server.llamafile
- Start that running:
You may need to
./mixtral-8x7b-instruct-v0.1.Q5_K_M-server.llamafile
chmod 755 mixtral-8x7b-instruct-v0.1.Q5_K_M-server.llamafileit first, but I found I didn’t need to. - Configure LLM to know about that endpoint, by adding the following to a file at
~/Library/Application Support/io.datasette.llm/extra-openai-models.yaml:This registers a model called- model_id: llamafile model_name: llamafile api_base: "http://127.0.0.1:8080/v1"
llamafilewhich you can now call like this:llm -m llamafile 'Say hello to the world'
Setting up that llamafile alias means you’ll be able to use the same CLI invocation for any llamafile models you run on that default 8080 port.
The same exact approach should work for other model hosting options that provide an endpoint that imitates the OpenAI API.
This is LLM plugins working as intended
When I added plugin support to LLM this was exactly what I had in mind: I want it to be as easy as possible to add support for new models, both local and remotely hosted.
The LLM plugin directory lists 19 plugins in total now.
If you want to build your own plugin—for a locally hosted model or for one exposed via a remote API—the plugin author tutorial (plus reviewing code from the existing plugins) should hopefully provide everything you need.
You’re also welcome to join us in the #llm Discord channel to talk about your plans for your project.
More recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026